



Access full report
Oops! Something went wrong while submitting the form.

🤍

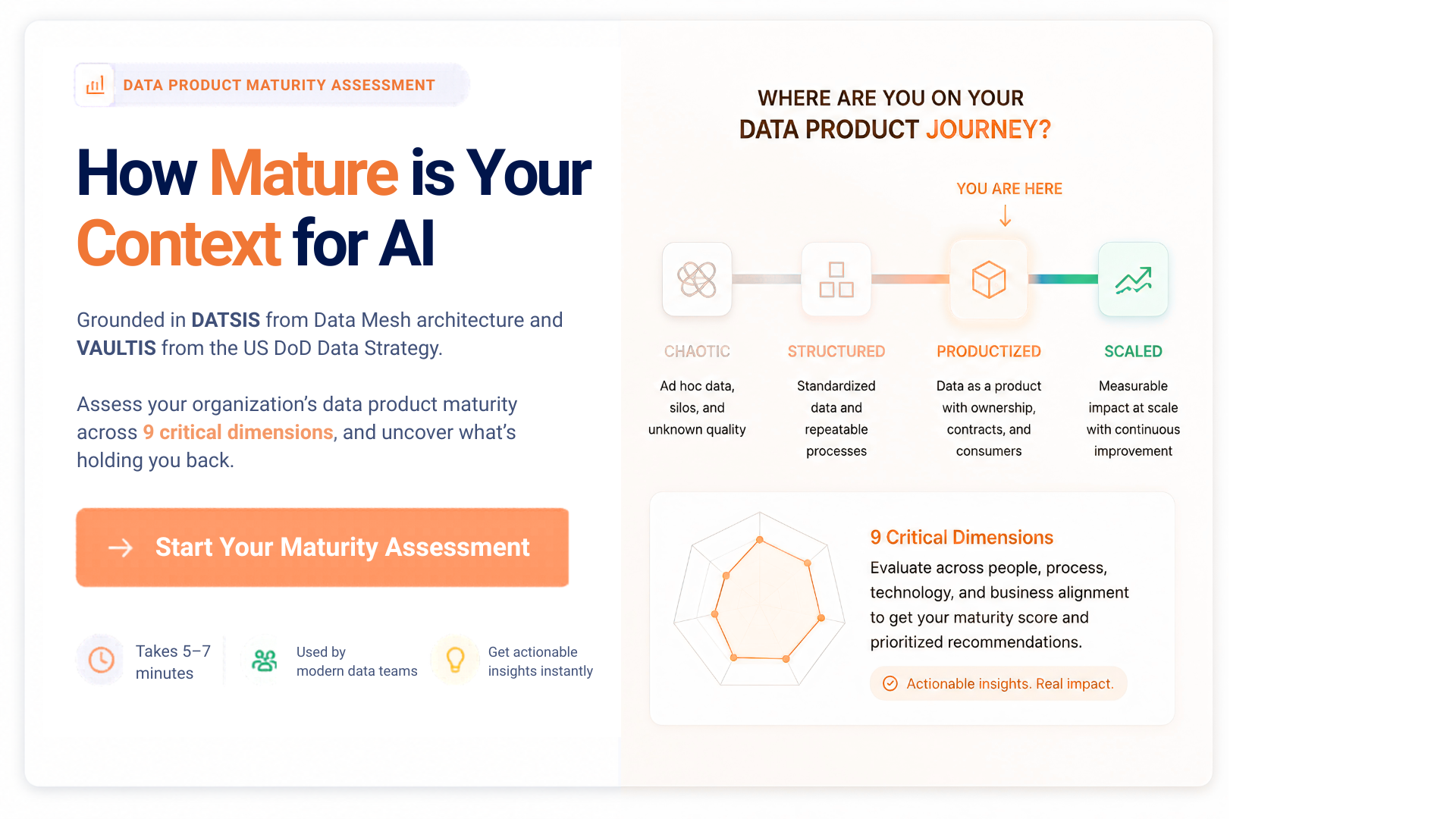
Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)




TABLE OF CONTENT


.png)

If you’re building AI agents today and relying on vanilla RAG for memory, you’re building on sand. As context windows fill, signal collapses. As data grows, fragments multiply. As agents reason across time, static retrieval breaks down. The answer is a fundamentally different architectural commitment: agentic GraphRAG, with knowledge graphs, ontologies, and a unified memory layer served through an MCP server.
