


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



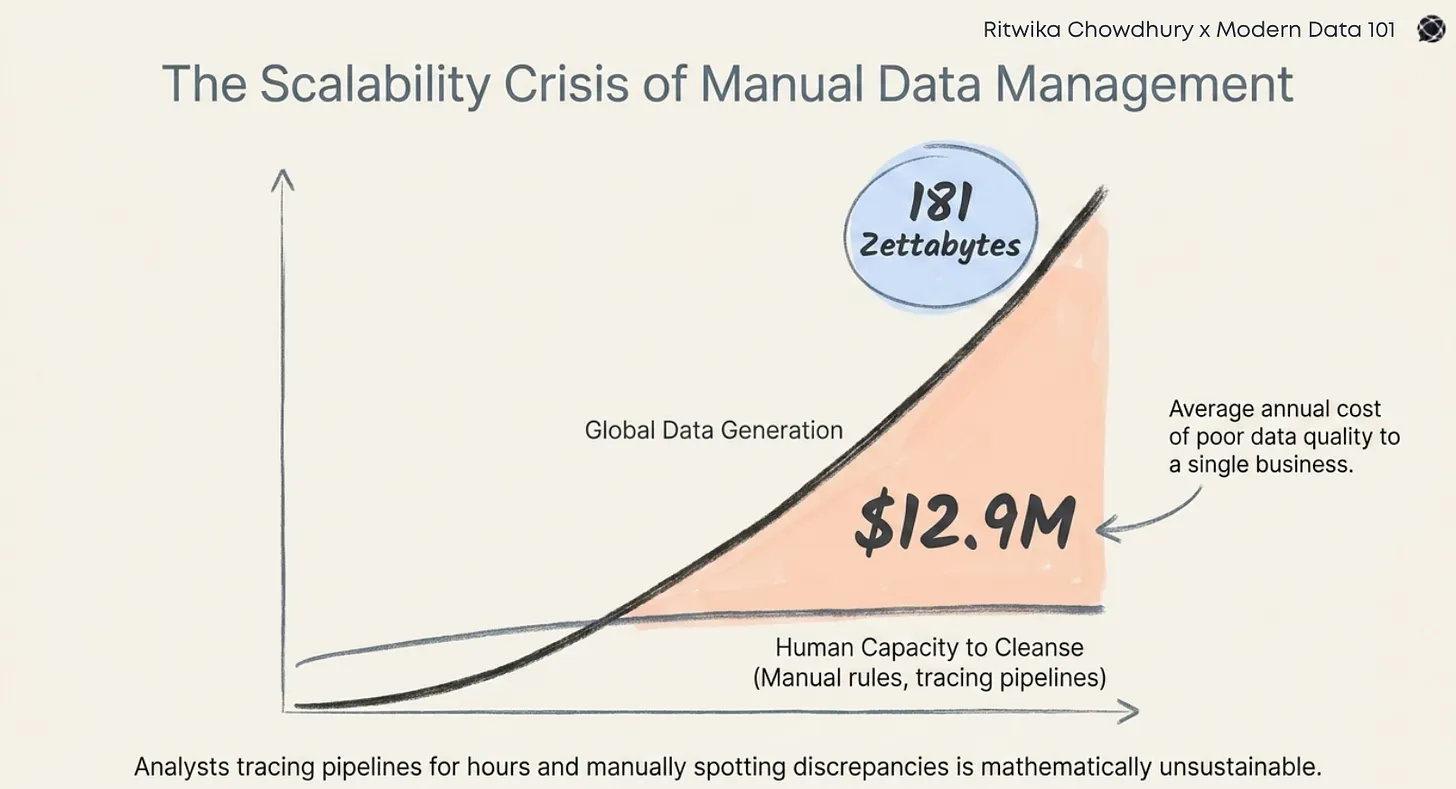
Ever stared at a once-vibrant dashboard, now frustratingly blank? Or wrestled with a report that seems stuck in time, stubbornly refusing to reflect the latest reality? And that nagging sense of data drift, like a hidden current pulling your insights off course? These aren't just minor annoyances; they're often the visible signs of a deeper instability lurking within our data infrastructure.
The underlying issue? A kind of loose coupling bordering on a chaotic free-for-all between those producing data and those consuming it. We've built intricate pipelines, often stitched together with the digital equivalent of duct tape and crossed fingers, relying heavily on tribal knowledge. There was no formal mechanism to clearly state, rigorously validate, or consistently enforce expectations about the data being exchanged.
As the appetite for data exploded, with ML models hungry for training data, APIs serving real-time insights, reverse ETL pushing data back into operational systems, and business dashboards demanding up-to-the-minute metrics, this inherent fragility simply multiplied. Centralised governance teams, often stretched thin, found themselves in a perpetual state of firefighting, reacting to the latest breakage rather than proactively building robust and trustworthy data flows.
Without the clarity of explicit data contract meaning, teams spend countless hours deciphering the wreckage of data pipeline failures, tracing the lineage of downstream data breaks, and ultimately becoming data team bottlenecks instead of the value drivers they're meant to be. The insidious creep of schema drift goes unnoticed until a critical process grinds to a halt.
Enter data contracts: declarative agreements, clearly defined and mutually understood, that act as essential bridges between data producers and consumers. They enforce clarity on expectations, promote stability in data interfaces, and establish accountability across the entire data ecosystem, offering a much-needed antidote to the chaos and uncertainty of ungoverned data flows. This is the bedrock of modern data governance in action.
