


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)

TABLE OF CONTENT



Data quality directly shapes what gets done, how fast decisions are made, and what doesn’t move at all. When cracks in trust develop, decisions are delayed, escalations rise, and new initiatives are deprioritised because no one wants to take a bet on unstable data.
We often reduce data quality to tooling or architectural rigour. But those are surface levers. At its root, quality is a cultural device.
It reflects how an organisation thinks about accountability, ownership, and how feedback loops across its data systems.
The presence or absence of quality is a downstream effect of culture: who gets looped in when issues emerge? Who holds the context of what “correct” should look like? Who has the agency to fix, and how fast can they close the loop?
Despite the sophistication of our stacks, data quality is still primarily treated downstream: validated at the reporting layer, patched manually, and carried forward like operational debt. This is not a tooling gap. It’s an organisational blind spot because data systems evolve faster than the cultures that use them.
The shift forward isn’t only an architectural bend but like closing a cultural gap: how we choose to distribute trust, responsibility, and signal at every layer of the stack. How do tools, processes, and people become part of this dynamic?
A high-stakes boardroom, a seasoned analyst presenting quarterly performance, and a single cell in the dashboard that doesn't align with the CFO’s office. The room shifts. The meeting spirals into suspicion instead of strategy. Did Marketing misreport? Did Sales overcommit? No one knows.
What should’ve been a conversation about the future becomes an autopsy of the past.
That one moment, seemingly small, is a rupture in trust. And like most cracks in trust, it doesn’t announce itself until it’s already too late.
Data quality issues aren’t just technical misfires. They’re fractures in the trust fabric of the organisation. When even one stakeholder suspects the numbers aren’t solid, momentum halts. Decisions become tentative, and confidence once broken, is slow to rebuild. The tools might still hum in the background, but the culture grows cautious, sceptical, and distant.
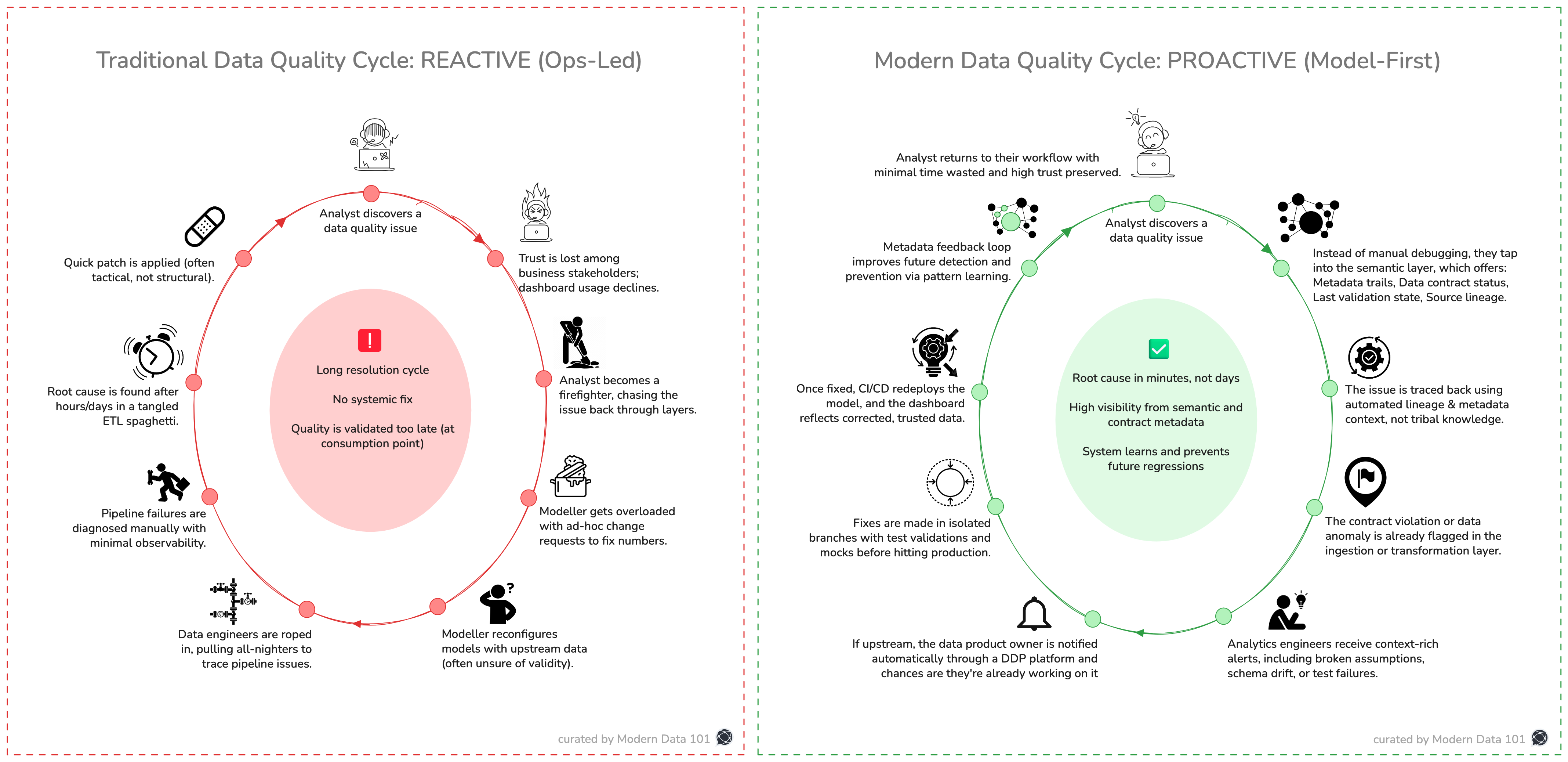
Most data quality mechanisms have been patched up instead of being designed. What we call data quality today is often a scattered response to the moment things go wrong. It begins when someone downstream (often an analyst) spots a discrepancy. The numbers aren’t what they were yesterday, or don’t line up with another dashboard. That’s the cue to start tracing, not from a known root, but from a midpoint.