This article unpacks the architecture of an agentic GraphRAG and offers strategies for using a data product platform where the semantic layer is the bridge between your governed data assets and your AI reasoning layer.
[report-2025]
Where are Design Decisions in AI Stacks Failing?
Before you write a single line of extraction code, you need an ontology.
An ontology defines the classes of entities in your domain and the typed relationships permitted between them. It is the schema of your knowledge graph. Skip it, and your LLM will invent its own entity types, producing part_of, Part Of, part of, as three separate relationship types within five documents. The graph becomes unusable noise.
Want to know more about semantics in AI context? Read here.
With an ontology, the LLM can only extract what you’ve defined. This constraint is a feature: it reduces hallucination on complex queries, enables cheaper extractor models, and makes the graph queryable at scale.
[related-1]
With data product platforms in use, the mentioned constraint can be mapped to an architecture that teams already understand. Current data platforms produce purpose-built, quality-tested data products, each with its own bounded context. An ontology is how those bounded contexts connect. It makes the implicit relationships between data products explicit and machine-readable: campaign_spend influences pipeline_revenue; net_revenue drives bonus_disbursement. These are organisational reasoning, and the ontology is the only place they can be organised in.
The Semantic Infrastructure Opportunity frames how the Ontology Pipeline is moving from controlled vocabularies to taxonomies, thesauri, and finally knowledge graphs, is how teams build semantic infrastructure that entity resolution and AI reasoning can both depend on. Each stage produces a deliverable. Each deliverable is versioned, validated, and measurable.
The practical design recommendation: define a Global Ontology split into sub-ontologies. For a digital twin use case, this might mean a Document Ontology (capturing DOCUMENT and CHUNK nodes, wired by PART_OF, NEXT, and MENTIONS edges) and a Person Ontology (capturing nodes, wired by RELATED_TO, TODO, EXPERIENCED, and HAS edges). The schema is flexible, but it must be deliberate.
