


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



Why Data Movement Needs a Rethink
The Problem: Legacy Ingestion at Scale
- The Triple Squeeze on Data Teams
- Common Challenges of Data Movement
- Broader Operational Complexities
The Shift: The Principles of Modern Data Movement
How a Data Movement Engine Embodies the Principles
The Architecture of Modern Data Movement
Deep-Dives into Modern Data Movement Patterns
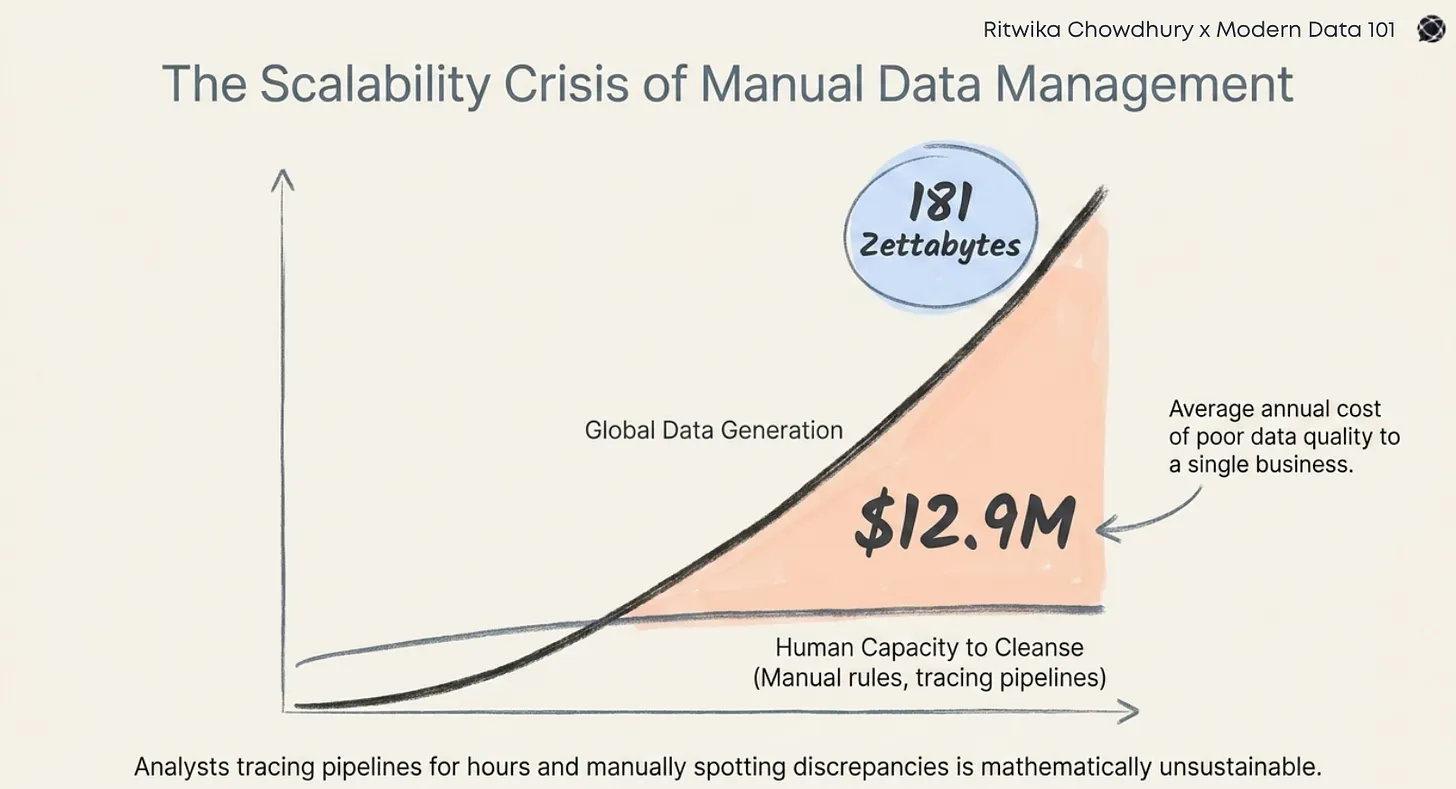
Data used to be simple: a handful of databases, nightly batch jobs, and reports waiting in the morning. Today, that world is invalid. Today, every enterprise is drowning in sources that won’t stop multiplying: relational databases, SaaS APIs, log files, event streams, you name it. Each comes with its own quirks, schemas, and update patterns.