The dominoes start falling. Queries are retraced, pipeline logic is reviewed, and fingers point in multiple directions before anyone gets close to the root. Fixes, when found, tend to be local and undocumented.
What’s interesting is how normalised this firefighting has become. Teams brace for it, design around it, even build informal networks to flag it faster. But this normalisation hides the deeper cost: trust. Not just between data and decision-makers, but across every layer of the data system. It becomes difficult to improve something when your entire process is structured to avoid blame rather than surface design flaws.
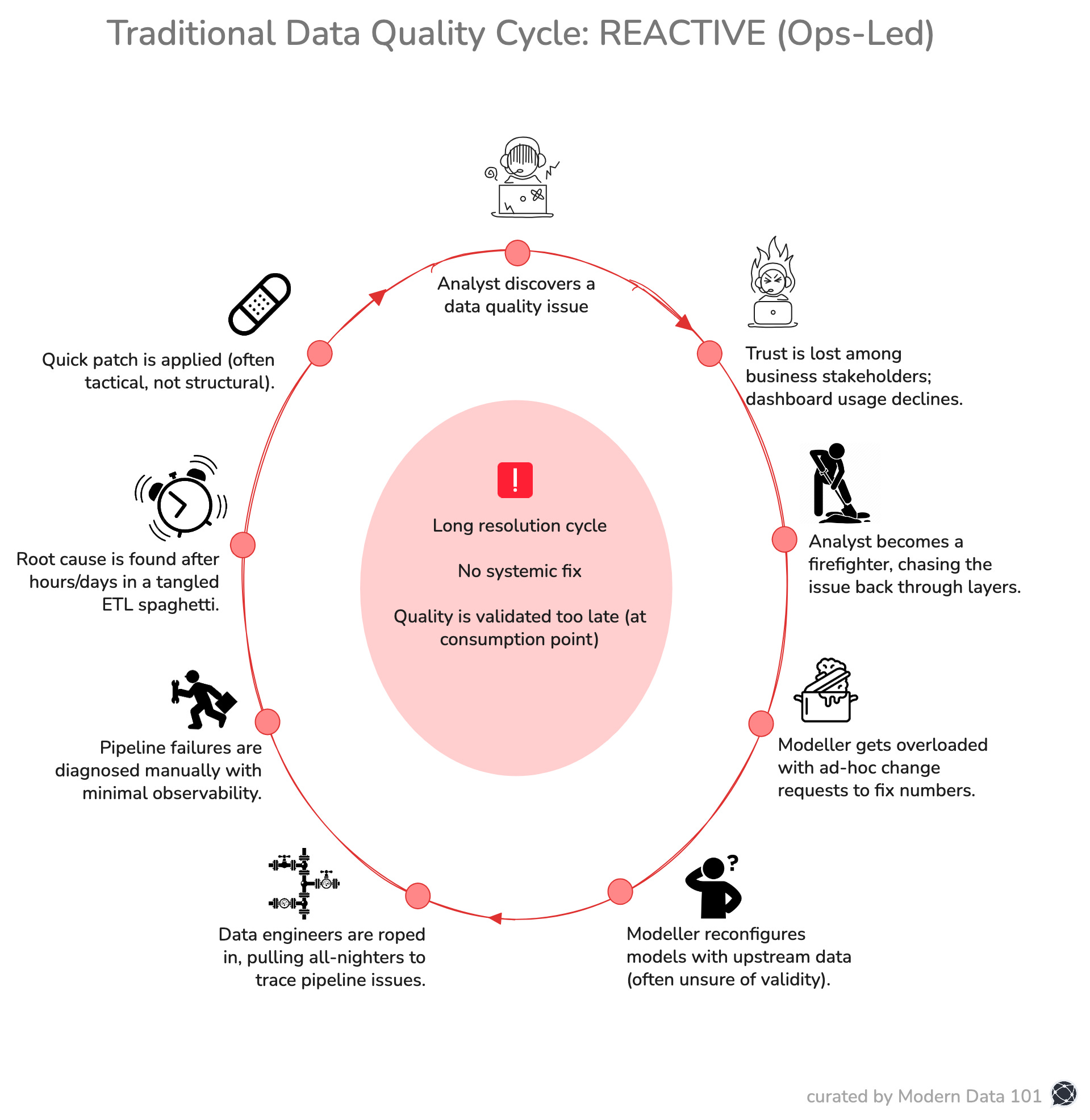
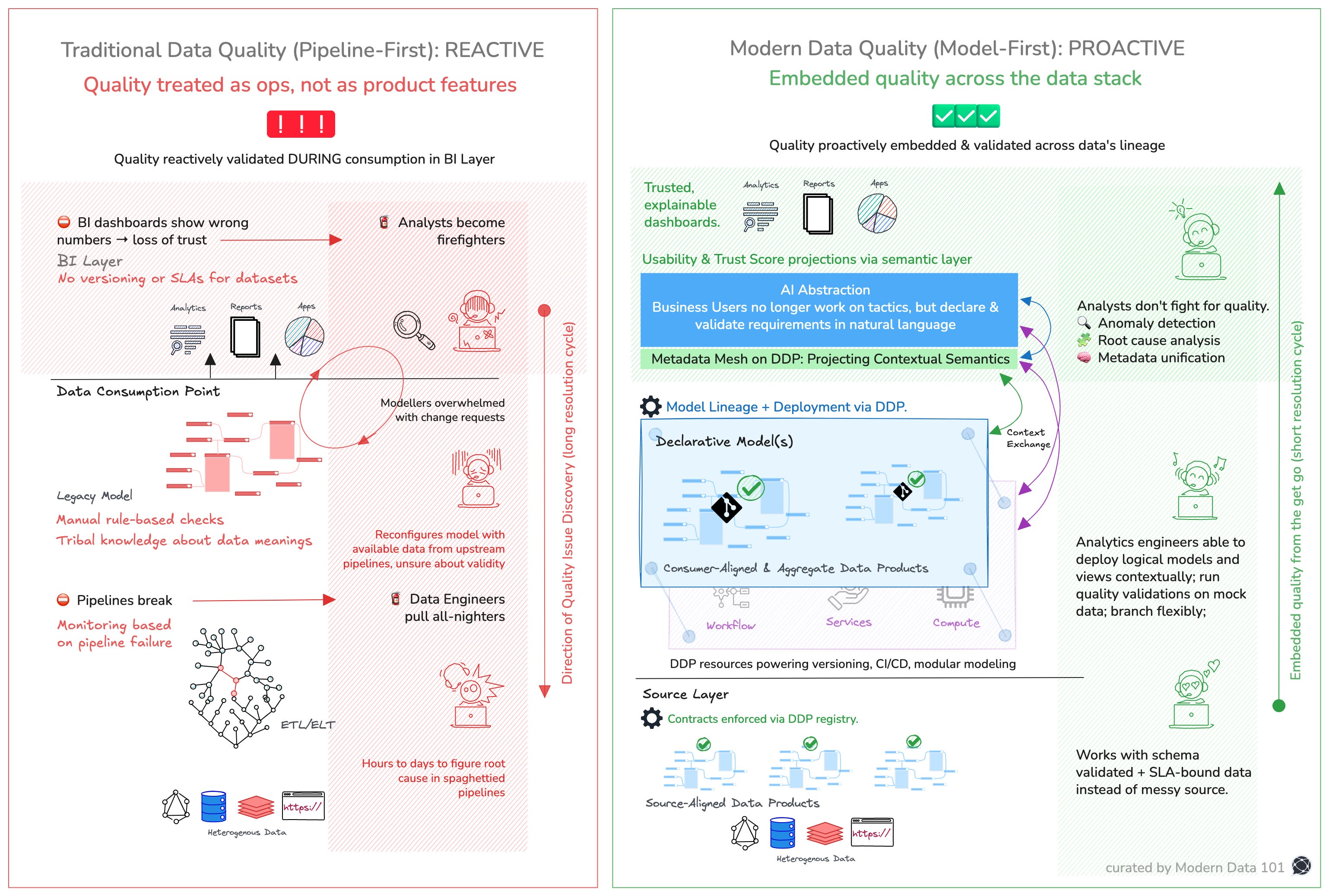
Traditional data quality management is reactive and fragmented. The entire process treats quality as an operational issue, not as an integral part of the product development lifecycle.
Data sources feed into pipelines, which are monitored for failures rather than the accuracy or trustworthiness of the data. When something breaks, data engineers are alerted and must dig through complex, often undocumented pipelines to identify the root cause. This can take hours to days.
In the traditional left-to-right data engineering, modellers rely on incomplete or potentially flawed data from these pipelines. With no clear validation structure, they’re forced to make quick changes based on limited information. This creates further risk of inaccuracies.