[playbook]
With your ontology defined, extraction runs across three modes:
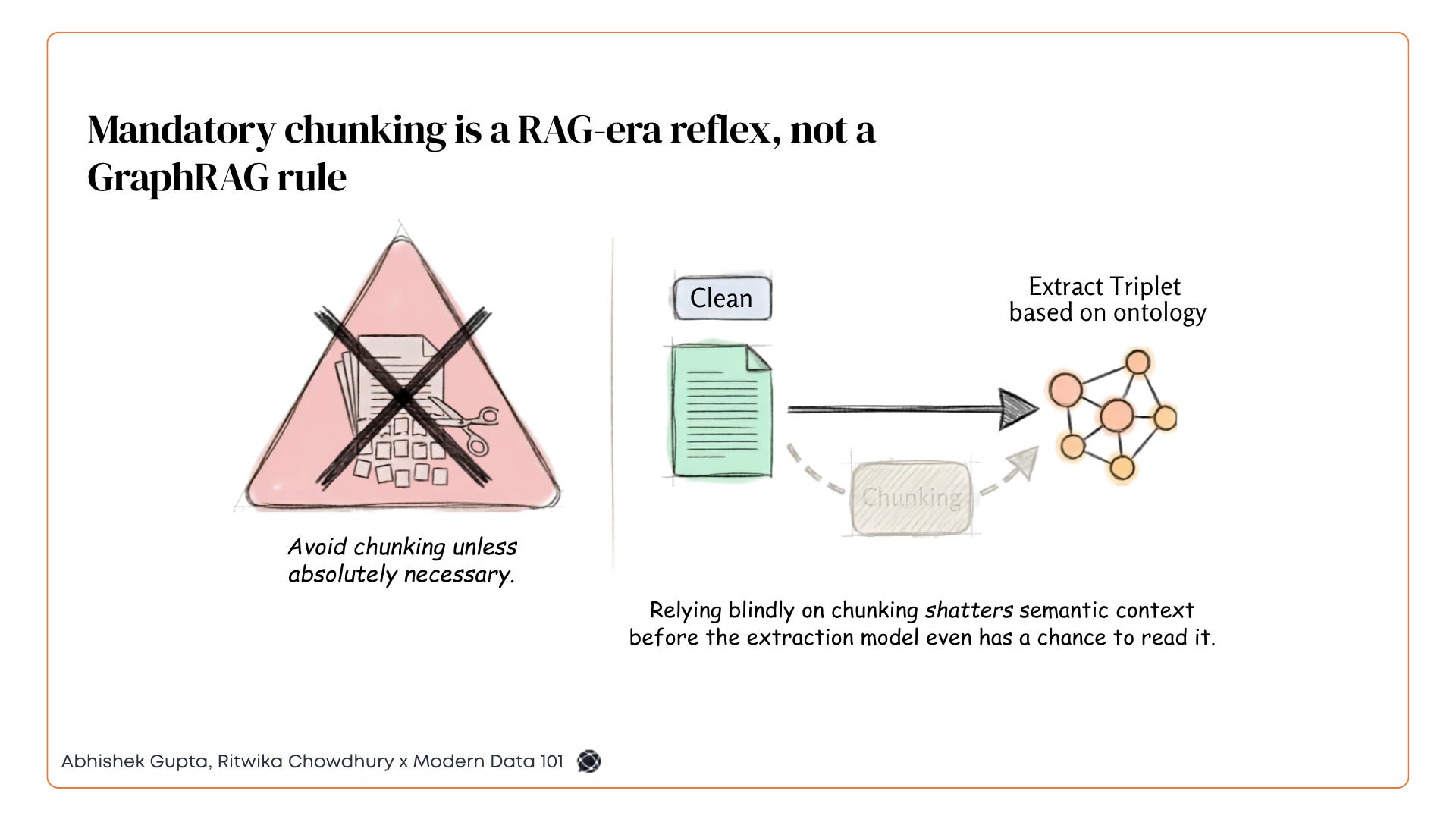
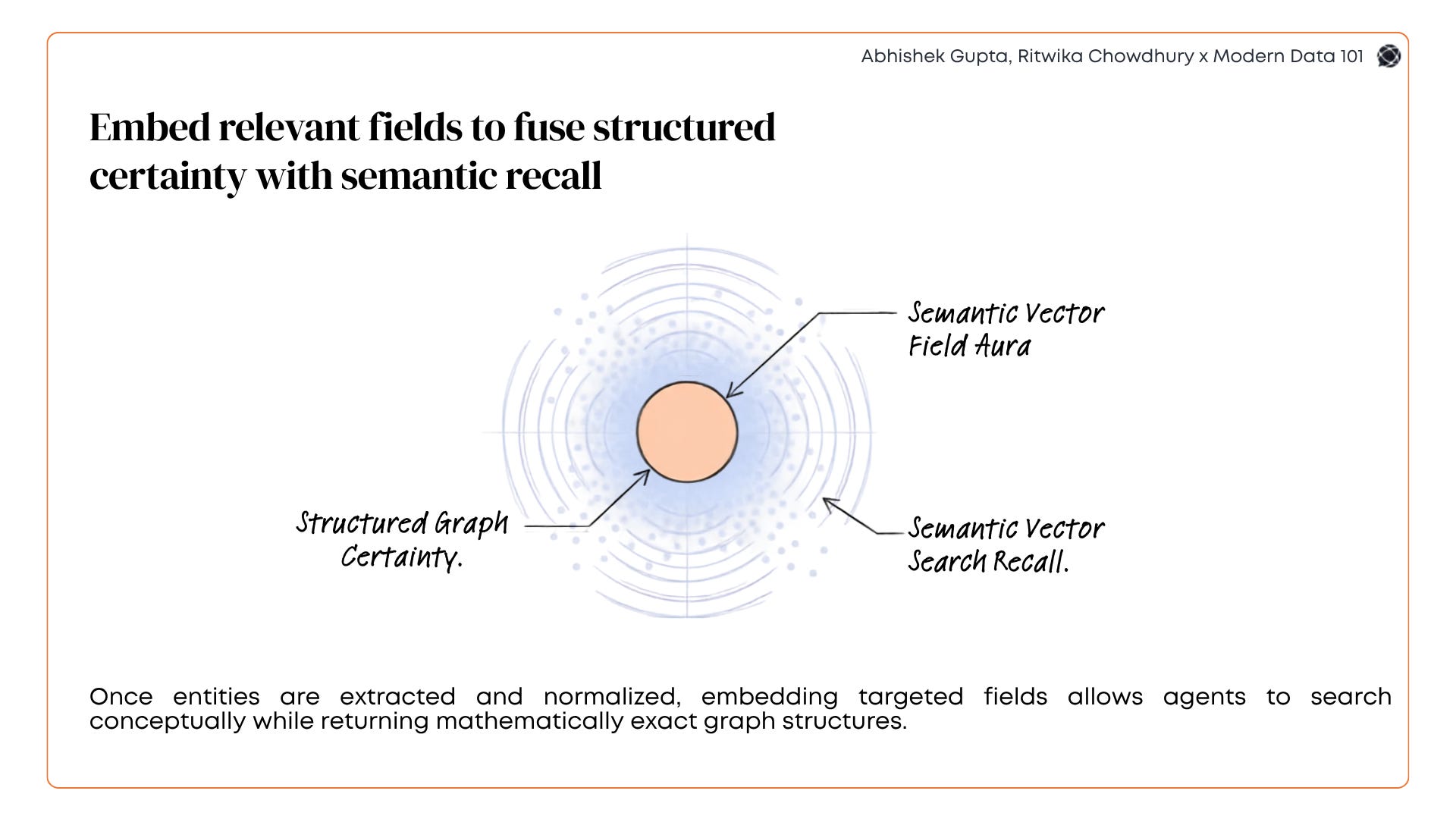
The memory pipeline then does five things with these extracted triplets: cleans the incoming document, optionally chunks it (avoid chunking unless necessary, it’s a RAG-era reflex more than a GraphRAG requirement), runs graph extraction, normalises (the most critical step, canonical IDs prevent the same entity existing as duplicates across extractions), and embeds relevant fields for semantic search.
[related-2]
Semantic information is siloed at the data product level, but organisational reasoning operates across products. Consider a supply chain scenario. Your inventory data product knows stock levels. Your supplier data product knows lead times. Your demand forecasting product knows projected consumption. Each is well-governed, well-documented, and independently useful.
Data products solve the ownership problem, where each domain team ships a reliable, tested, governed asset. What they don’t solve is the reasoning problem: your agent doesn’t operate inside a single domain.
