.avif "Brij Mohan Singh")



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...




%20(1).png)
TABLE OF CONTENT



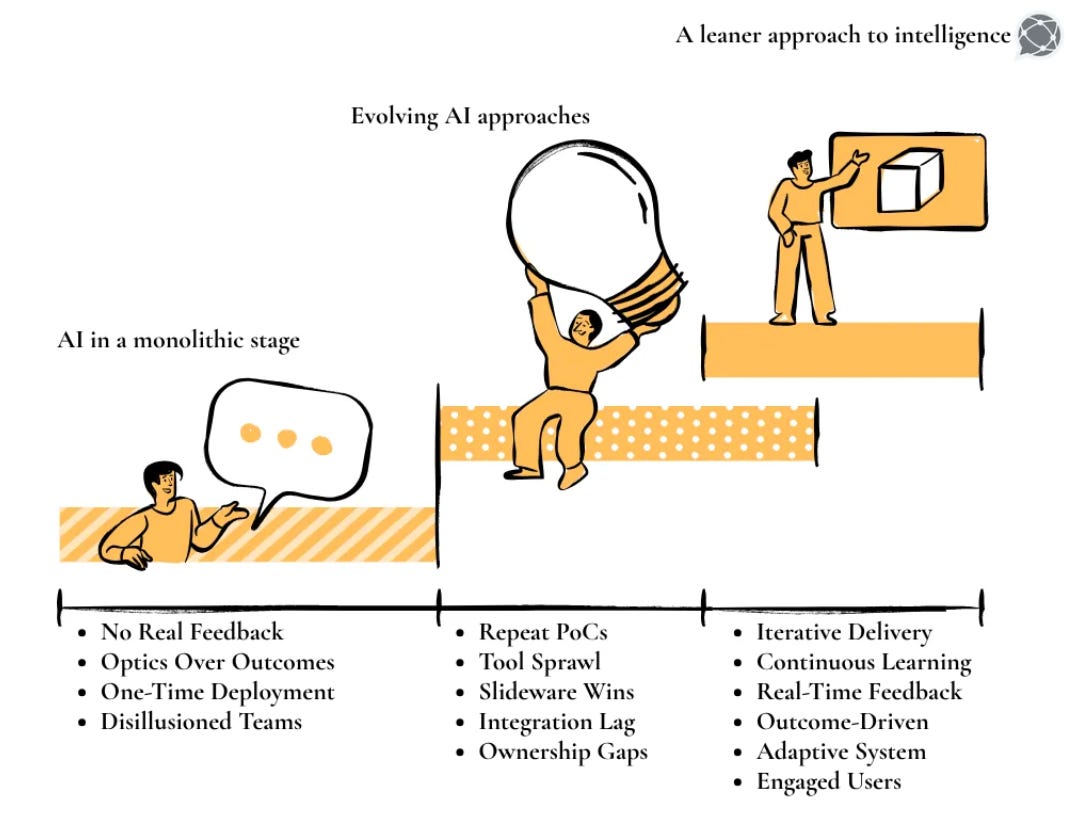
Data leaders today are walking a tightrope. On one hand, there is pressure to modernise, innovate, and keep up with what’s next. Consider how technology is moving faster than we ever anticipated. The way of working just back in early 2024 is vastly different from how we do things now: from code & business to day-to-day browsing. And the transition will not slow down, much less the technology.
On the other hand, there are bottlenecks of legacy systems, fragmented platforms, and teams racing to match the old systems and processes with the new world.
The demand curve is getting steeper: Faster insights, deeper interconnectivity, and decisions that can’t wait. The margin for delay is shrinking. The expectation for clarity is high. However, in the case of data, it isn’t a ‘more, the merrier’ situation. In fact, the more, the messier (often)!
Traditional databases are like predefined maps, while graph databases are living networks that grow and adapt with your data and questions. Consequently, the need for a more flexible and comprehensive data model is becoming increasingly urgent in today's dynamic data landscape.
Enter Graph Databases!