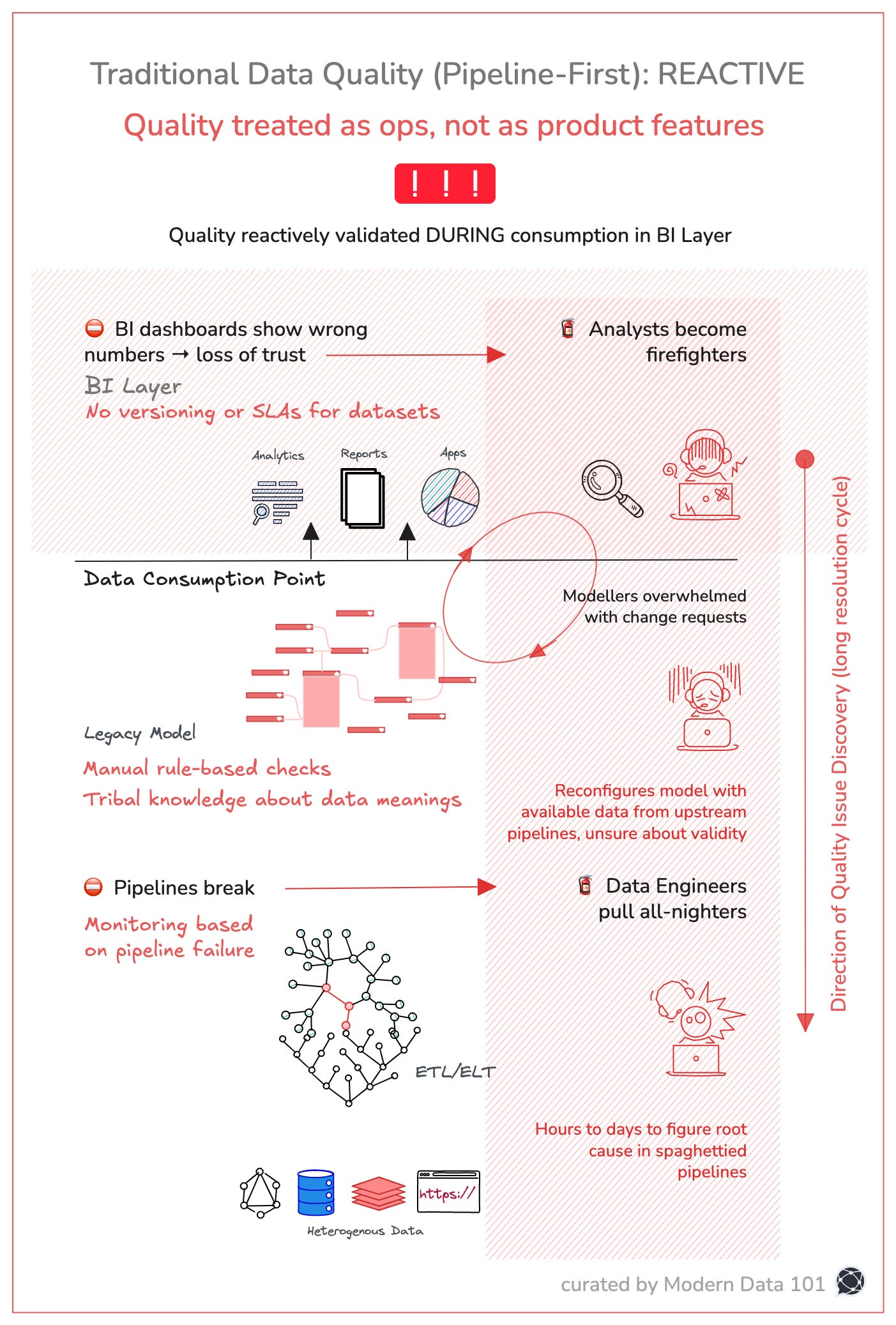
At the consumption layer are BI dashboards and reports that start showing incorrect numbers, which business stakeholders actually see and deploy for high-stakes decisions. There’s no version control or SLAs for the datasets, so errors go undetected until they reach the end-user. At this point, analysts step in to investigate but often end up acting like firefighters, addressing symptoms instead of root causes.
The key takeaway is that this entire cycle leads to a loss of trust in data because issues are caught at the point of consumption rather than production.
Fixing them is slow and painful, and it keeps happening again and again.
This is a feedback loop of dysfunction. A system where data quality is validated after damage has already occurred. Where insight is downstream of trust, and trust is the first thing to break. Dashboards lie because the system below them offers no guarantees. Analysts spot issues too late and scramble into damage control.
This pattern is less about broken tools and more about the broken model of ownership.
Quality is treated as an ops concern, not a feature of the data product itself. There’s no agreement between producers and consumers.
