


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.jpg)


TABLE OF CONTENT



Data came into industries to solve a number of challenges, yet we are fine-tuning our processes to fix the challenges data itself brought in. Today, no two data systems agree on a canonical form. So when data flows across system boundaries, identity breaks down.
The underlying issue is that language was designed for human communication, not database keys. Humans resolve identity effortlessly using world knowledge, context, memory, and inference. Machines have none of that natively; they only see character sequences.
Semantic entity resolution exists to bridge this gap: giving machines the contextual, world-knowledge-aware reasoning.
That gap, between symbolic representation and grounded real-world identity, is the major challenge that makes this problem both difficult and yet, necessary.
In this article, we will explore 5 reasons why organisations need semantic entity resolution for improved business outcomes.

Semantic entity resolution doesn't work in a vacuum. It needs a shared business language to resolve entities into a consistent definition of what a "customer," "supplier," or "product" actually means across the organisation.
That's the job of the semantic layer: a virtual layer that sits between raw data and consumption, translating physical data into the language of the business. Without it, you're resolving entities into a moving target, different systems, different definitions, different truths.
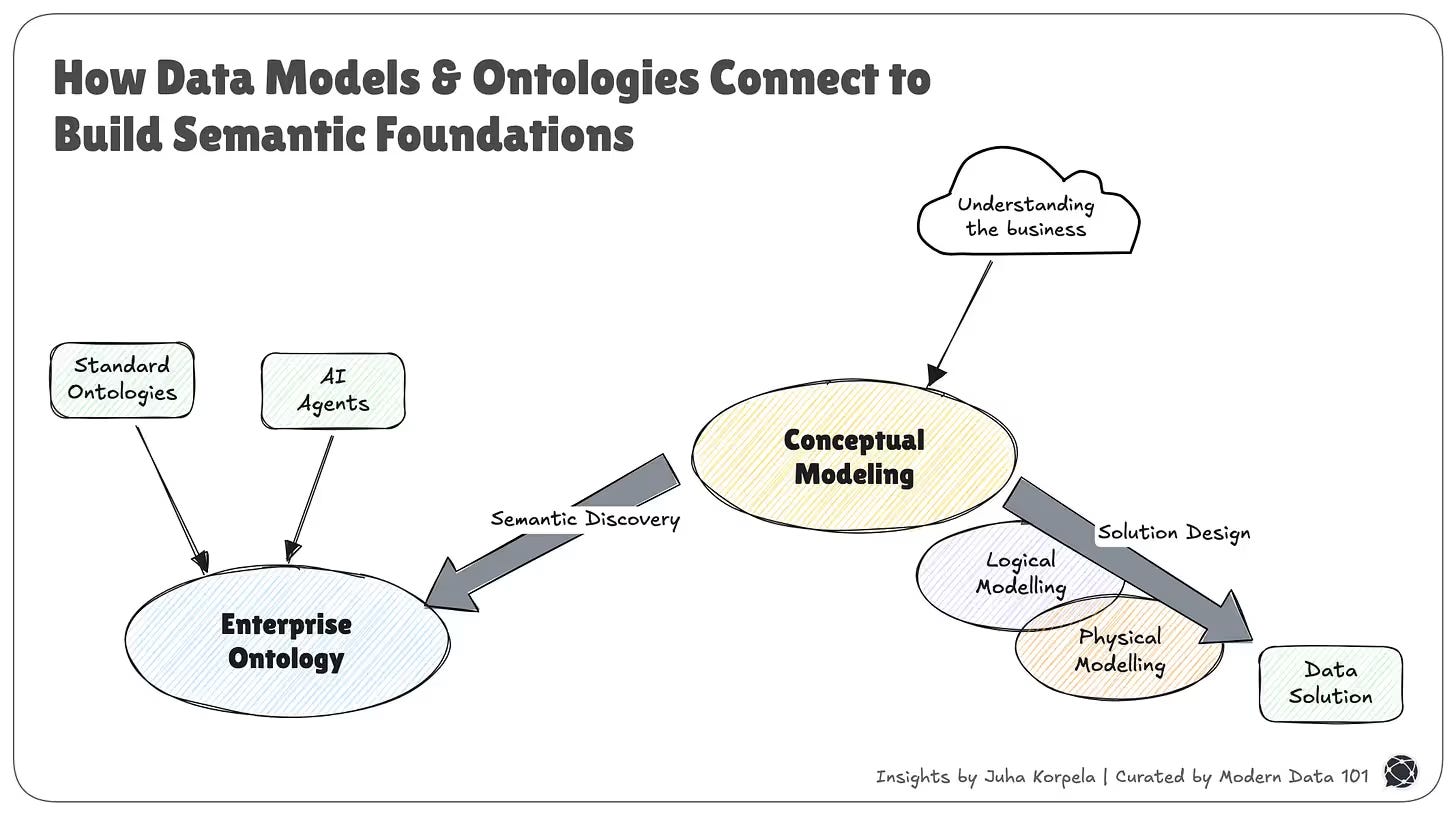