At the same time, the patience window has collapsed. Business stakeholders don’t want yesterday’s snapshot, they expect dashboards that refresh in near-real time. Product teams want features powered by streaming data. AI initiatives demand low-latency, constantly refreshed context. SLAs rise, and tolerance for lag drops to near zero.
We’ve thrown brute force at this problem before. The Spark-era mindset was: spin up clusters, crunch everything in sight, reload the warehouse from scratch. But that model doesn’t scale when your sources are infinite, your SLAs are tighter than ever, and your cost curve is under constant pressure.
This is why the centre of gravity has shifted. Modern data movement is not about “big batch compute.” It’s about:
That’s the new playbook. Without it, everything else, like your analytics, your AI, your customer experience, suffers.
Start from first principles: what is data movement for? At its simplest, ingestion moves state (records, facts, events) from places that produce truth (databases, SaaS apps, logs, streams) to places that consume truth (analytics, models, OLAP, downstream apps).
Two immutable constraints govern this transfer:
Everything else (connectors, formats, scheduling) is an engineering answer to those two questions, plus a third practical requirement:
Legacy ingestion assumed different priors. It assumed sources were few and stable, that overnight freshness was acceptable, and that compute was cheap enough to batch-and-crunch. Those priors no longer hold. Once you reduce the problem to its fundamentals, the failure modes become obvious and inevitable.
From those fundamentals, we can derive three pressure points that together break the old model.
The number and variety of producers exploded. It’s no longer just a couple of OLTP databases; it’s SaaS APIs with pagination and flaky auth, event streams with high cardinality, files with occasional schema drift, and transactional stores that need per-row fidelity. Each source has different semantics for change and different expectations for correctness.
Consumers don’t want a midnight snapshot anymore. Product features, real-time metrics, and AI models expect low-latency context. That collapses the acceptable time window for movement and forces you away from monolithic nightly jobs toward more continuous, incremental approaches.
Compute and storage are not infinite, and every naive scaling move shows up on the bill. The old reflex (spin bigger Spark clusters, redo the whole table) quickly becomes unaffordable when multiplied across dozens or hundreds of sources.
These three forces: complexity, latency, and cost, aren’t independent nuisances. They compound: more sources increase the work per unit time, tighter latency forces more compute concurrency, and that in turn multiplies cost. That is the structural squeeze data teams live inside.
If you translate those pressures into day-to-day work, a few predictable problems appear. Each one is the logical consequence of violating a fundamental constraint above.
Take cost first. Legacy Spark-footed architectures were built to process everything in bulk; they accepted the shuffle and orchestration tax as part of the workflow. But when your job is “move a small delta” and you still pay a cluster’s tail, every efficient pattern erodes under a fixed overhead. The math of small changes plus big clusters is unforgiving.
Now look at extensibility. When adding a source requires touching the core Java ingestion codebase, you’ve created a high-friction gate. Fundamentally, integration should be an interface, not a platform-team project. If the path to connect is long and centralised, velocity collapses, and connector work becomes a backlog item rather than an enabler.
APIs are a different kind of problem: they break the assumption that all sources are pullable with SQL-like semantics. SaaS systems require auth flows, token refresh, pagination, rate-limit handling, and bespoke error handling. Treating APIs as “just another JDBC” is a category error that manifests as flaky jobs and missed data.