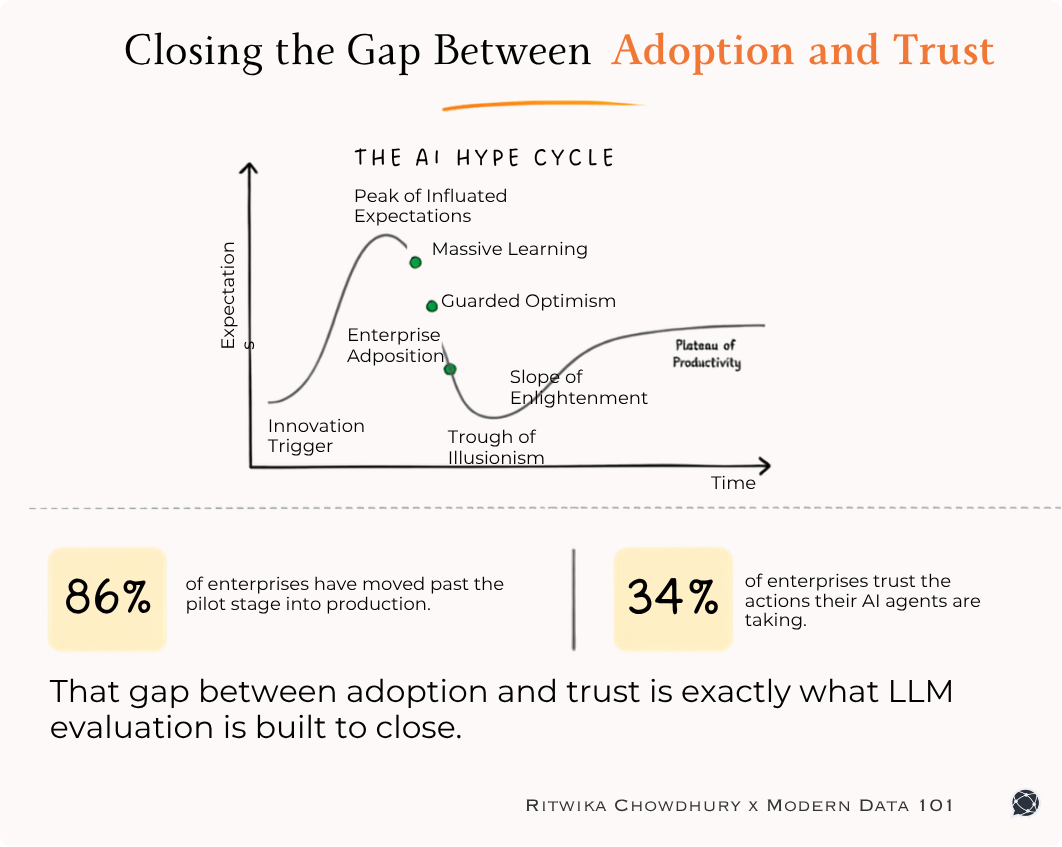
We often mistake adoption as the outcome of data quality, as if you build clean, validated, well-modelled data and users will naturally flock to it. But the reality is more nuanced, and far more critical: data quality doesn’t just enable adoption, it requires it.
Quality, in the absence of adoption, is performance art. You can write contracts, enforce tests, build rigorous lineage maps, and validate every column in a model, but if no one is actually using the output, none of that rigour translates into value. It remains theoretical: a solved problem in a sandbox that never met the complexity of real usage.
Jobs would often say something along the lines of, “what I build today is irrelevant tomorrow.” His model is consistently creating versions and consistently building quality on top of the previous versions; not waiting to bring the users into the picture until the technology is perfect.
Adoption is what makes data quality real. When people actively use data products, when dashboards drive decisions, when semantic layers become default entry points, when business logic meets actual business pressure; only then does the system encounter friction.
Friction is the great revealer.
It exposes where your assumptions don’t hold, where edge cases emerge, and where metadata doesn’t communicate intent clearly enough. It forces the system to adapt. This feedback loop is where quality becomes dynamic. A transition from a frozen set of validations to a living system that learns and evolves with its users.
Without adoption, your quality frameworks never encounter the reality they’re meant to support. Contracts are never challenged, tests never reflect shifting context, and semantic layers don’t surface new patterns of interpretation. You’re optimising in the dark.
But when adoption is high, every part of the system becomes responsive: model tests are informed by real-world usage, data contracts evolve alongside operational needs, and metadata grows richer through interaction.
Adoption becomes the engine that keeps quality relevant, contextual, and defensible.
AI scales adoption beyond the technical early adopters to the entire organisation. By translating human intent into semantic queries, AI removes the technical barriers that block most users from engaging with data directly. Users no longer need to navigate complex queries or models; they ask in their own language and receive trustworthy, contract-backed answers.
This reduces cognitive friction and dramatically widens the trust and usage. AI, as has been widely experienced, personalises context which helps users from different corners of the data web navigate, leverage, and improve data quality, irrespective of their technical expertise.
In essence, AI abstraction acts as an amplifier for adoption. It makes data quality accessible and actionable at scale, turning latent potential into active usage. When combined with rigorous modelling and contract enforcement in a Data Developer Platform (self-serve platform standard), it creates a virtuous cycle: more adoption leads to richer metadata and more feedback, which sharpens AI understanding and quality enforcement, and that, in turn, drives even broader adoption.
So the question isn’t just “is our data high quality?” The better question is, “Who trusts it enough to use it, and how does the system enable that trust at scale?” Because trust is a behaviour. And quality isn’t something you install but something you earn, through systems that meet users where they are, and improve because they’re used.
Adoption doesn’t come from dashboards alone. It comes from trust. From usability. From systems that meet humans where they are, without dragging them through pipelines, schemas, and code.