A semantic data model gives the organisation a fixed, machine-understandable contract for what things mean. Semantic ER then uses that contract to identify, reconcile, and merge records with precision. One cannot work without the other.
Enterprises often operate on a fractured version of data. Customer records split across CRM systems, supplier names inconsistently logged across procurement tools, entities extracted from documents carrying dozens of surface variations of the same name; the mess is pervasive and costly.
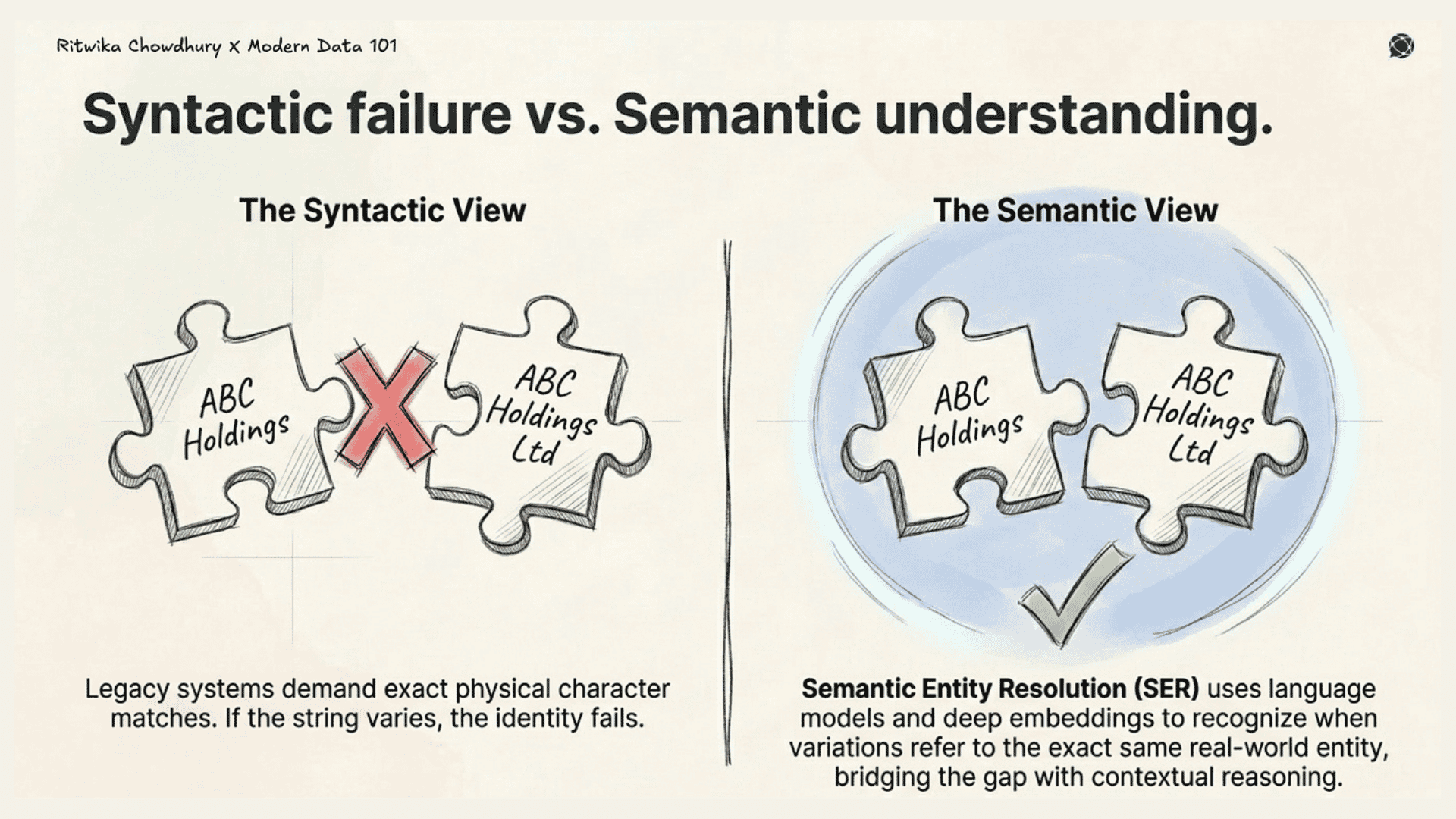
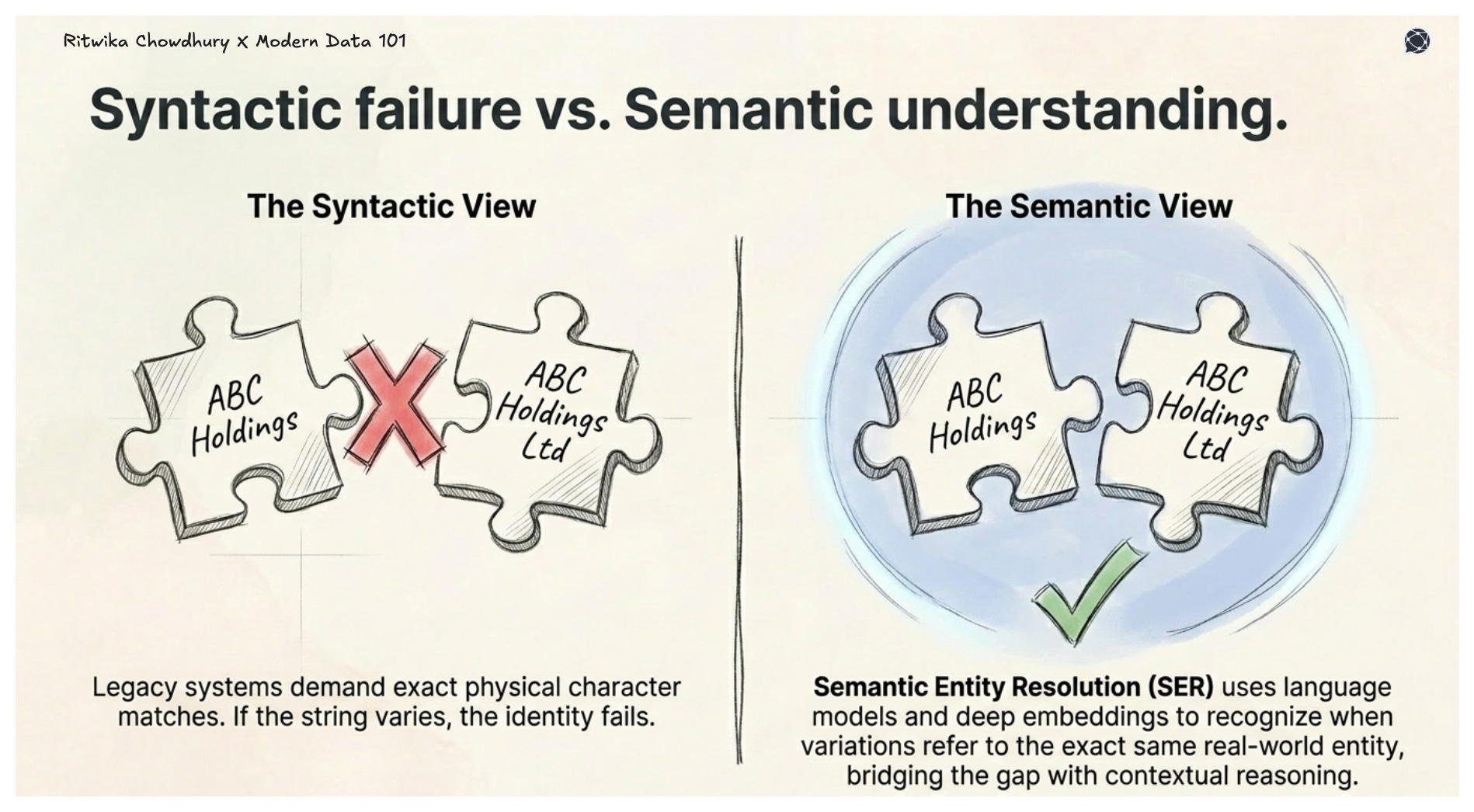
Semantic entity resolution helps address these at the root, using language models and deep embeddings to identify, reconcile, and merge records that refer to the same real-world entity.
Here are five reasons why organisations can no longer afford to operate without it.