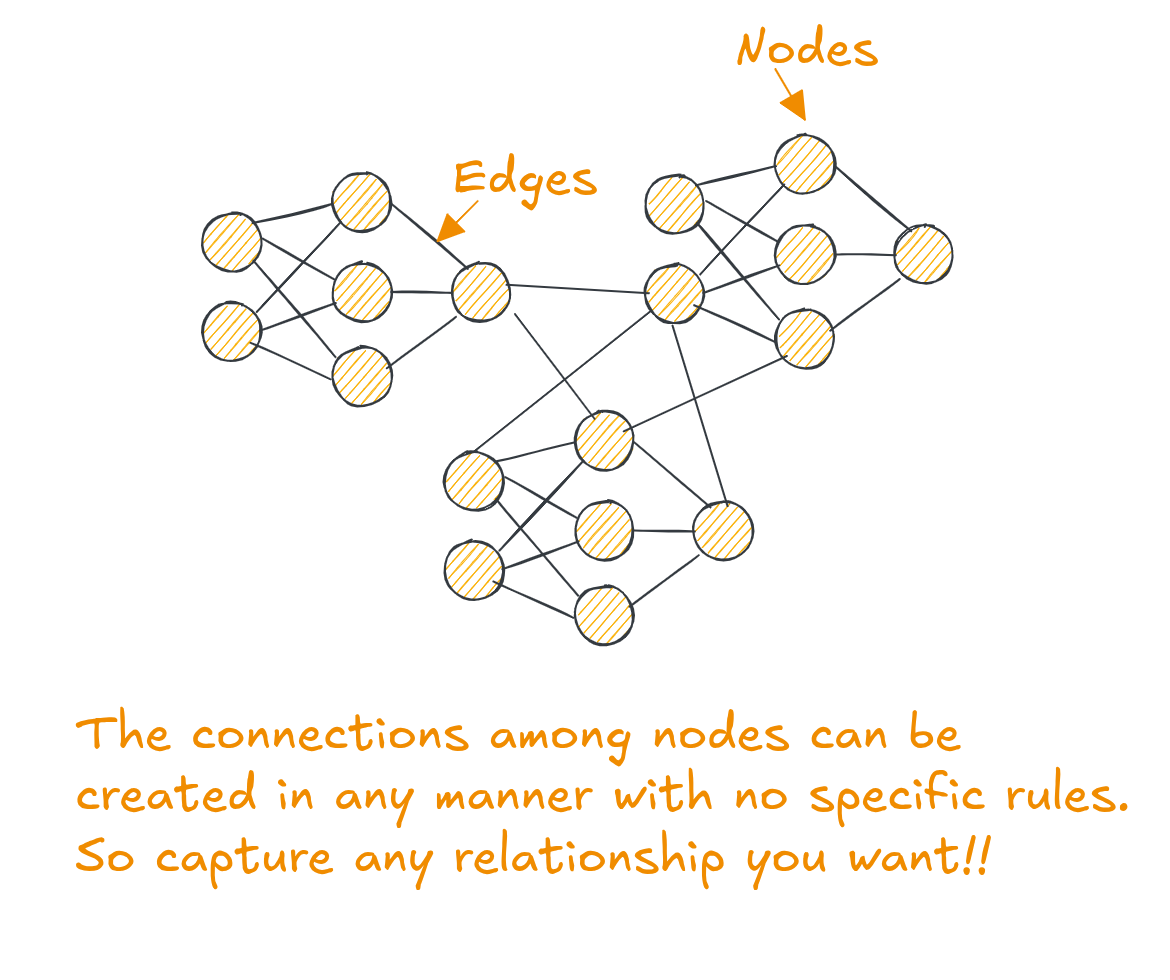
Graph databases refer to a collection or database that stores and leverages data as nodes, edges, relationships & properties instead of the traditional tabular or document format.
Owing to its integral feature of managing relationships within data, they can single-handedly address the challenges of data abstraction and capturing multidimensional data relationships.
The simple way you can think of a graph database is as an e-commerce platform where products, customers, and reviews are all individual nodes. Each relationship is stored as a direct connection, like a customer purchasing a product, reviewing it, or products often bought together.
So this means you can easily answer queries like, 'which products do customers who bought X tend to by next?.' This can be done without relying on complex join operations across multiple tables. This direct representation of relationships makes it simpler to detect the purchasing patterns and improve recommendations to deliver a more personalised shopping experience.
Data personas like architects, designers or engineers across industry verticals face challenges regarding traditional relational databases when searching for the data that fits right and serves the objectives.
Imagine reading a document containing multiple data points about individuals: height, weight, and occupation. For a use case like tracking body metrics, you create a table that only stores height and weight, ignoring other data like occupation because they aren’t needed.
In a relational database, this abstraction is rigid and predefined. The schema only supports height and weight columns; occupation is lost in the process. If, later on, you want to analyse how someone’s occupation correlates with their health, the relational database has no way to provide that context.
You'd have to return to the original document, extract the data, and potentially rework the schema to accommodate this new relationship. Here, we’ll boil down the problems into two broader categories.
Traditional relational databases force you to fit data into predefined tables. What happens here is,
you discard valuable context and relationships that don't fit the initial schema.