Ecosystem lock-in follows from the same roots. When pipelines are designed to land only into a single “depot,” you trade short-term convenience for long-term brittleness. The fundamental requirement is portability of state: the ability to land data where downstream compute or storage makes the most sense. Locking the sink violates that requirement.
Finally, the absence of native CDC is simply a mismatch of model to reality. Systems change at the row level; polling and full refreshes treat change as a blunt instrument. The logical solution is an incremental-first approach that captures what changed and preserves the before-and-after context; anything else is an engineering concession that will cost you time or money (usually both).
When you step back, these problems create a second-order effect: operational entropy. Systems that were meant to be ephemeral become permanent fixtures because they contain business logic and edge-case handling nobody owns. That is how scripts calcify into critical infrastructure.
Two specific dynamics explain why operational complexity escalates.
Put another way: legacy ingestion fails not because engineers are careless, but because the early design choices violated the problem’s first principles. We treated transient engineering shortcuts as if they were architecture, and the bill for that misalignment has come due: in fragility, cost, and lost velocity.
If legacy ingestion failed because its assumptions no longer matched reality, the way forward is to rebuild from principles that do. Each principle follows directly from the constraints of time, cost, and trust.
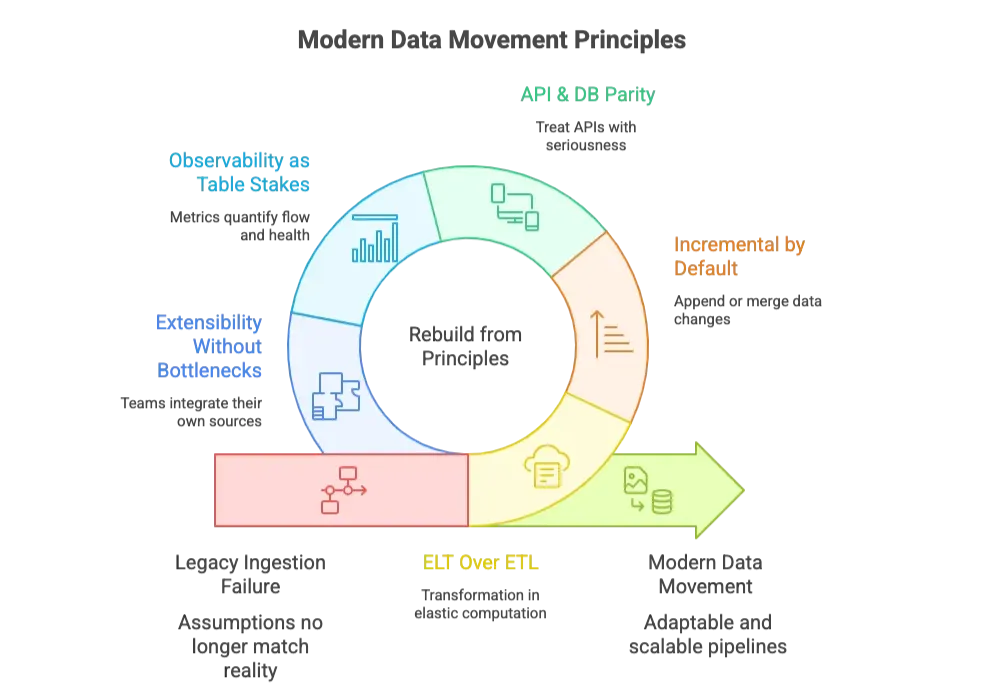
Transformation belongs where computation is elastic and parallel, not in fragile ingestion code. That’s why the evolved approach is ELT: keep extract and load as lean as possible, then let downstream systems handle the heavy work. It respects the division of labour. Ingestion is about fidelity, while transformation is about interpretation. Mixing them creates unnecessary coupling and fragility, and why did we mix in the first place?
