


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



Last updated 10th December 2025
The modern data stack has gained a lot of popularity within enterprises that have data-driven ambitions. And that’s not even a surprise, given that the stack itself is driven by cloud-native tools designed to support Artificial Intelligence (AI), Machine Learning, and advanced analytics. The stack comes with a promise of scalability, modularity, and speed.

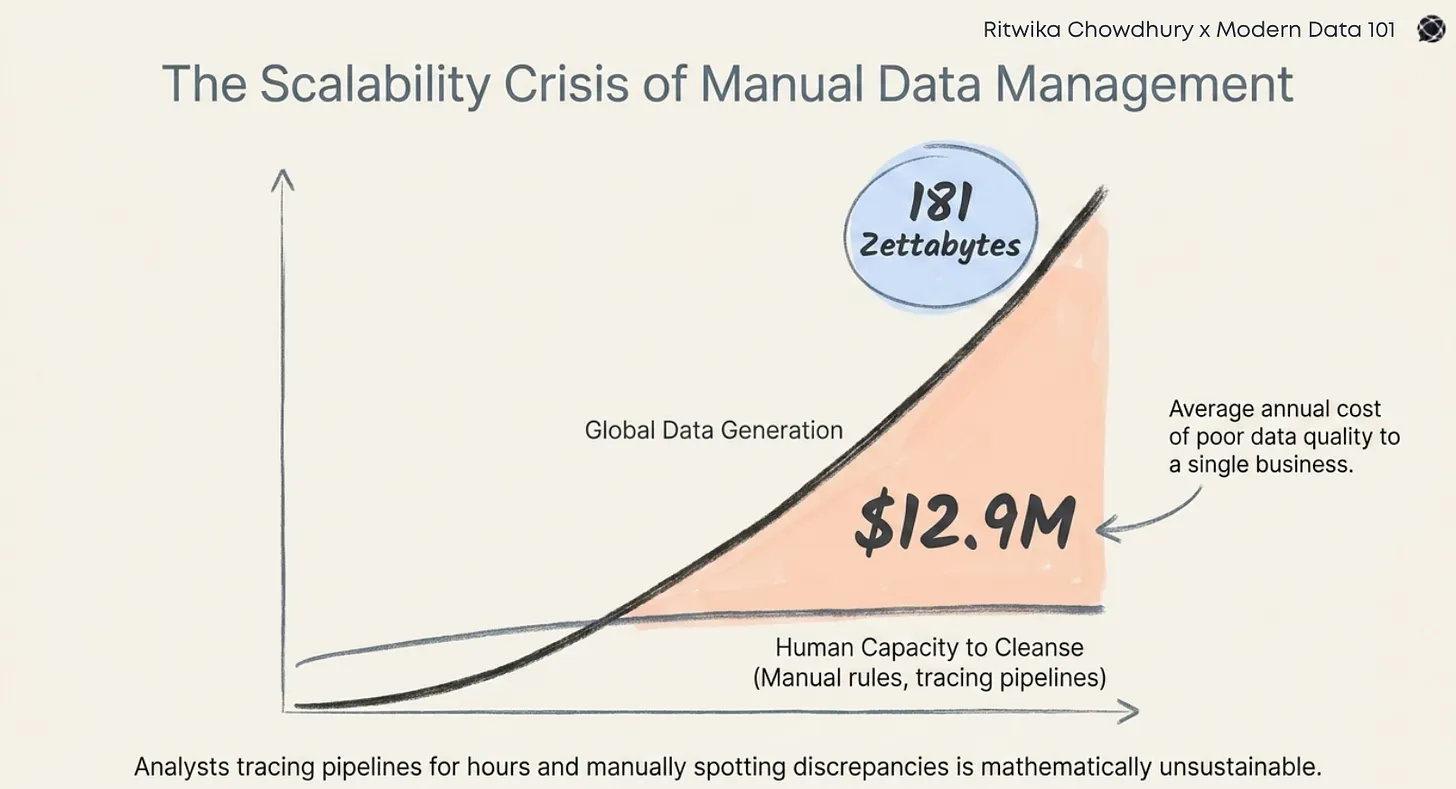
The need to manage data through a stack arises due to the vast volume of data being generated worldwide.
🎢Statista forecasts that the global data creation volume will breach the 394 zettabytes mark by 2028, further highlighting the need for an advanced stack with a high operations threshold.
Everything looks nicely sorted, but only in theory. As enterprises adopt this data stack, things change, and teams often go through multiple pipelines and platforms. While the intent was to streamline processes, the outcome led to the creation of new silos, such as increased complexity and fragmentation.