These DBs often require a fixed schema, making it hard to adapt when new data relationships emerge. The problem? Updating schemas is time-consuming and error-prone.
Relational databases are inefficient when handling data with many-to-many relationships or complex, interconnected entities (e.g., social networks, recommendation systems, supply chain relationships).
Queries become slow and complex, making it challenging to discover hidden connections.
Moreover, traditional relational databases focus on structured queries for predefined use cases but are bad at discovering relationships across large datasets (e.g., finding connections between seemingly unrelated data).
The three fundamental elements driving graph databases are ‘nodes’, ‘edges’ & ‘properties’.
But how? These graph DBs go beyond relational databases by capturing complex, multi-dimensional relationships between data points.
Unlike traditional approaches, graph databases preserve contextual and related information, even when it's not immediately relevant to a use case.
In graph databases, relationships are treated as first-class citizens, meaning they are fundamental components of the data model, in par with the data entities (nodes) themselves.
In a graph database, relationships are stored directly as dedicated objects with their own attributes (properties), types (labels), and directional information. Unlike relational databases, which rely on foreign keys and join operations to infer relationships at query time, graph databases physically store these connections, enabling rapid, index-free traversal.
Relationships carry metadata such as timestamps, weights, or other contextual information, making them as dynamic and flexible as the nodes they connect. These relationships are, hence, more than simple links and allow complex, multi-dimensional interactions (like those in supply chain networks or social media) to be modelled naturally and evolve over time without restructuring the entire schema.
Because relationships are integral to the graph’s structure, traversing them doesn’t require expensive join operations. The “index-free adjacency” principle means each node directly points to its connected neighbours, ensuring that even deep, recursive queries perform efficiently.
Traditional data structures discard data that doesn’t fit the immediate need, but graph databases allow for more flexibility and discovery-driven analytics. They offer the potential to explore hidden relationships without predefining all the questions in advance. This approach enables deeper insights and unlocks new use cases in analytics and discovery.
While graphs have their overarching benefits, we should not let them be limited to static and manual update capabilities. What organisations require the most is to enrich the knowledge base of the graph for improved reasoning and answering capabilities.
Just like the human brain doesn’t learn everything instantly, it builds knowledge layer by layer, refining it over time. Graphs can be positioned in the industry in a way that serves as evolving systems, similar to human cognitive processes.
Traditional knowledge graphs do not evolve dynamically; they are usually manually updated or fixed in structure.
So the real power comes when graphs are continuously enriched, and this is where AI agents play a crucial role in mimicking, similar to how the human brain forms connections over time.
AI agents can dynamically update and refine graphs over time, making them more intelligent & valuable. In the following section, let us dive into how AI agents make these graphs better!
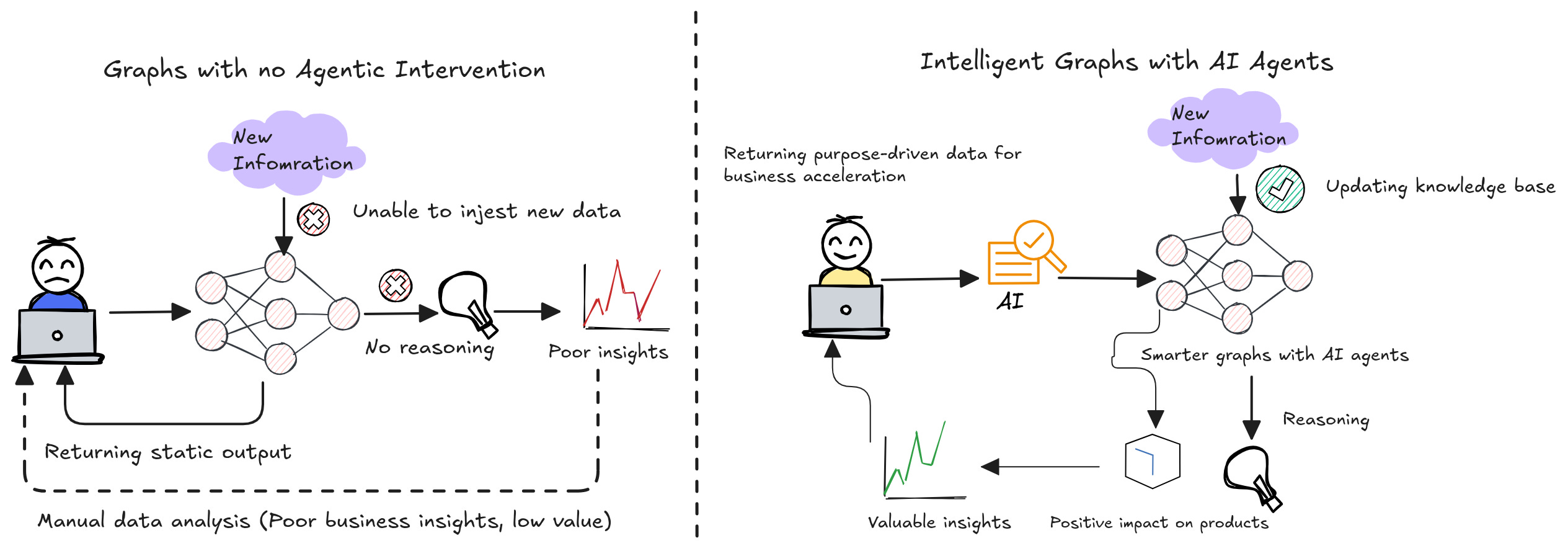
Speaking technically, AI agents should not just query graphs but actively enrich and update them. These should self-improve, leading to better insights for applications.