[playbook]
Consider a CRM that says 10,000 customers. Your data warehouse says 14,000. Your finance team says 8,500. They're all looking at the same business reality through fragmented data silos.
When entities aren’t resolved, every system mints its own version of the truth. “J. Smith,” “John Smith,” and “Jonathan Smith, Jr.” are three records, and not one person. Every report built on top of that is wrong. Every model trained on it learns the wrong thing.
Semantic ER collapses those variants into a single, authoritative record. That’s not a data quality task. That’s the foundation everything else depends on.
[related-1]
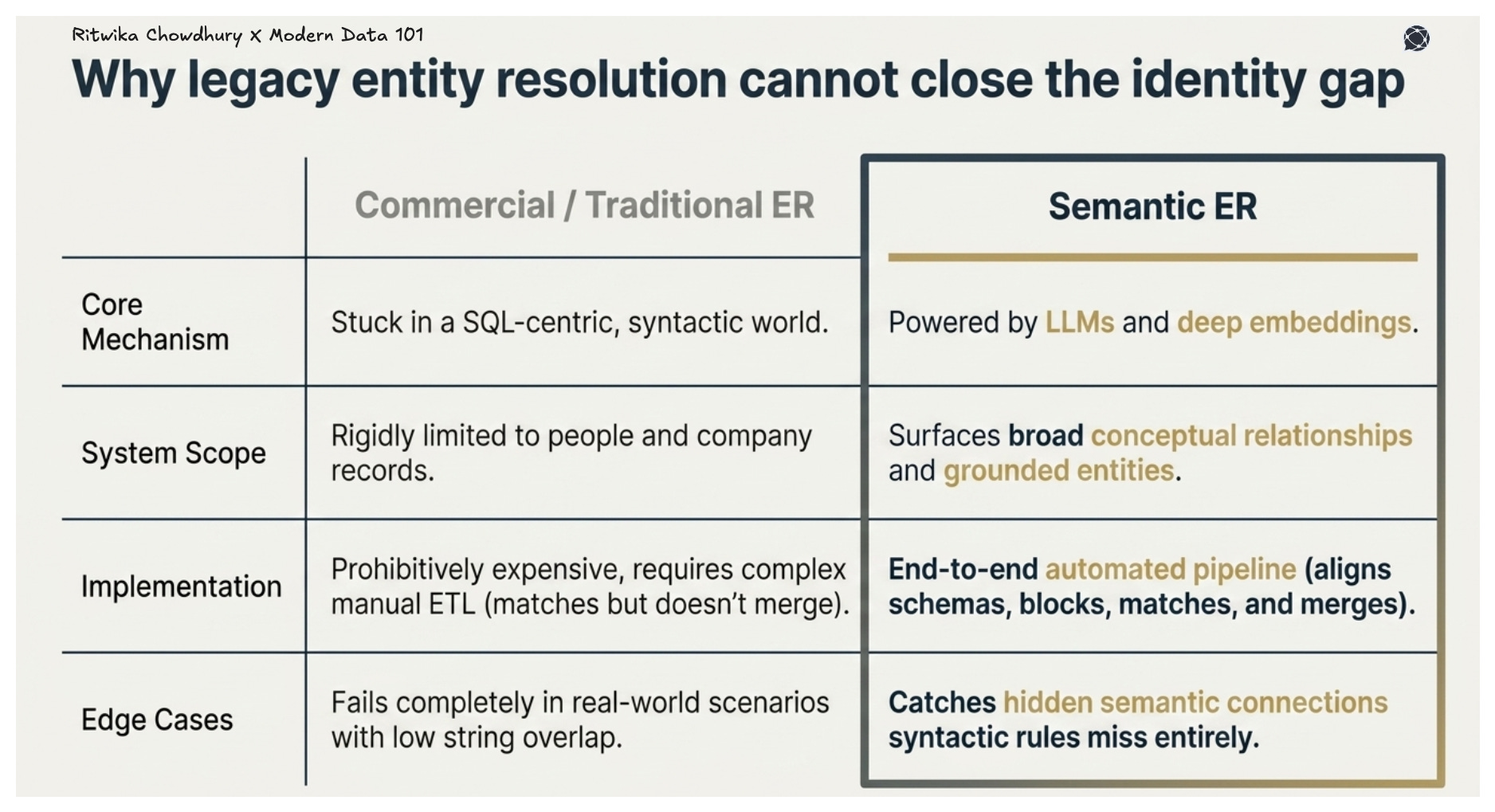
Commercial entity resolution products are often stuck in a SQL-centric world, limited to people and company records, and can be prohibitively expensive. Furthermore, most entity linking libraries from academia aren't effective in real-world scenarios because they are frequently developed using "toy" datasets that fail to account for the complexity and noise of "data in the wild".
Both sets of tools typically focus only on the matching stage and fail to merge nodes and edges (canonicalisation), which requires significant manual effort through complex ETL pipelines to successfully complete the data cleaning process.
Organisations are building internal knowledge graphs to power autonomous agents. LLMs make extraction easy, but extraction produces dirty graphs full of duplicate nodes. When “JPMorgan Chase” and “JPMorgan Chase & Co” are two separate nodes, an agent reasoning over that graph will produce wrong answers confidently.