The unit of change is not a whole table, but the delta between “before” and “after.” Full refreshes use brute-force: they consume bandwidth, spike compute, and lapse SLAs as sources multiply. Modern ingestion assumes incremental first: append or merge strategies that reflect how data actually changes. CDC is not an advanced feature; it’s the baseline. Without it, freshness and cost are permanently at odds.
APIs are not side channels anymore; they’re often the system of record. Treating them as afterthoughts is an architectural error. A first-class ingestion system handles their realities with the same seriousness it applies to JDBC connections.
Modern data movement treats observability as a non-negotiable. It projects metrics that quantify flow, health endpoints that expose status, and run history. Only with visibility can teams build the operational discipline that ingestion requires.
Finally, scale demands openness. If every new source requires central engineering to write a connector, you’ve recreated the mainframe model: all power, no agility. Extensibility means the teams closest to the data can integrate their own sources and destinations without waiting in a queue. It’s a principle of autonomy: pipelines must adapt at the edges, not only in the core.
If the modern principles of data movement can be summed up as incremental-first, API-aware, CDC-capable, observable by default, and extensible without bottlenecks, the Data Movement Engine recommended in Data Developer Platform (DDP) Standard (a community-driven data platform standard) is simply their embodiment in code.
It is the DDP Data Movement Engine, built not as another monolithic ingestion framework, but as a lean system for fast, observable EL/ELT that works equally well across databases, APIs, files, streams, and change data capture.