So, what exactly are these data contracts that everyone's talking about? They're more than just dry interface definitions; think of them as living data product boundary agreements. They represent a formal pact between those generating data and those who rely on it.
Imagine them as data schema contracts that evolve over time, like living APIs governing the exchange. Key components of these contracts typically include:
It's crucial to understand how data contracts vs. testing differ. While tests validate the current state of the data against certain rules, data contracts define the agreed-upon expectations for that data over time. They set the standard that both producers and consumers commit to, informing the design and evolution of data pipelines, whereas tests verify adherence at a specific point in time.
Think about it through the lens of data product contracts. Every well-defined data product, that self-contained unit of data with inherent value, has interface-driven data sharing mechanisms – its output ports. These are the points where consumers access the data product's value.
However, not every consumer needs the exact same cut of the data. A business intelligence dashboard might require aggregated metrics, while a machine learning model needs granular, historical data, and an external API demands a specific, filtered view. This is where the power of contracted views comes in.
Data contracts enable differentiated delivery. They allow data producers to define specific, agreed-upon interfaces (contracts) for different consumer needs. This isn't just about platform thinking – providing the underlying infrastructure. It's about domain-driven design in data, where we understand the specific needs of each domain consuming the data and tailor the output accordingly through a contract.
In this context, contracts become more than just schema definitions. They evolve into a tool to bundle not just the raw data, but also the associated metadata, any necessary code for transformation or access, the underlying infrastructure definitions, and, crucially, the formal agreements on how that data will be provided and consumed.
The principles behind data developer platforms (DDPs) are heavily influenced by the success of IDP for data (Internal Developer Platforms) in the software engineering world. IDPs provided software teams with self-service infra, streamlined CI/CD pipelines, and enhanced observability, significantly improving developer experience and reducing operational overhead. Think of the specification files that software engineers use to manage various platform resources in a self-service manner.
Similarly, DDPs aim to bring this level of efficiency and control to data engineering. And a core primitive in this platformization of data engineering is the contract registry. Imagine a central place where data contracts are defined, versioned, and managed – a single source of truth for data expectations.
Why are contracts such a core primitive in platformised data engineering? Because they provide a standardised, machine-readable way to define data interfaces. This allows DDPs to automate various aspects of data management based on these contracts, such as data validation, monitoring, and even access control. Contracts become first-class citizens of the platform, enabling automated contract registry, seamless versioning, and robust auto-enforcement of data expectations.
By baking contracts directly into the data platform, DDPs help reduce the operational load on data teams, increase confidence in data quality, and ultimately accelerate the delivery of reliable data products.
Data contracts fundamentally reshape how data producers and consumers interact, fostering a more mature and reliable ecosystem:
How Data Contracts Help Data Governance is a crucial question for any organization concerned with managing its data effectively. Data contracts provide a powerful mechanism for automated governance.
Instead of relying on a central approval committee to review every data change, contracts allow for decentralized data ownership. Data product owners within each domain are responsible for defining and upholding the contracts for their data.
Platform teams play a vital role by defining data policy templates, setting up contract-based compliance checks, and implementing the underlying automated governance infrastructure and enforcement logic. This shifts governance from being a purely manual and often political process to one that is more programmable and consistently applied.
With clear contracts in place, governance becomes less about being a gatekeeper and more about establishing robust guardrails that empower teams to move quickly and confidently while adhering to agreed-upon standards for quality, security, and compliance.
Embarking on the journey of data contracts doesn't need to be an overwhelming overhaul. Here's a practical contract adoption guide:
The complexity of modern data ecosystems demands shared expectations. We've moved beyond simple point-to-point data transfers to intricate webs of interconnected pipelines and data products. In this environment, relying on implicit assumptions and tribal knowledge is no longer sustainable; it's a recipe for constant breakages and wasted effort.
Contracts give shape to the invisible, turning that often-murky tribal knowledge into explicit, machine-readable system primitives. They are, in essence, the API layer of the data mesh, providing the necessary structure and clarity for decentralized data sharing. They represent the handshake of the data product era, establishing clear terms of engagement between data providers and consumers.
Without them, scale collapses under the weight of ambiguity. As data volumes and the number of consumers continue to grow, the lack of clear contracts will inevitably lead to increased fragility, higher operational costs, and a significant erosion of trust in the data itself.
With them, teams move faster because trust is no longer manual. When expectations are clearly defined and consistently enforced, data practitioners can spend less time debugging broken pipelines and more time building innovative and valuable data products. Data contracts are not just a nice-to-have; they are a fundamental necessity for building robust, scalable, and trustworthy data ecosystems in the modern era.
2025 is brimming with new opportunities—greater specialization in AI for industries, deeper integration of autonomous systems, and a surge in demand for real-time, privacy-conscious solutions. This year isn’t just about smarter AI—it’s about AI that acts, adapts, and delivers tangible value across every domain.
2025 will surely see some awesome updates in data engineering, with new tech updations knocking on our door almost daily, mergers, acquisitions, and funds in the space hint towards a brighter future.
Connect with a global community of data experts to share and learn about data products, data platforms, and all things modern data! Subscribe to moderndata101.com for a host of other resources on Data Product management and more!
.avif)
📒 A Customisable Copy of the Data Product Playbook ↗️
🎬 Tune in to the Weekly Newsletter from Industry Experts ↗️
♼ Quarterly State of Data Products ↗️
🗞️ A Dedicated Feed for All Things Data ↗️
📖 End-to-End Modules with Actionable Insights ↗️
*Managed by the team at Modern
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