This is because teams in the same organisation use many tools for different data functions. While every tool has overlapping features, the interoperability attributes are far less than expected.
[state-of-data-products]
The result?
Redundant data pipelines, siloed workflows, and increased integration overheads, with significant implications in cost.
Intended to facilitate quicker insight generation, the modern data stack risks becoming a bottleneck because of some glaring trade-offs. For organisations looking to scale up their data and AI ambitions, having a clear understanding of the challenges of this data stack is crucial so that it becomes an ally and not a hindrance.
[related-1]
The data stack has been constantly evolving, but as mentioned above, some significant challenges keep it from reaching its full potential.
Tool fragmentation is among the most pressing challenges in modern data stacks today. A typical data stack consists of tools for ingestion, transformation, storage, orchestration, BI, machine learning, and reverse ETL, among others, with each tool having its own capabilities. This approach, however, creates an inflated ecosystem of multiple tools that are not even as tightly integrated as they should be.
This lack of interoperability between tools increases the overall complexity, and teams spend a lot of time integrating these tools properly rather than tackling actual business pain points.
Redundant workflows through tools with overlapping features create a lot of confusion in proper decision-making between teams. As a result, it becomes tough to manage configuration consistency, lineage, and access permissions.
Fragmentation leads to elevated operational complexity. How? Each tool requires its own set of monitoring, expertise, and configurations. This stretches data teams to their maximum limit, as they must maintain infrastructure, look after incidents, tune performance, and maintain uptime across the entire data stack.
One of the most significant problems with this complexity is its impact on overheads, which increases drastically. More tools create more pipelines needing debugging, increased integrations that need to be monitored, and the delegation of more tasks across different teams. A modular architecture becomes a tangled mess of excess responsibilities, slowing down things and putting everything at risk.
Enhanced data quality is a significant objective for any modern data stack. However, inconsistency in standard validation, ambiguity in data ownership, and pipeline failures lead to a loss of trust in the data. Without testing and observability, teams are always reactive to quality issues, looking at them only when they have influenced decision-making in a not-very-smart way.
Aspects like quality monitoring and data contracts are still in their emergent stage and are not integrated tightly into workflows. The result? Users are left questioning the timeliness, completeness, and accuracy of data. Without absolute trust to back things up, consequences are effort duplication, projects on hold, and dependency on manual spreadsheets. The value of the stack diminishes as a whole.
Metadata management is one of the most under-tapped aspects of the modern data stack. As new tools enter the data ecosystem, the metadata often bears the brunt, becoming dated or fragmented.
Metadata, in layman’s terms, is the context around data or the meaning and relevance behind it. The story of the data. What does the data mean? Where did it come from? How frequently does it arrive? Where does it sit, and who uses it? What can it be used for, and how frequently? And so much more…
In short, data has no value without metadata and falls into chaos. Not surprisingly, most organisations are sitting on loads of data that has no use because it is disjointed from the core semantic model. In popular lingo, this is called dark data. It is not so much the cost of storage, but the cost of money left on the table because of not leveraging rich, valuable data.
The three rules of metadata:
Consequently, the metadata collection process itself impacts the potential of the metadata. Collecting metadata is not enough, collecting it right is the point of priority.
Below is a comparative overview of two data collection methods.
Metadata is partially injected from disparate components that are externally integrated together. There's not much leeway for these disparate components to continuously interface or interact and thus generate rich metadata from dense networks.
This situation leads to the creation of metadata debt and is one of the biggest challenges for the modern data stack. It is the cost of unclear data definitions, lack of context, and poor discoverability levels, as data analysts spend considerable time locating and validating the data. Also, engineers must work around pipelines because the existing assets lack the required visibility.
The unified architecture is composed of loosely coupled and tightly integrated components that densely interoperate/network with each other and, in the process, generate and capture dense metadata that is looped back into the components on a unified plane.
The whole premise of any data stack revolves around increasing flexibility through tools. However, it has led to a lot of confusion when it comes to defining clear ownership across data teams.
Different tools for ingestion, transformation, orchestration, and other related functions lead to responsibility diffusion across different teams and roles. In the context of the end-to-end data lifecycle, there is a lack of accountability for each function. The fragmented architecture creates a lot of confusion, diluting accountability and cutting down the pace of issue resolution.
Effective data governance also suffers, as enforcing policies and data standards often trickles down through the cracks of team boundaries. The right data ownership needs more than just assigning names to datasets or dashboards to truly become an enabler.