Its philosophy is clear: make Extract and Load boringly reliable, so that everything downstream (transformation, modelling, analysis) inherits a foundation of trust.
The Data Movement Engine, in short, is not an ingestion tool bolted onto a stack. It is the articulation of a set of principles in running code, turning abstractions like “incremental-first” or “extensible by design” into concrete patterns you can operate, measure, and trust.
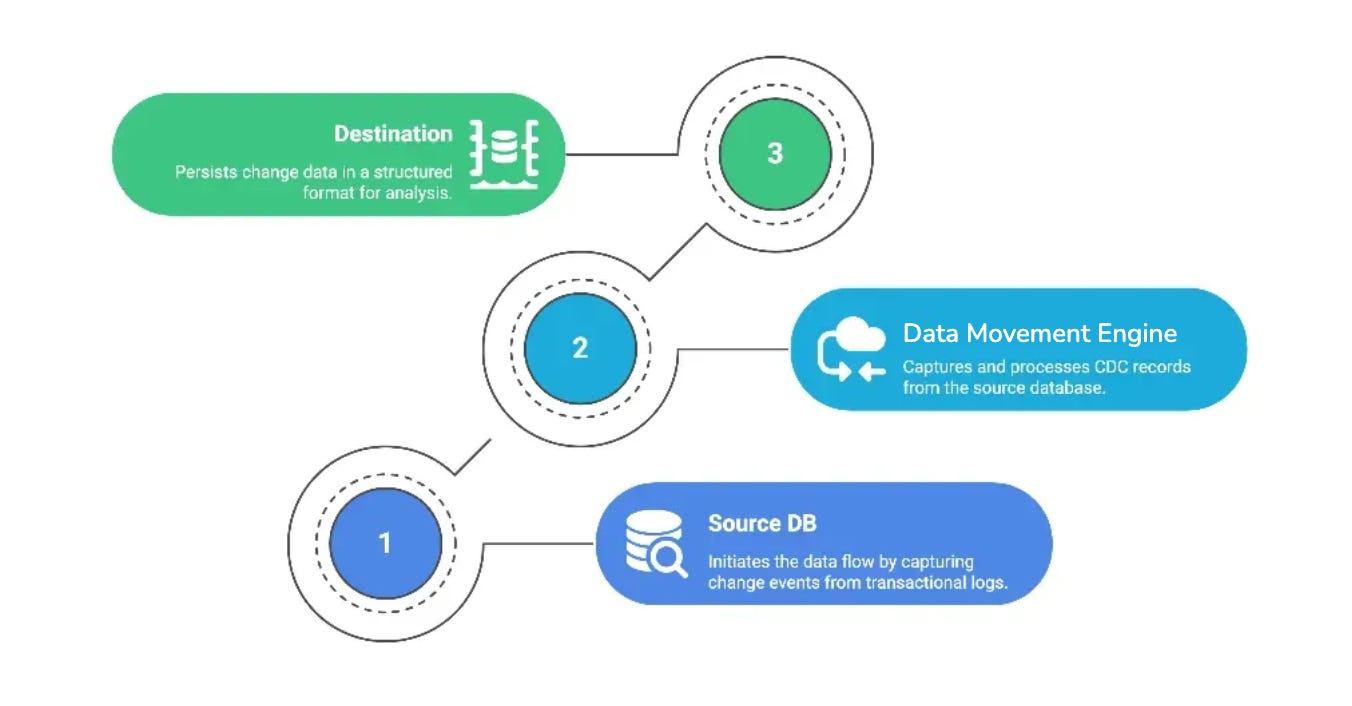
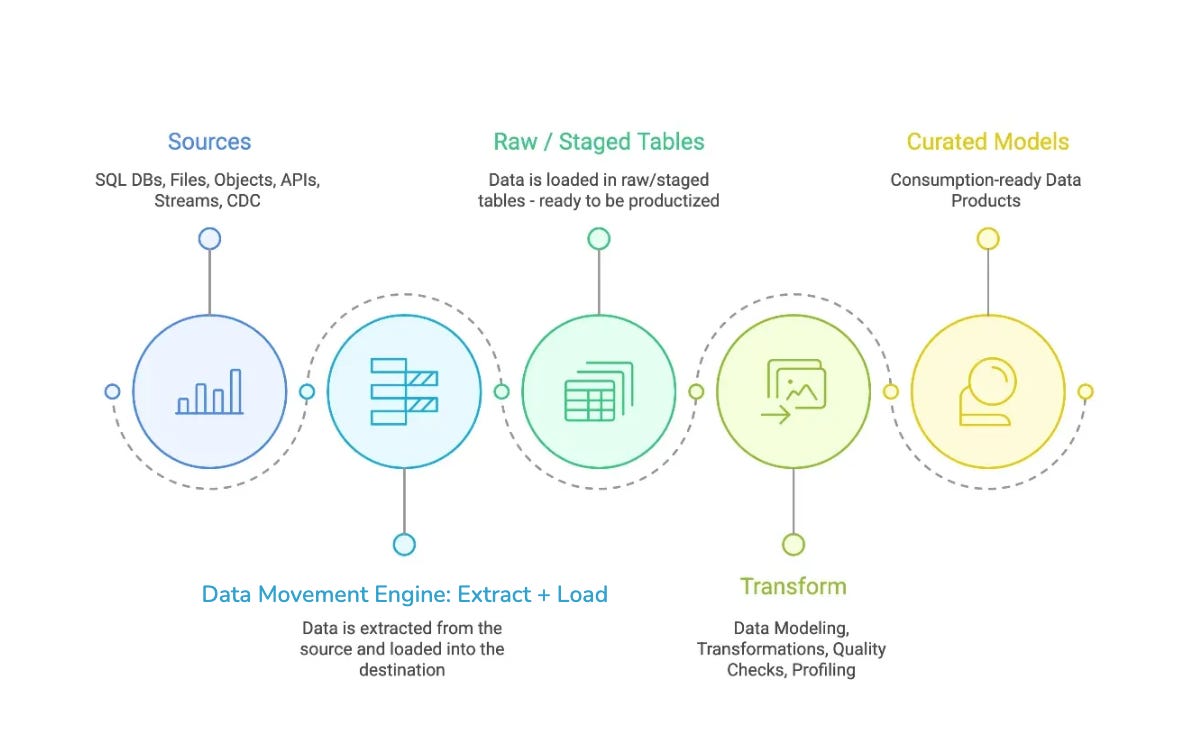
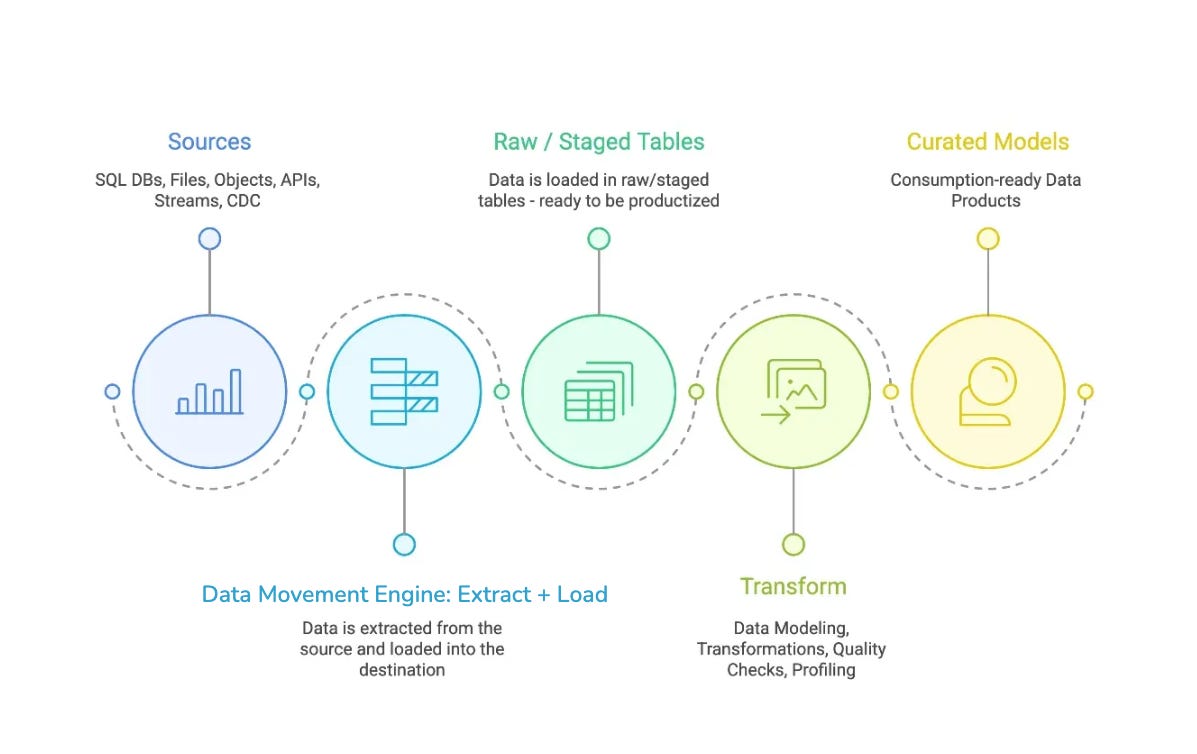
The architecture of DDP’s Data Movement Engine is a reflection of its philosophy: keep ingestion predictable, reliable, and focused on moving state faithfully, then let downstream systems handle transformation. This is the essence of ENL: Extract, Normalise, Load.
