



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
.png)

.jpg)


TABLE OF CONTENT


.png)

AI readiness for data means your data management platform is structured, governed, and accessible enough for AI systems to reliably consume and act on it in production. The trade-off is straightforward: investing in AI-ready data requires upfront work in architecture and governance, but skipping it leads to unreliable outputs, slower deployments, and higher operational costs.
This article outlines seven structural signs your platform isn't AI-ready, what each one costs in production, and where to focus first.
The overload of tips and tricks when it comes to data and AI readiness is high often times. That's when listening to industry leaders makes it really easy. Modern Data 101 Community, hence, brings in leaders' insights to you.

Access the insights here.
More than 80% of AI projects fail, which is twice the rate of failure for non-AI IT projects. In most AI projects, there's a quiet conversation that doesn't make it into the case study. An engineer pulls up the source data and realises it's inconsistent across systems, missing half the context the model needs, and governed by nobody in particular. This leads to the project never quite working.
The problem is that data issues, which seemed manageable in a traditional analytics environment, become blockers the moment you introduce large language models, AI agents, or intelligent retrieval systems. Suddenly, gaps that never surfaced in a dashboard become critical failures in a production AI workflow.
.jpg)
[state-of-data-products]
Here are seven signs your organisation isn't fulfilling the criteria of AI-readiness for data yet.
AI systems consume data and then interpret it, and this interpretation depends heavily on context, which comes from metadata. So, if your data assets are missing the basics, AI tools have almost nothing to work from:
This matters especially for retrieval-augmented generation (RAG) architectures and enterprise semantic search systems, where the quality of retrieved context directly shapes the quality of AI output. Sparse metadata doesn't just slow down discovery; it introduces ambiguity that compounds downstream.
A simple way to gauge this: if a new engineer still needs to chase people to understand what a dataset means, where it came from, or whether it can be trusted, an AI system will struggle with the same gaps, only at a much larger scale.
.jpg)
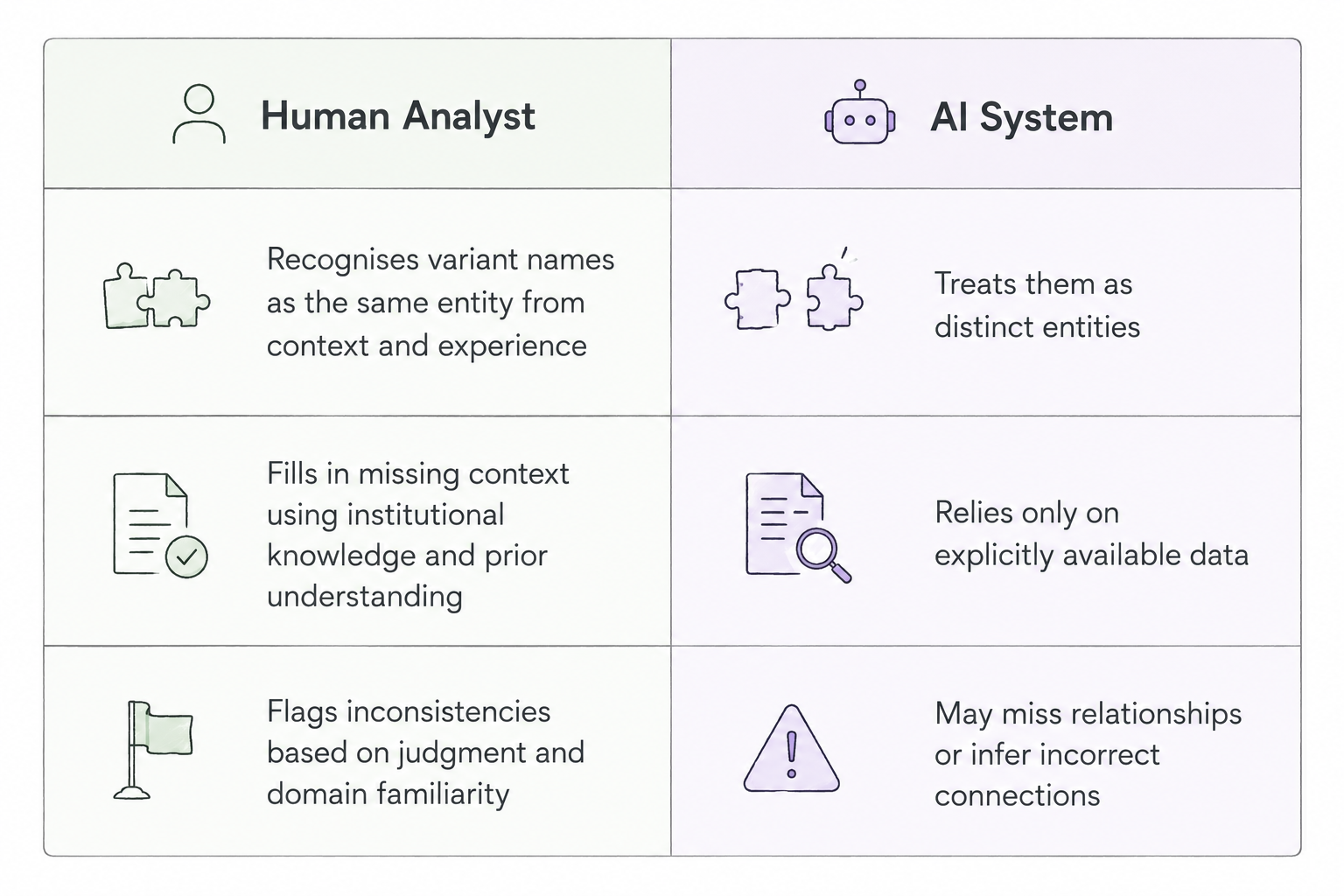
When an AI agent queries your supplier database and returns three different risk scores for the same company, it is treating three slightly different name strings as three distinct entities.
[related-1]
When AI agents or retrieval systems query across enterprise data sources, they assume a consistent representation of real-world entities: customers, suppliers, products, and contracts. Without it, they either miss connections that should be obvious or they fabricate coherence that doesn't exist, pulling from what are effectively three different records for the same company and treating them as distinct.
This is where entity resolution becomes load-bearing infrastructure. The gap between a resolved and unresolved entity graph determines whether an AI agent can accurately answer "what is our total exposure to this supplier", or whether it returns a number that's confidently wrong.
.jpg)
What makes this tricky is that the issue often gets mistaken for an AI hallucination. The model gets blamed when the real failure actually starts much earlier in the pipeline: fragmented identity data that was never structured for machine interpretation in the first place.
Human analysts routinely bridge these gaps through context, experience, and institutional knowledge. But AI systems cannot rely on that kind of implicit understanding, which means inconsistencies that humans quietly work around become serious reliability problems at scale.
Different business units using different definitions of "revenue", "active customer", or "conversion" is an old problem. But in an AI context, it becomes unworkable. When building a knowledge graph or semantic layer that AI agents can query reliably, terminological disagreement creates contradictory outputs that erode trust faster than any model limitation.
If your organisation hasn't invested in a unified semantic layer, one that maps business terms to consistent logic, regardless of where the underlying data is, your AI systems will inherit all of that confusion and amplify it.