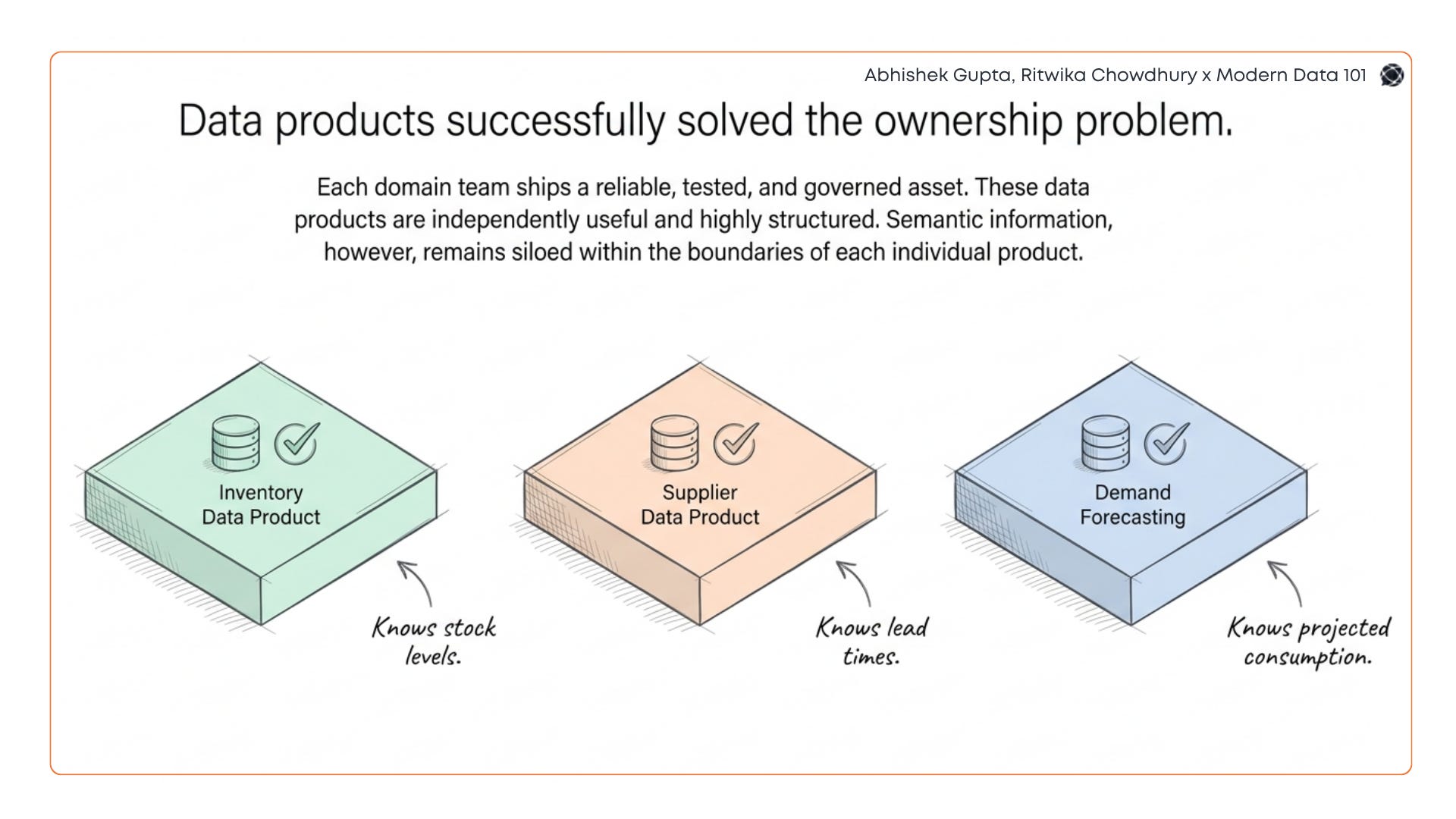
Consider a supply chain scenario. Your inventory data product knows stock levels. Your supplier data product knows lead times. Your demand forecasting product knows projected consumption. Each is well-governed, well-documented, and independently useful.
But when an agent is asked, “Which SKUs are at risk of stockout given current supplier delays?” that question maps to the relationships between them, and those relationships have never been formally modelled.
This is the gap the knowledge graph closes. It is the semantic layer that sits above them. Supplier X fulfils Component Y; Component Y is required by Unit Z; Unit Z has forecasted demand of N units. Each of those typed edges draws on facts that already exist in your governed data products. The graph makes the chain traversable by an agent in a single query, without joining tables across domains or moving data.
Knowledge graphs must capture the data as well as the institutional meaning behind it, the domain-specific definitions, and the relationships that business users reason with daily but that never make it into a schema.