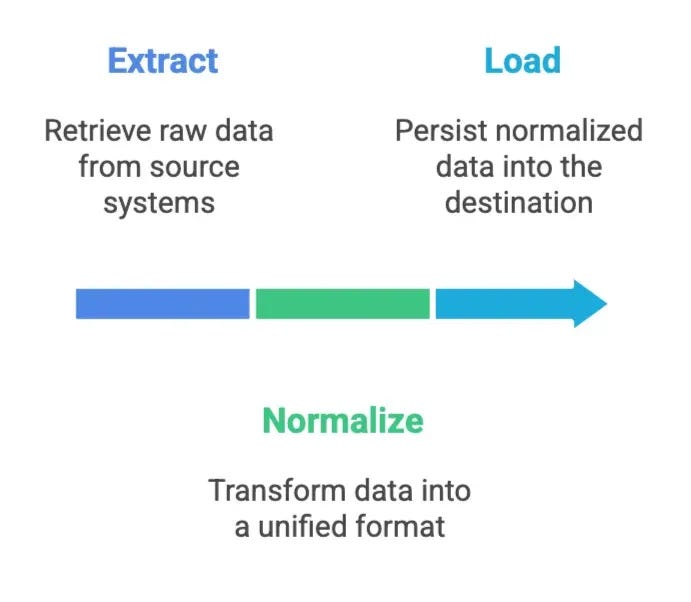
Extraction is about connecting to truth at its source. Databases, APIs, files, and streams all have different semantics for change, latency, and reliability. The Data Movement Engine treats each source according to its nature: batch when bulk windows make sense, CDC when capturing every row/column-level change matters. Every extraction is schema-aware, backpressure-safe, and designed to move only what’s necessary: the delta instead of the entire table. Reflecting that time and cost are finite resources.
Raw data is rarely for consumption: data types vary, columns mutate, nested structures shift. Normalisation reconciles these by unifying types, adapting to schema evolution, handling columns deterministically, and so on. The goal is simple: take messy, heterogeneous data and make it boringly reliable, without discarding fidelity.
Loading is where correctness meets scale. Writes are idempotent to tolerate retries without duplication. Large datasets are chunked and parallelised so failures are isolated and throughput is predictable. Destinations are pluggable: Iceberg-native by default, but extendable to other sinks, ensuring that data lands where it can be used, governed, and trusted.
DDP’s Data Movement Engine embodies the principles that address the fundamental mismatch between modern data realities and legacy pipelines. Each differentiator follows logically from first principles: move state efficiently, reliably, and observably, while keeping teams unblocked.
Modern data movement isn’t about doing the same thing faster but about rethinking the fundamentals of how data flows. The Data Movement Engine embodies that rethink.
Change is continuous, granular, and sometimes subtle. The Data Movement Engine listens to transactional logs, capturing every insert, update, and delete with full before/after context. Offsets and resumable reads make the process reliable, and compaction keeps history manageable. This replaces brittle polling and expensive full refreshes with streams teams can trust.
Batch isn’t dead. It’s a deliberate choice when applied incrementally. The Data Movement Engine uses windows, append/merge strategies, and parallel, chunked loads to balance throughput, cost, and reliability. Parameterised queries and automatic schema handling mean complexity doesn’t become fragility.
DDP’s Data Movement Engine captures metrics, exposes APIs for runs, visibility in saved offsets, and health, and tracks structured logs and audit trails. Every load, every change, feeds governance and catalog systems automatically, making trust inherent, not bolted on.
Data isn’t static, and neither should your platform be. The Data Movement Engine lets teams add new sources or destinations via customised Python scripts, while curated CDC connectors preserve reliability. The architecture is sink-pluggable, so innovation never requires rebuilding the core.
DDP’s Data Movement Engine allows you to move metadata as well as usage logs from source systems (eg, Snowflake, PostgreSQL, etc.). It relies on the system tables and views offered by source systems.
At its core, data movement is about one simple principle: get the truth from its source to where it can be used, reliably and efficiently. Legacy stacks break that principle. They treat every load as a monolith, ignoring the natural grain of change, paying the cost of brittleness, opacity, and duplication at every step.
Modern data movement starts from fundamentals: only move what has changed, capture deltas with precision, treat APIs as first-class citizens, and make every pipeline measurable and accountable. Observability isn’t optional but baked into the fabric of the system.
Data Movement Engine operationalises these principles. It makes Extract + Load predictable and boring, removing the friction so that transformation, analytics, and insights can scale without compromise. When the mechanics of movement are solved, the intelligence of data can finally shine.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