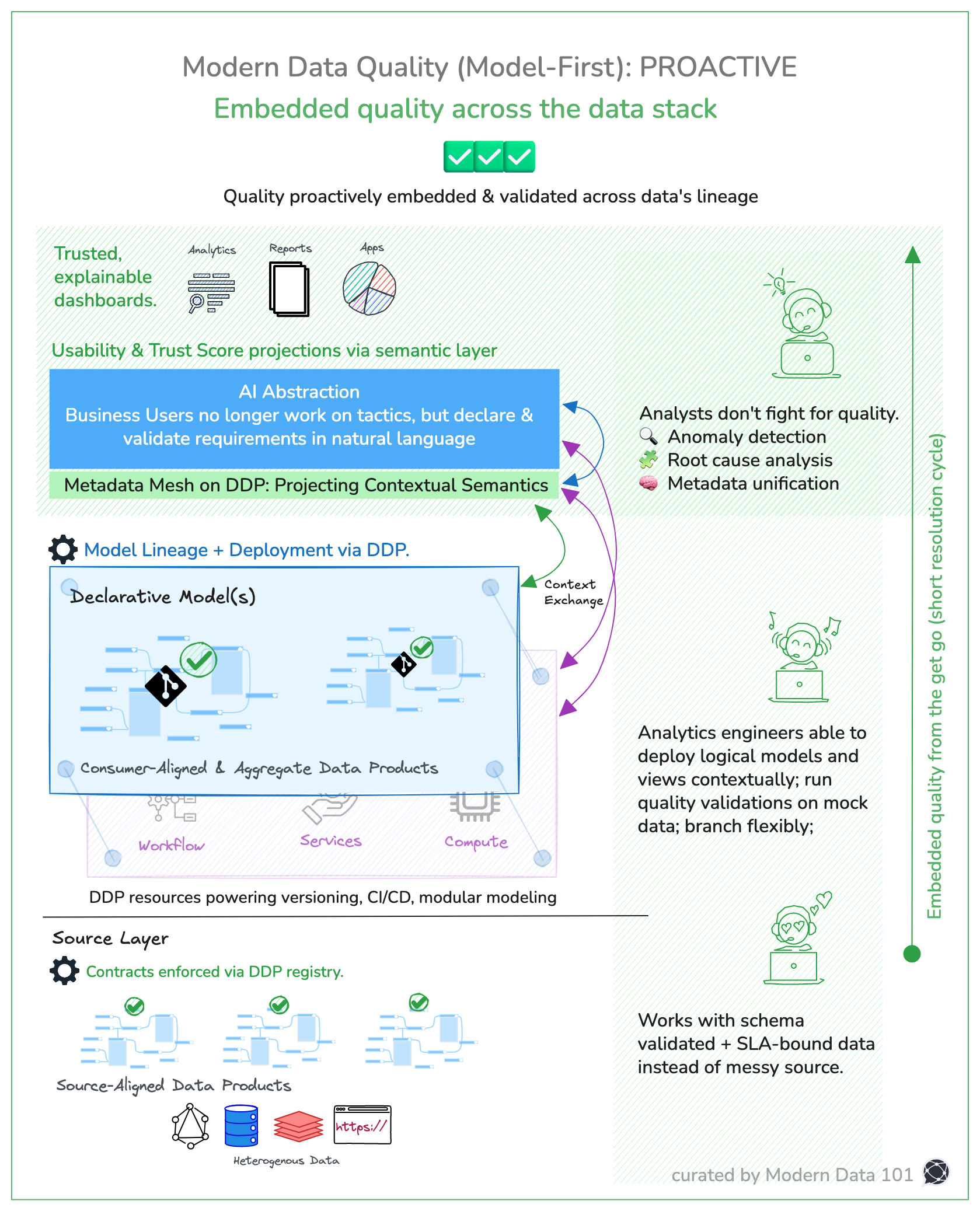
If Fork 1 shows us how AI breaks down barriers to adoption, Fork 2 reveals how data products power that AI and vice versa through a dynamic relationship with the semantic layer. Data products don’t just deliver static datasets; they are living, interconnected entities that both consume and enrich semantic context.
At its core, the semantic layer is the shared language and lens through which data products become meaningful and actionable. Data products push context continuously into this layer: business logic, definitions, and dimensional relationships; to shape multi-dimensional context cutting across products, domains, and use cases. The result is an interoperable fabric of meaning, where each data product’s lineage and logic connect with others, enabling trustworthy advanced analytics.
The semantic layer also feeds back into data products: a context mirror reflecting how users interpret, query, and rely on data. This feedback helps data products refine their contracts, tests, and assumptions in real time, making quality a living, breathing property, not a checkbox.