For example, if a new relationship emerges, the agent should automatically add it to the graph, rather than relying on human updates.
What do we expect from AI Agents?
For the AI-driven graph representation to grow over time,
Depth = Better Intelligence & More Accurate Responses.
As data volumes increase, researchers and tech developers are constantly trying to turn these knowledge systems into evolving and intelligent systems with the help of AI agents.
Think of it like a detective following leads: not just reacting once, but going deeper with every new clue, forming connections that weren’t obvious at first. That's recursive exploration, and doing it autonomously means it happens without human micromanagement.
Recursive and autonomous expansion refers to the idea that a graph doesn't grow just by adding facts once, instead, it evolves over time, often by:
So, the vision here is to build Agentic systems that don’t just consume a graph but constantly improve the knowledge base. One of the most valuable techniques here is to leverage the capabilities of multi-hop reasoning & reinforcement learning.
A knowledge graph alone is like a database of connections, but an AI agent can perform reasoning on top of it to generate insights. The AI agent doesn’t just retrieve information, it reasons over multiple steps to draw conclusions. Multi-hop queries allow the AI agent to follow logical paths across the graph and synthesise insights.
Traditional knowledge graphs rely on one-shot predictions (i.e., predicting relationships in a single step). However, RL-based frameworks allow agents to make multi-hop queries or sequential decisions to discover new knowledge.
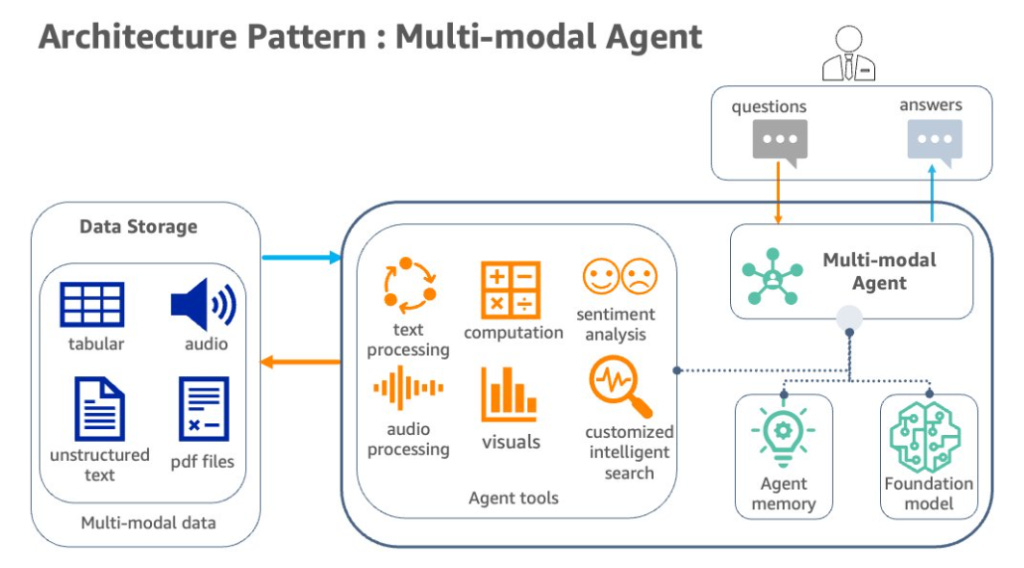
Information doesn’t reside solely in structured text or databases; it’s found in images, videos, audio, and more. To fully enrich a knowledge graph, agents must be able to interpret and integrate knowledge from multiple modalities.
This needs the ability to align semantic representations across different data types, reason visual or auditory elements, and connect them meaningfully with textual information. The result is a richer, more holistic graph that reflects a broader understanding of the world.