AI agents that act on data need to understand its provenance. When an AI agent acts on a data point, it needs to resolve questions that incomplete lineage leaves unanswered:
These decisions directly shape how an AI system handles information; whether it treats a value as reliable, flags it for review, or ignores it altogether.
Incomplete lineage also creates serious problems for AI governance and explainability. Increasingly, regulators and enterprise stakeholders want visibility into how an AI system arrived at a decision and which data sources influenced it. When there are gaps in lineage, tracing those decisions back to their origin becomes difficult, if not impossible.
.png)
Enterprise data already lives in siloes across cloud platforms, on-premise warehouses, SaaS applications, and operational systems. The real challenge is whether those environments are connected and governed in a way AI systems can reliably work with.
AI agents operating across federated data architectures need consistent access control, data contracts, and clear ownership at the domain level. Without these, you either lock AI systems out of the data they need or expose sensitive data to systems that shouldn't have it. Neither outcome is acceptable in a production AI environment.
If data access is still handled through scattered permissions and one-off approvals managed separately by different teams, the environment is unlikely to support AI systems operating autonomously and at scale.
In traditional analytics workflows, data quality problems usually become visible only after something looks off in a dashboard or report. A team investigates, logs a ticket, and resolves it over time. The process is slow, but generally manageable.
In an AI-driven pipeline, that same data quality issue for AI systems can propagate through a model, influence a decision, and reach a customer before anyone notices. The feedback loop is compressed, and the consequences are wider.
Data observability: real-time monitoring of freshness, completeness, schema consistency, and distribution isn't optional for AI-ready data infrastructure. If data quality processes only kick in after issues surface, the organisation is effectively operating with a structural blind spot: one that AI doesn’t fix, but instead makes more visible and more consequential.
There is a meaningful and often underestimated difference between data that exists somewhere in your organisation and data that has been deliberately packaged for downstream consumption by analysts, by applications, and increasingly by AI systems.
A large share of enterprise data estates still sit in the first category (Tables exist, pipelines run, reports get produced). But the underlying assets carry no semantic context, no SLA on freshness, no documented schema contracts, and no access interface that doesn't require bespoke integration work every time a new consumer appears.
Data products built with AI consumers in mind are architecturally different. They're not just datasets; they're governed, versioned, observable units of data that carry enough context for a downstream system to consume them reliably without human intervention.
Learn more about data products here.
[related-2]
That means, at minimum:
.jpg)
What connects these issues isn't technology. It's the absence of intentional data architecture, one designed around how AI systems actually work, not how human analysts have traditionally worked.
AI systems depend on context, consistency, trust, and accessibility. They require data to be designed as infrastructure, not just stored as assets. They also need governance models built for autonomous consumption patterns, not only human-driven querying.
The organisations making real progress with enterprise AI are not always those with the most advanced models. More often, they are the ones who invested early in getting their data foundations right before scaling anything else.
Data warehouses store highly structured, processed data for fast queries and reporting, while data lakes hold raw, unprocessed data in its native format, making them ideal for large-scale machine learning and AI projects.
Data governance ensures data is secure, auditable, and compliant with regulations. It provides AI models with context and traceability, improving accuracy and accountability.
No, AI can help, but foundational data issues must be addressed through proper data hygiene and standardised definitions before automation can be effective.
Many systems aren’t prepared for AI’s demands; you need technical architectures with robust identity management and elastic compute to support secure, scalable AI
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