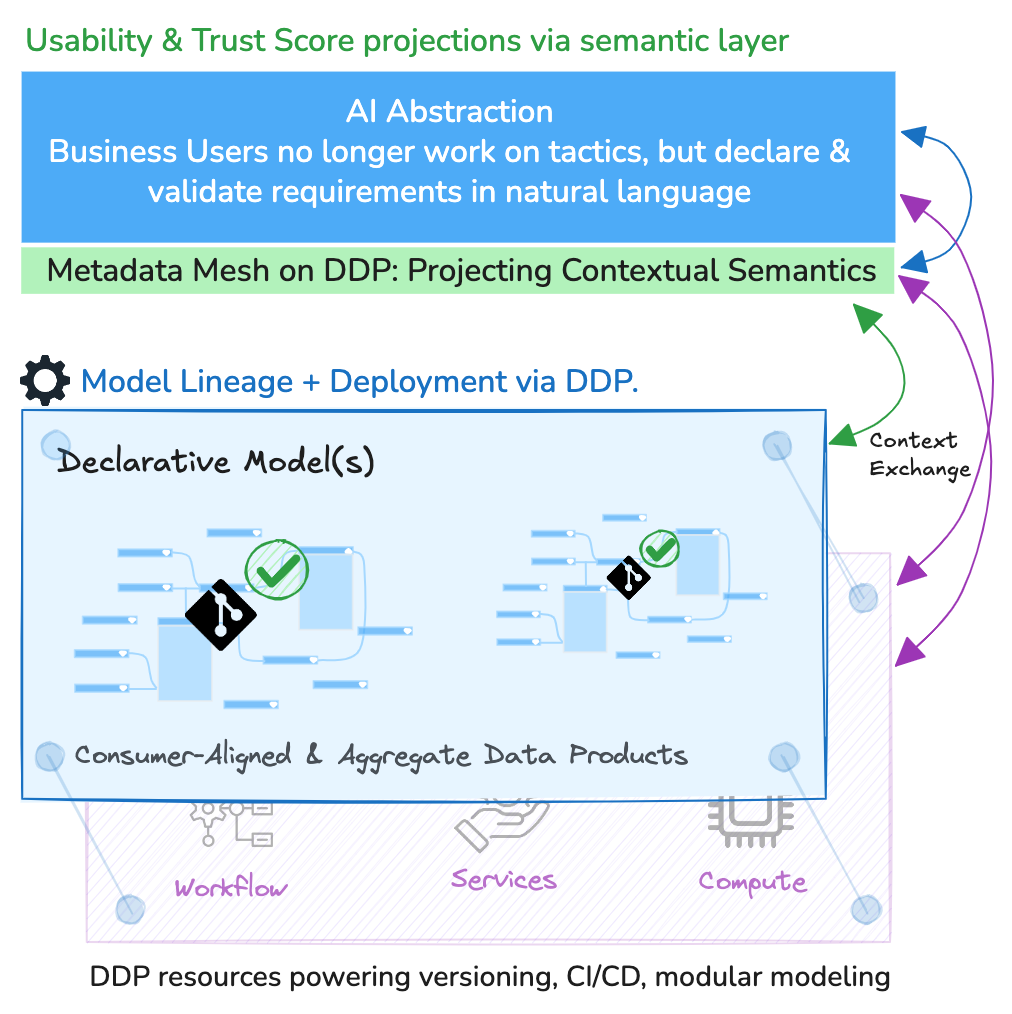
Now, when you fold AI abstraction into this mix, the synergy becomes more powerful. The AI layer both consumes semantic context, understanding business definitions, data contracts, and relationship graphs, and shares context derived from natural language inputs, queries, and conversational interactions.
This two-way feedback means AI doesn’t just answer business queries; it augments the semantic fabric by injecting user intent, clarifying ambiguous queries, and even suggesting new dimensions or relationships based on interaction patterns.
This creates a powerful cycle:
In other words, data products become context-aware collaborators: active participants in an evolving ecosystem where AI and humans co-create understanding and trust.
This dynamic interplay is what scales adoption organically. It shifts data quality from being a static, siloed goal to becoming an emergent property of an integrated system that learns, adapts, and grows with every interaction.
If Fork 1 spotlighted AI’s role in scaling adoption, and Fork 2 unpacked the role of user-driven Data Products, Fork 3 dives deep into the foundational infrastructure: the Data Developer Platform (DDP) (a self-serve data infrastructure standard) that powers this ecosystem.
This platform is not an afterthought or a nice-to-have; it’s the engine room where quality, trust, and agility are born and sustained.
The first fundamental is modularity.
Models, data products, and resources in the DDP aren’t monoliths; they’re composable building blocks that are versioned, tested, and maintained independently. This modularity allows rapid iteration without risking entire pipelines and complex dependencies. Data engineers can branch, mock, and validate changes in isolated environments. It creates a culture of safe experimentation. Better quality doesn’t come from static gatekeeping but from continuous evolution and adaptation.
Data contracts in this platform aren’t vague guidelines or documentation buried in wiki pages; they are real, enforceable artefacts integrated directly into CI/CD pipelines. Schema checks, SLA verifications, and behavioural contracts trigger automated tests and alerts. They catch drift, broken assumptions, and anomalies at the earliest points, often before data surfaces in consumption layers. These contracts embody shared expectations between producers and consumers, creating clear accountability that scales as organisations grow.
Metadata, often an afterthought in legacy stacks, is first-class here.
