



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...




%20(1).png)
TABLE OF CONTENT


%20(1).avif)

Enterprise knowledge is often not searchable.
When people talk about improving LLM accuracy, they usually focus on better embeddings, faster vector databases, or more advanced prompting techniques. Those help, but none of them solves the core issue: enterprise knowledge is more than sets of of independent text chunks. They are often a dense network of relationships.
Most enterprise information is produced in fragments, such as documents describing systems, but their reference decisions were made three years ago. Or, a policy that depends on definitions buried in a separate knowledge base.
Siloes like:
Traditional RAG treats these as isolated items to be retrieved by similarity. But in a real organisation, their meaning comes from how they connect.
Where’s the gap?
For most enterprise AI deployments, the most prevalent problem is LLMs finding texts that look relevant but miss the dependencies that matter. Answers sound correct, but conflict with decisions recorded elsewhere. In a 2025 study on clinical questions, the best model was confidently incorrect 40% of the time.
Retrieval surfaces partial or outdated fragments, and information spread across teams never recombines when the model needs it. The model isn’t hallucinating, but the data is fractured.
This article will discuss how GraphRAG fixes this by adding a knowledge graph layer that captures the relationships the enterprise relies on but doesn’t store in any searchable form. Instead of retrieving isolated passages, it retrieves the connected context around them.
[data-expert]
The shift is simple but consequential: from finding similar text to assembling the knowledge that actually answers the question. That move from similarity to structure is what improves LLM accuracy on complex private data.
GraphRAG is a retrieval-augmented generation technique that represents documents as knowledge graphs instead of vector embeddings. Rather than breaking text into chunks that get searched independently, GraphRAG extracts entities (think like people, organisations, concepts, events) and the relationships between them, organising this information into an interconnected graph structure - Source
GraphRAG, as a retrieval approach, enables leveraging the capabilities of a knowledge graph with a traditional RAG built from enterprise content, giving the model structure instead of loose text fragments.
Think of our most popular LLMs like ChatGPT, Claude, and many others. These are mostly trained on broad public data. So these don’t know what’s in a specific private dataset unless it’s explicitly included. To work around this, leveraging Retrieval-Augmented Generation (RAG), where the system looks up relevant pieces of a dataset and feeds those to the model before answering a question, is the most convenient way out.
However, traditional RAG systems have limitations:
[playbook]
The biggest misconception about GraphRAG is that it somehow makes the LLM “smarter.”
It doesn’t.
What it actually does is make the retrieval layer smarter, and that’s what improves the LLM’s accuracy.
Traditional RAG retrieves text based on similarity. GraphRAG retrieves knowledge based on meaning because it understands how concepts relate. When a user asks a question, the system doesn’t just return close-matching paragraphs; it returns a connected set of facts, across documents, stitched together via the knowledge graph.
This leads to more relevant context, fewer hallucinations, better grounding, and stronger multi-hop reasoning.
The LLM is actually following breadcrumbs.
One of the biggest hidden advantages of GraphRAG is the ability to surface insights that aren’t obvious from raw text.
As GraphRAG sees relationships, it helps:
Imagine asking a question that spans five documents. A vector database might match one or two of them. A knowledge graph can traverse through all five, retrieving a structured explanation instead of five isolated text snippets.
This is where GraphRAG shifts from being a retrieval system to a knowledge exploration system.
[related-1]
Building a high-quality knowledge graph often doesn’t require expensive LLM calls. Using lightweight techniques such as dependency parsing, you can construct a graph that performs almost as well as an LLM-built graph, roughly 94% of the performance at a fraction of the cost.
This is important as GraphRAG is no longer just a research toy or something only FAANG-scale companies can afford. It’s practical. It’s scalable. And it works.