Knowledge is not frozen in time. When we relearn something, we build on previous knowledge and refine our understanding. Our brain follows a learning cycle, and similarly, the graphs should update. Relationships change, contexts shift, and new entities emerge.
To reflect this, agents must reason over temporally evolving data. Users now know not only the existing fact but also when it turned true and how the truth value has changed over time. Temporal reasoning becomes critical in allowing agents to reflect the chronological consistency into the knowledge graph, ensuring that inferences align with the progression of real-world events.
AI agents constantly "relearn" the graph by either
This incremental improvement process leads to more accurate insights over time.
A big breakthrough happened when systems learned to read text and find relationships on their own. They’d start with a few known examples, then look for similar patterns in large amounts of text to discover more facts. Some could even suggest new facts and check them against online information to see if they made sense.
Later, more advanced systems were built that could scan huge volumes of unstructured text and extract simple, sentence-like facts. For example, "water boils at 100°C." These didn’t rely on predefined templates, making them flexible and scalable.
💡 The challenge? These extracted facts still needed to be cleaned up and organised before they could fully integrate into a meaningful graph.
This is where the agent's role becomes more sophisticated. It doesn’t just extract, it normalises, resolves co-references, deduplicates entities, aligns with existing graph ontologies, and even decides which facts are worth integrating.
Here, reasoning plays a central role. The agent asks:
Only then does the fact earn its place in the graph.
Modern organisations in the data space already manage structured data at scale: clean tables, governed datasets, dimensional models, and domain-specific data products. these are high-value assets and not mere datasets with siloes.
Structured Data → Connected Knowledge
Self-evolving knowledge graphs need two primary things:
Your structured data already captures:
You’ve modelled entities, defined schemas, and governed access. You’ve made the data queryable and composable.
Moreover, taking purpose-driven data products makes your data assets business-ready, where these are modelled around real-world concepts that answer the precise business questions.
These are consistent, i.e., governed, versioned, and contract-driven.
Now, by layering a graph on top, you create a knowledge infrastructure that can drive:
Cross-Domain Linking Without Data Movement
Instead of new pipelines, the graph can link across your existing data products. For instance, a finance model and a support model don’t need to be merged; they just need to be connected through graph logic. You preserve your modularity but gain holistic intelligence.
Minimal ETL loads
You don’t need to move or duplicate data. Just a layer that maps structure into connections.
At a glance, feeding structured data into a graph, you unlock:
In the agentic workflows, as we walked through earlier, you get a living, connected view of your data products; one that becomes smarter without re-engineering anything.
An AI agent can reliably detect new links, changes, and missing connections over time. As your data products update, the graph self-evolves: learning, expanding, and reflecting real-world complexity.
As businesses increasingly turn to AI to power their applications, there's a growing recognition that data alone isn’t enough. It’s how that data is structured, connected, and continuously enriched that determines the quality of insights and decisions. This is where AI-updated knowledge graphs provide a significant edge.
Let’s be honest. Graph technology sounds complex. Schemas, modelling, integrations... It’s a lot. That’s why many businesses hold back.
But here’s the shift: you don’t need to build graphs yourself anymore.
Today, they’re offered as infrastructure: pre-built, self-evolving, and maintained by AI agents.
You simply connect your systems. No deep-graph expertise needed. The agent handles updates, structure, and growth in the background.
And the best part? As new data comes in, the graph keeps improving, which means your search, recommendations, chat, and analytics all get smarter automatically.
Most teams assume you need a graph expert to make all this work, but you don’t.
The complexity? It's abstracted away. The AI agent behind the scenes keeps the graph healthy: updating connections, adding new insights, and ensuring everything stays consistent.
You just use it. No need to model relationships manually or manage the graph yourself. It’s intelligence that takes care of itself and keeps getting better.
When you power your systems with the AI-driven graph infrastructure, you don’t just get more data; you get smarter outcomes across the board.
Your customer support gets sharper, resolving queries faster with context-aware answers. Fraud detection becomes proactive, spotting subtle patterns others miss. Product recommendations get more relevant: not just "popular," but personally meaningful. Your dashboards? They reveal insights that cut across silos instead of slices of isolated data.
Because it’s not just about more data, it’s about the right structure, continuously enriched by an agent that’s always learning.
With AI-powered graph infrastructure, you’re not managing complexity but unlocking intelligence. No manual updates. No retraining. Just a graph that learns, adapts, and delivers better results every time your data changes.
Smarter apps. Faster insights. Reduced overhead.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡


From The MD101 Team 🧡
The Modern Data Survey Report is dropping soon; join the waitlist!

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