The platform treats metadata as a strategic asset: richly contextual, interconnected, and dynamic. It powers the metadata mesh, a living graph that maps semantic relationships, usage patterns, lineage, and data quality signals across the entire ecosystem. This mesh is the nervous system that enables seamless communication between models, semantic layers, AI abstraction, and data products. It provides the transparency and observability necessary for proactive quality management and trust-building.
CI/CD is the default operating mode.
Every model change, contract update, or semantic modification flows through automated pipelines that validate, test, and deploy changes safely and quickly.
In sum, DDP empowers teams to build Data Products with confidence, fuels the semantic layer with reliable, modular inputs, and sustains a metadata mesh that keeps trust alive across scale and complexity.
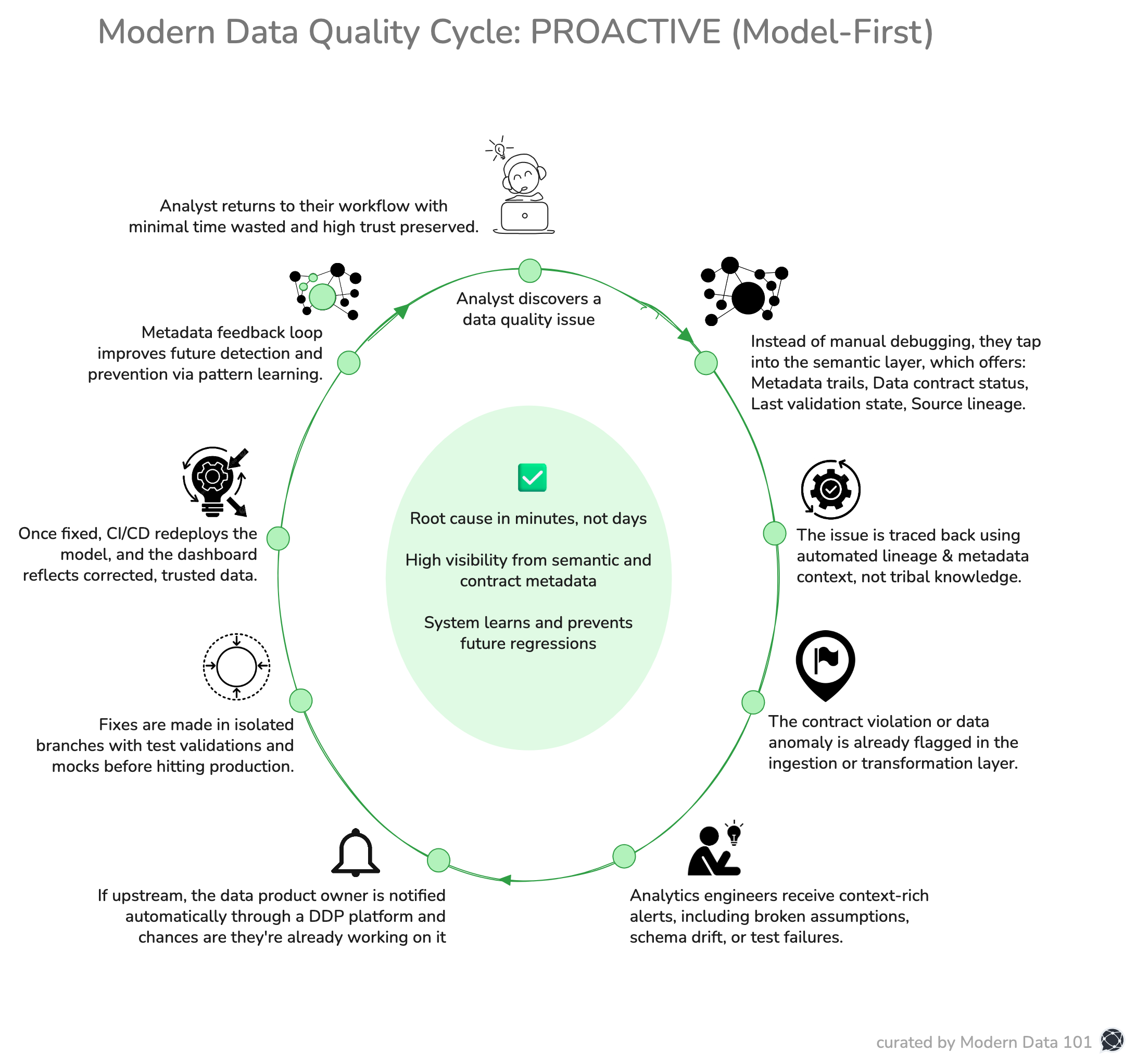
When we kick off the cycle with the same problem: the analyst discovering a data quality issue or misalignment, this is how it plays out with the trifecta in place.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.

From The MD101 Team 🧡
Here’s your own copy of the Actionable Data Product Playbook. With 2500+ downloads so far and quality feedback, we are thrilled with the response to this 6-week guide we’ve built with industry experts and practitioners. Stay tuned on moderndata101.com for more actionable resources from us!

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