Multiple independent studies show that RAG systems augmented with a knowledge-graph layer consistently outperform text-only RAG on tasks where relationships, dependencies, or multi-hop context matter, providing empirical support for GraphRAG across methods and domains.
Imagine your company has thousands of internal engineering documents spread across teams and systems. Now someone asks:
“Which internal services will be affected if Service X goes down?”
With traditional RAG, the system might find documents that mention Service X, but it has no reliable way to surface everything that depends on it. You may get high-level architecture notes, partial references, or outdated diagrams, but not the full picture. The retrieval is limited to whatever text looks similar to the question.
With GraphRAG, the dependencies are already mapped. The knowledge graph captures the services and the relationships between them, so the system can follow those links and identify every downstream impact. Instead of guessing based on keywords, it uses the structure of your own data to assemble a complete view.
The LLM then takes that connected context and turns it into a clear explanation of what will break, why it will break, and where the risks are. The result is a system-level answer that reflects how your organisation actually works, not how the best-matched paragraph happens to describe it.
[related-2]
The ultimate success for any organisation is measured by the real business numbers in terms of its north star goals being achieved. A shift from traditional RAG to GraphRAG delivers tangible, measurable business impact across accuracy, cost efficiency, productivity and decision quality.
GraphRAG reduces “best-guess” answers by grounding responses in structured relationships. This leads to significant improvements in accuracy for multi-step, cross-document, or system-level questions.
Unlike traditional RAG, which often retrieves only fragments, GraphRAG ensures the model captures all relevant connections, such as dependencies, impacts, timelines, ownership, and risks. Hence, leaders get complete context instead of isolated snippets.
Graph operations quickly surface the right subset of knowledge. This helps reduce time wasted digging through long documents or running multiple follow-up queries. Teams move from hours of research to seconds of precise analysis.
Instead of constantly fine-tuning vector search, the knowledge graph becomes a durable asset. Updates are incremental and easier to govern.
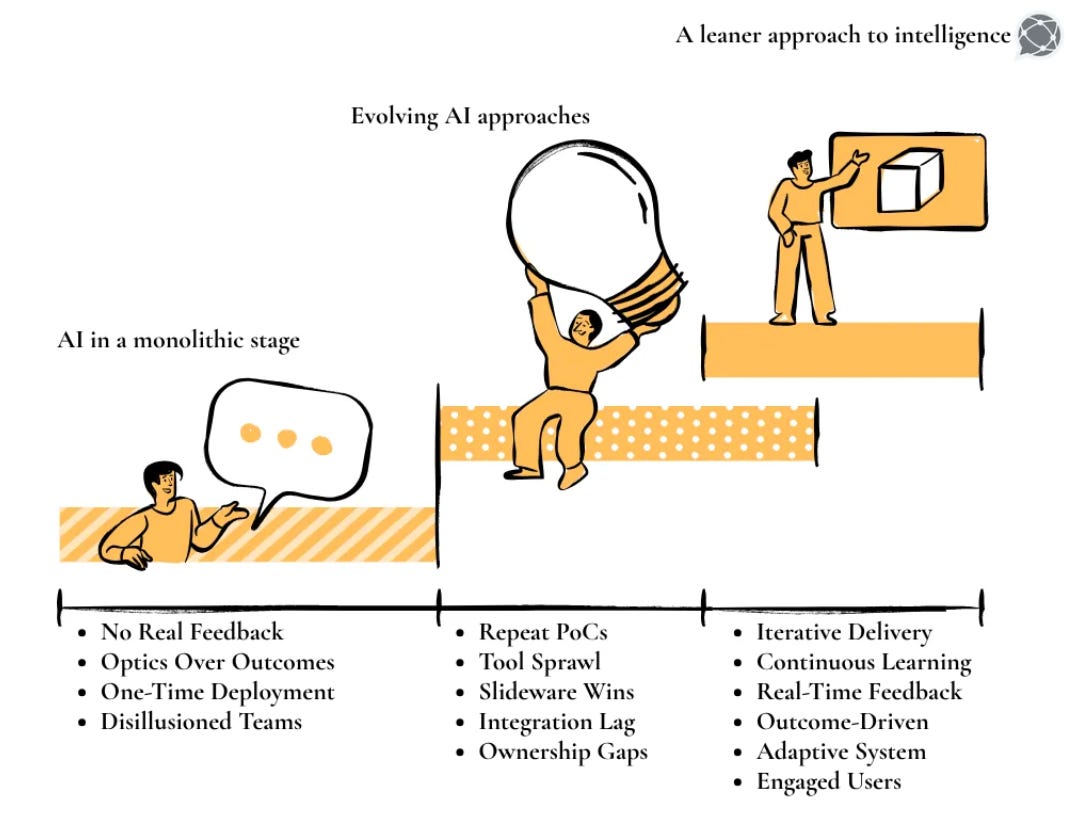
If the problem is fragmented knowledge, and traditional RAG can’t reliably recover the connections that matter, the next step is obvious: rebuild retrieval around structure, not similarity. That’s where GraphRAG comes in, enhancing conventional RAG.
By turning documents into a connected graph of entities and relationships, GraphRAG gives the retrieval layer the one thing enterprises have always needed but never documented well: context. The rest of this article walks through how GraphRAG works, why it improves accuracy, and what it changes for organisations that depend on AI to make sense of their private data.
GraphSAGE is used to generate embeddings for nodes in large graphs by learning from a node’s neighbourhood rather than the entire graph. It’s designed for tasks like node classification, link prediction, and recommendation, especially when graphs are too big to fit into memory or change over time.
GraphRAG supports three retrieval workflows, each designed for a different type of question:
Global Search: For questions that need a corpus-wide view. It summarises themes and patterns across the entire knowledge graph.
Local Search: For questions about a specific entity. It retrieves the entity, its neighbours, and all connected facts.
DRIFT Search: For mixed questions that need both breadth and depth. It starts with a global context and then drills down into relevant local details.
Baseline RAG (Retrieval-Augmented Generation) is the standard approach where an LLM answers a question using external documents retrieved by semantic search. The system breaks content into chunks and embeds them into vectors to help find the chunks most similar to the user’s query, and feeds those into the model as context. It’s simple, practical, and widely used, but it treats each chunk as an isolated piece of text, which is why it often misses deeper connections in enterprise data.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



.avif "Brij Mohan Singh")