For teams building on a Data Developer Platform architecture, that means treating every data product as a node-and-attribute source, and treating every business rule that links products as a candidate relationship edge.
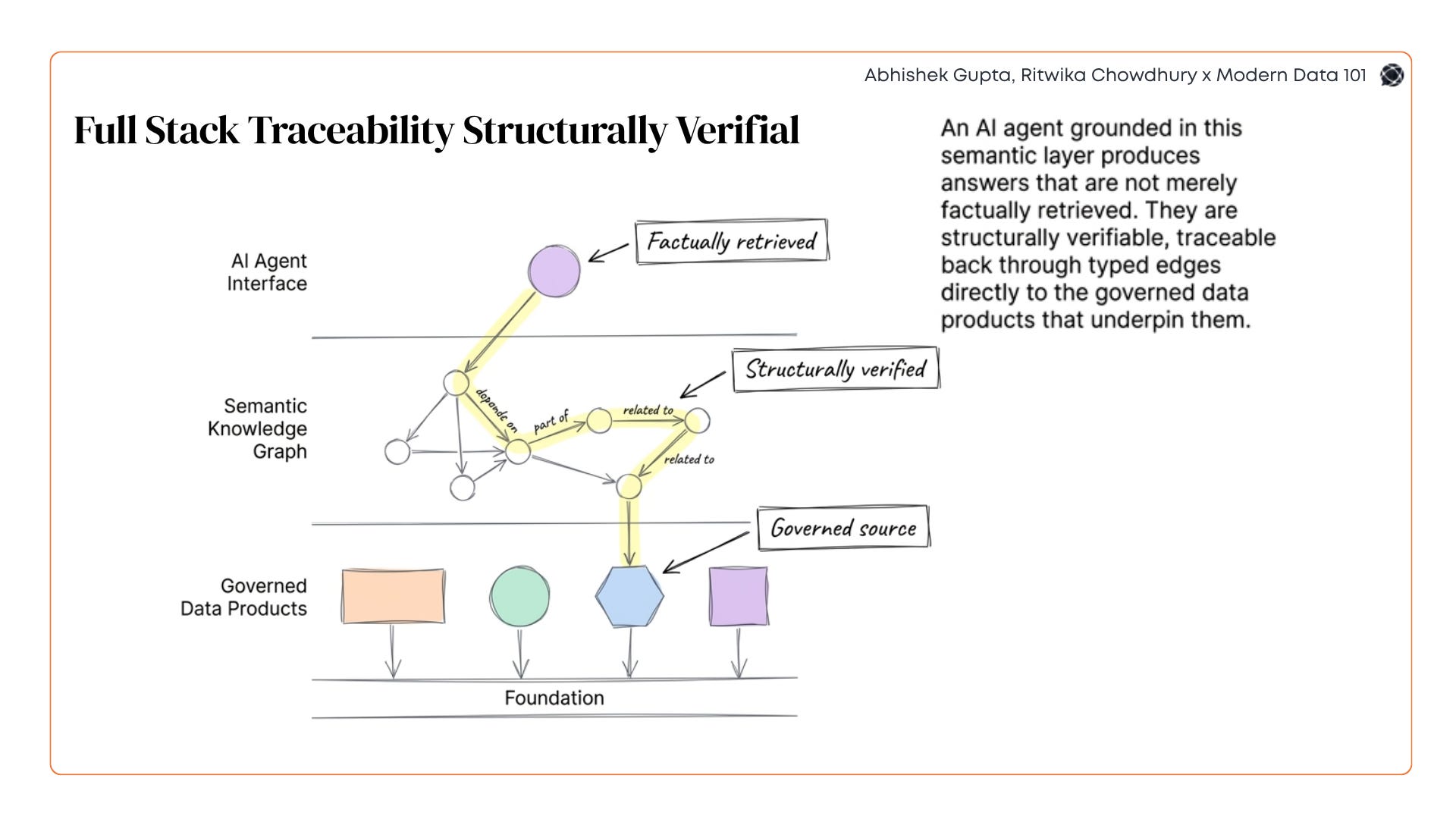
The practical payoff is significant: an AI agent grounded in this layer can produce answers that are not just factually retrieved but structurally verifiable, traceable back through typed edges to the governed data products that underpin them.