As the volume of data increases, the associated risks witness a proportionate rise too. A report from Cybersecurity Insiders states that 91% of cybersecurity professionals felt that their systems were not ready to handle zero-day breaches or respond to newly discovered vulnerabilities. This shows that existing compliance practices are behind when it comes to progressive data stacks.
Yes, the tools in use have their own access controls, but without a hybrid governance framework, the chinks in the armour show up pretty soon. Issues such as inconsistent role access, weak audit links, non-compliance with standards such as HIPAA, and insufficient encryption creep up and weaken flows and pipelines over time.
It’s an ironic paradox that the data stack for unifying data ends up recreating those silos that were intended to be eliminated with this stack in the first place. This is because different teams have their own set of tools, pipelines, and processes, which leads to redundant workflows and inconsistent data access.
When data governance is weak, it leads to shadow workflows, where unauthorised datasets, undefined pipelines, and siloed dashboards are everyday challenges that go over defined governance controls, giving rise to compliance risks, duplicated logic, as well as reporting inconsistencies among others.
[related-2]
The modern data stack looked like a winning opportunity by bringing scalability, agility, and data democratisation to the fore. However, once organisations started adopting a wide range of tools, each offering narrow functionality in the process, the overall complexity put a healthy return on investment into question.
While speed and agility were crucial points in focus, the inclusion of too many disconnected tools led to disjointed integrations, new silos, and a dramatic increase in operational overhead.
The biggest challenge here is that it is not just the data teams that get affected, but the organisation as a whole. Users face delays in getting the right kind of insights, the trust in data gets diluted, and data governance becomes a reaction, instead of a proactive function. Yes, every tool does add a little benefit with its entry into the scheme of things, but costs pile up with monitoring, orchestration, and compliance.
The stack becomes ‘modern’, but the efficiency takes a hit along with the ROI. The time to get actionable insights increases as teams need to spend a lot of time bringing fragmented pipelines together rather than working diligently on securing positive strategic outcomes. To get the right value, there is a need for organisations to line up their data strategy in sync with product thinking principles. This is essential to create the right kind of business impact.
As organisations work around the complexity of the modern data stack, a version is being born where data takes priority over the different tools and architectural influences. This is the approach of a data-first stack, where the entire data ecosystem is crafted around the data lifecycle, accessibility, and value of the data, rather than just unifying it through different technologies.
The Data Developer Platform (DDP) is a self-serve infrastructure standard that is a pivotal element of this shift, as a framework that empowers teams to create, govern, and scale data products with a lot of efficiency. DDP is deeply rooted in self-serve principles, where each domain team can take up ownership without the need for specified infrastructure knowledge. The self-serve aspect is the one that transforms a data stack from a fragmented tool collection to a well-oiled machine.
There are quite a few important factors that come into play with a data-first stack:
[related-3]
The ‘modern’ in modern data stack is not just an adjective but a highlight that bends towards a self-serve platform that assists enterprises in data solutions at speed, becoming a necessity for the data mesh approach.
With this data stack, enterprises can leverage all their services and tools to their potential with the aid of standardised integration, access, resource optimisation, and other low-priority complexities. All of this is made possible through the Data Developer Platform (DDP).
It allows development teams to build and deploy applications with ease through a set of tools and services so that data can be managed and analysed in a better manner. The unifying capability of a DDP is one of its biggest strengths, offering a single point for complete management.
The message is clear: the challenges with the modern data stack are significant, but a thought process ingrained in data-first philosophy can be integral in solving them.
[data-expert]
2025 is brimming with new opportunities, greater specialisation in AI for industries, deeper integration of autonomous systems, and a surge in demand for real-time, privacy-conscious solutions. This year isn’t just about smarter AI but more about AI that acts, adapts, and delivers tangible value across every domain.
2025 will surely see some awesome updates in data engineering, with new tech updations knocking on our door almost daily, mergers, acquisitions, and funds in the space hint towards a brighter future.
Traditional stacks are centralised, rigid systems that are designed mainly for reporting and batch analytics. These rely on heavy ETL, tight coupling, and IT-led control. Modern data stacks are modular and self-serve, enabling teams to build and manage data products independently. They use ELT, real-time pipelines, open APIs, and shared semantics, making data reusable, AI-ready, and aligned to business outcomes.
A modern data stack powers a wide range of use cases; from real-time analytics and customer 360 views to AI model training and data-driven automation. It enables faster experimentation, self-serve insights, and domain-aligned data products that support everything from operational reporting to AI copilots and intelligent decision systems.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




