


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT




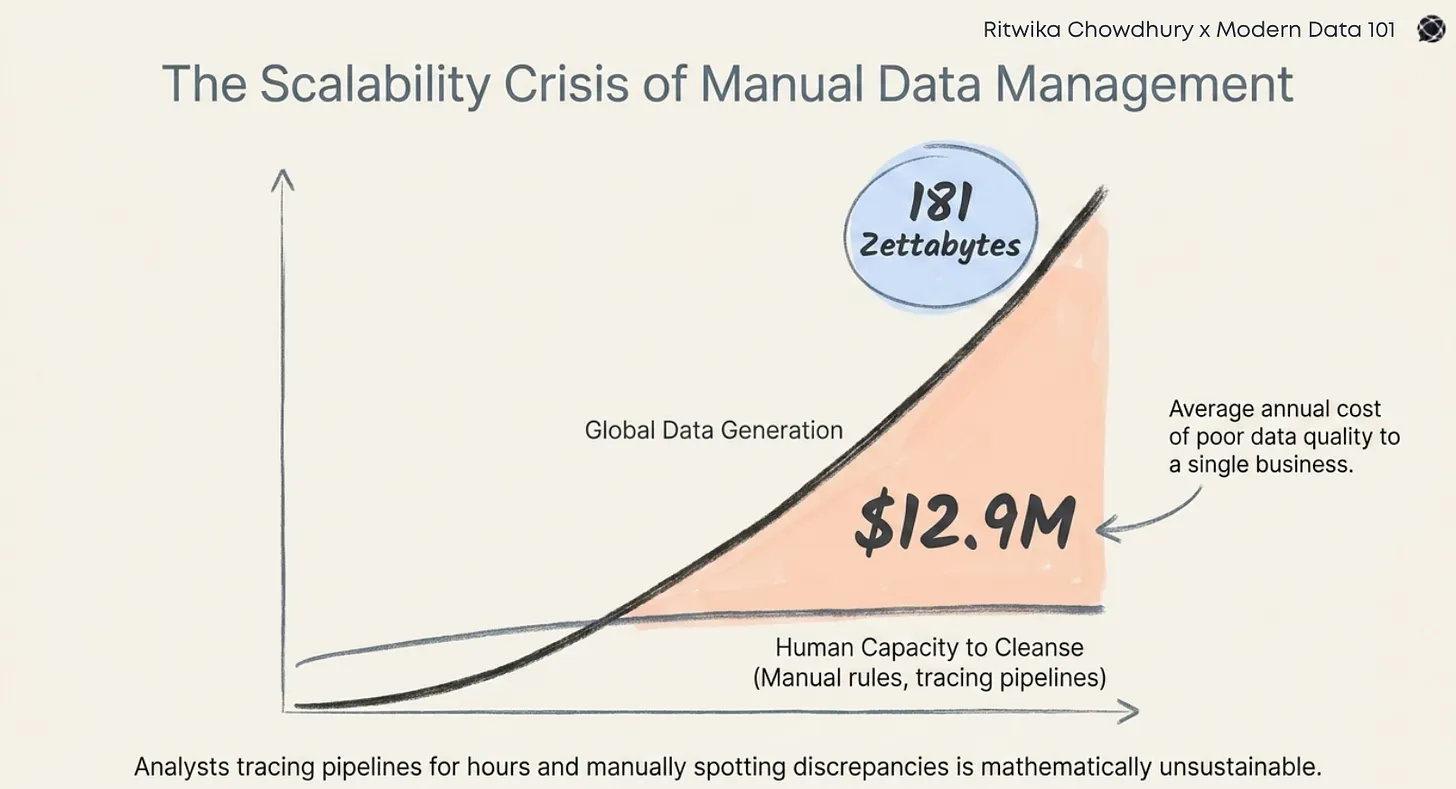
The $12.9M Entity Resolution Problem that is turning heads in 2026, is not a new conversation doing rounds in the data corridors. Gartner predicted this back in 2020 when enterprises were busy playing with AI like a toddler would play with a rattle.
Gartner called it the average annual cost of poor data quality per organisation. This alone makes the identity layer impossible to ignore.
When different identities are fragmented across disparate systems, the business does not just lose data quality; it loses cash, speed, and confidence in every decision depending on that very data.
The figure puts a real number on a problem many leaders already feel but do not always quantify. This is not only a cost in bad records, but it also surfaces a rather harsh truth in wasted effort, missed revenue, manual cleanup, and weak trust in the data itself.
Entity resolution helps a business to determine whether different records refer to the same real-world entity. This entity could be a customer, patient, supplier, or account.
.png)
To be precise, it helps answer questions like: Is John Doe and John D. the same person across the enterprise’s CRM, billing, and support? Are there duplicate records? And most importantly, how confident is the business in the match? These are critical answers as a false merge can join two different people into one identity, while a false split breaks one real person into many identities.
Poor entity resolution remains hidden from plain sight and takes cover behind more visible layers like AI models and analytics dashboards.
1. Entity resolution problems, specifically, are structurally designed to stay invisible because fragmented data stacks treat each integration as a handoff, and every handoff is a contract nobody wrote down, creating a compounding maintenance cost that becomes a structural tax on every organisation trying to build on top of data.
😉 Imagine your kitchen tap is leaking at one drop per minute. It takes roughly 24 hours to fill half a mug. Harmless enough to ignore, until it fills the bucket and floods the floor. That is exactly the dynamic with fragmented identity data: slow, invisible, and catastrophically expensive by the time it registers.
2. According to Gartner, poor data quality costs B2B organisations an average of $12.9 million annually, and the typical organisation has an account overlap rate of 20–30% in its own data files. These are embedded in the daily decisions your teams make while looking at incomplete records.
💡Consider what this looks like operationally. A sales team working the same account under three different records. A service team is unable to trace a full customer journey because it is split across disconnected systems. An analyst reconciling mismatched identities before a single report can begin. The burden falls on analytics and finance teams, spending hours on manual reconciliation just to get an accurate count of spend or revenue.
3. All of these compounds. Think of an office cabinet where the same person appears under different headers in different drawers. The files exist. The problem is that no one can trust the cabinet to tell a complete story. When organisations rely on flawed inputs, every downstream system inherits the error: dashboards display misleading performance metrics, operational processes malfunction, and strategic planning drifts away from reality. This is an operational misalignment that costs money at every level, along with compliance gaps, and AI and analytics drift.
[playbook]