GraphRAG’s retrieval advantage over standard RAG is the multi-hop traversal that follows initial ranking.
Stage 1 runs text search (exact keyword) and semantic search (embedding similarity) in parallel, then merges results with Reciprocal Rank Fusion (RRF) to produce ranked entry points into the graph.
Stage 2 walks 2-3 hops across typed edges from those entry points, expanding the result set by following relationships the LLM would otherwise have to hallucinate.
Two traversal strategies serve different query types. Bottom-up expands entities for depth, which is useful when a query requires specific, interconnected facts. Top-down hops across communities for high-level overviews, useful for synthesis queries. The trade-off is context size versus latency versus precision.
GraphRAG becomes agentic when the agent can both search and write to the knowledge graph autonomously, through a well-defined interface.
The Model Context Protocol (MCP) is that interface. An MCP server exposes two families of tools to the agent: search_memory tools, which bring the relevant subgraph slice into the context window on demand, and write_memory tools, which run the data and memory pipelines on the current conversation or any incoming document, enabling continual learning without manual re-ingestion.
Every conversation the agent has is itself a candidate for ingestion, tracking preferences, tasks, and evolving context without manual re-ingestion. The MCP server is the interface that makes this bidirectional: memory in, memory out, continuously.
Here is how the full agentic GraphRAG system operates at runtime, end to end.
[related-3]
Consider a data platform like a data developer platform. This provides the governed data product layer that the knowledge graph is built on top of, the metadata infrastructure that seeds the ontology, the orchestration layer that runs extraction, and the services layer that hosts the MCP server. It's not one integration point. So there is a full stack underneath the GraphRAG system.
Any data platform with an active metadata catalog, one that tracks entities, lineage, domain ownership, and business glossaries, gives you your ontology substrate for free. You're not defining entity types from scratch; you're formalising what the catalog already knows.
A governed data product registry where products are discoverable, tagged by domain, and linked to their upstream sources gives you your prime graph nodes, already quality-tested, already semantically labelled, already owned.
A platform with source-agnostic connectors (abstracting S3, warehouses, streams) paired with a workflow orchestration layer means your extraction pipeline runs as a scheduled, governed job. Source diversity stops being an architecture problem.
A platform that lets you deploy long-running services under attribute-based access control is where your MCP server lives. Policy-governed memory access, which is more than an open graph API anyone can call.
Agentic GraphRAG is an architectural shift, from stateless document lookup to a self-evolving, relationship-aware memory layer that compounds with every agent interaction.
The stack is clear: an ontology-grounded knowledge graph built on governed data products, enriched through agentic extraction, queried and updated through an MCP server. Each layer earns its place. The ontology constrains what gets extracted. The data products guarantee that what gets extracted is trustworthy. The MCP server makes the graph accessible and writable to the agent at runtime.
The result is an AI agent that remembers, reasons across domains, and gets smarter with use, without manual intervention.
RAG retrieves relevant data to ground LLM responses.
MCP (Model Context Protocol) standardises how models connect to tools, apps, and external context.
AI Agents go beyond answering; they plan, reason, take actions, use tools, and complete workflows autonomously.
GraphRAG combines Knowledge Graphs with RAG to improve how AI retrieves and reasons over connected data. Instead of fetching isolated documents, it traverses relationships between entities, concepts, and events, enabling more contextual, explainable, and multi-hop answers.
Not necessarily. The choice of graph database should follow the complexity of your traversal requirements, not the other way around. Many production GraphRAG systems run on relational or document stores with vector extensions. Specialised graph databases earn their place only when graph-native algorithms, such as shortest path, community detection, and deep multi-hop, are central to the product's reasoning, not peripheral.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