A data management platform turns entity resolution into a governed business capability. Hence, these platforms function as a capability layer.
.png)
That’s a heavy-lifting effort, and that matters because entity resolution is not to be treated as a one-off script and just stay in some corner of the stack; rather, it should behave like a managed capability. When the logic is reusable and governed, the business stops reinventing the wheel viz building the same identity layer over and over again. A Data Management Platform can also make ER operational, not just technically correct, but also operationally useful.
The cost $12.9M, is not the exact figure every enterprise will hit at some point in time. It represents a value that draws attention to a cost many leaders already feel but are rarely able to quantify. It turns an abstract data issue into a concrete business problem.
That is powerful because poor entity resolution is often treated as cleanup work while it is a decision-quality issue. If the identity layer is weak, everything above it has to work harder. If the identity layer is strong, the rest of the stack becomes easier to trust.
[related-3]
A healthy entity resolution should produce visible outcomes. Fewer duplicate records, better customer and account visibility, cleaner reporting, more accurate segmentation, faster service resolution, and better trust in AI and analytics outputs. These operating improvements bring clarity to the business.
For the data leaders, the question is not whether entity resolution is useful or not. It is whether the organisation has made it part of the operating model?
How much of time is the business losing to identity cleanup? Do we have one shared and governed identity layer, or numerous local versions of truth? Can we explain how matches are made and how conflicts are handled? Is it hidden inside isolated workflows? Can downstream teams trust the identities they consume?
If the answers to those questions are blurry, the business is already paying the Identity Tax.
The core cost of poor entity resolution is not only bad data; it derails the entire decision-making process, slows the execution, and forces a business to keep paying for the same ambiguity again and again. To escape this trap, businesses need to start with identity. It gives better analytics, improved personalisation, superior compliance, and exceptional AI.
No, deduplication removes the exact or obvious duplicates. Entity Resolution goes a mile further and determines whether different-appearing records belong to the same real-world entity.
Real-world data is generally messy. Names change, records go stale. Additionally, different teams define identity differently.
An MDM gives a governed way to unify identity, apply matching logic consistently, and make the output reusable across teams, allowing for the smooth functioning of a business.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