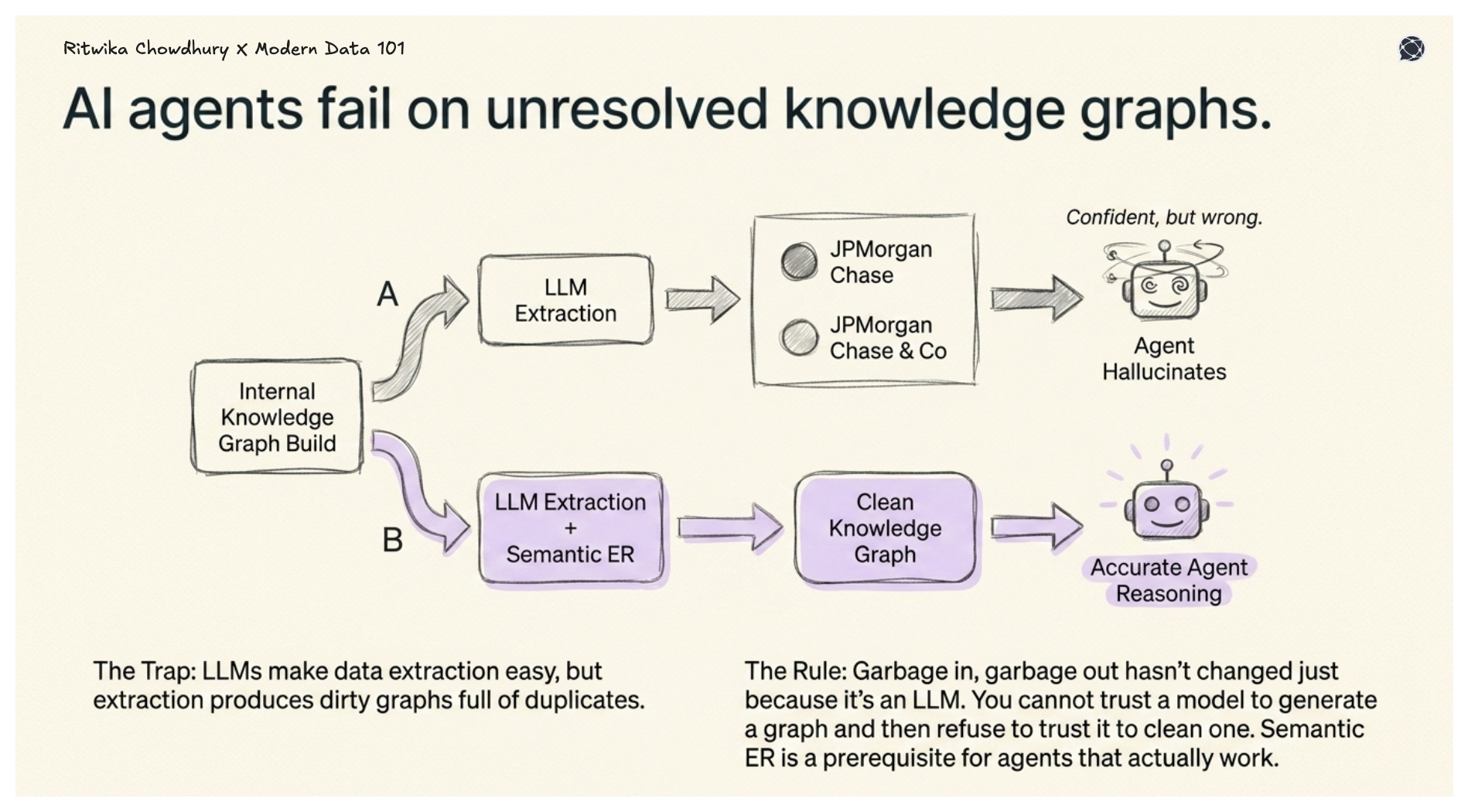
Garbage in, garbage out hasn’t changed just because it’s an LLM producing the output. Semantic entity resolution using LLMs can align schemas and help unify blocking, matching, and merging into a more cohesive automated pipeline, reducing the need for the fragmented, multi-step setups typical of classic tools.
Entity-resolved knowledge graphs are a prerequisite for agents that actually work. You can’t trust a model to generate a graph and then refuse to trust it to clean one.
[related-2]
Fraudsters and money launderers do not advertise themselves consistently. They operate precisely in the gaps between records, the space where “ABC Holdings Ltd” and “ABC Holdings” are treated as separate entities, or where a network of shell companies shares obscured ownership.
By uncovering non-obvious relationships and linking seemingly disparate accounts, transactions, or identities that actually belong to the same individual or organisation, entity resolution helps analysts identify suspicious patterns, critical for detecting activities like synthetic identity fraud, money laundering networks, and duplicate insurance claims.
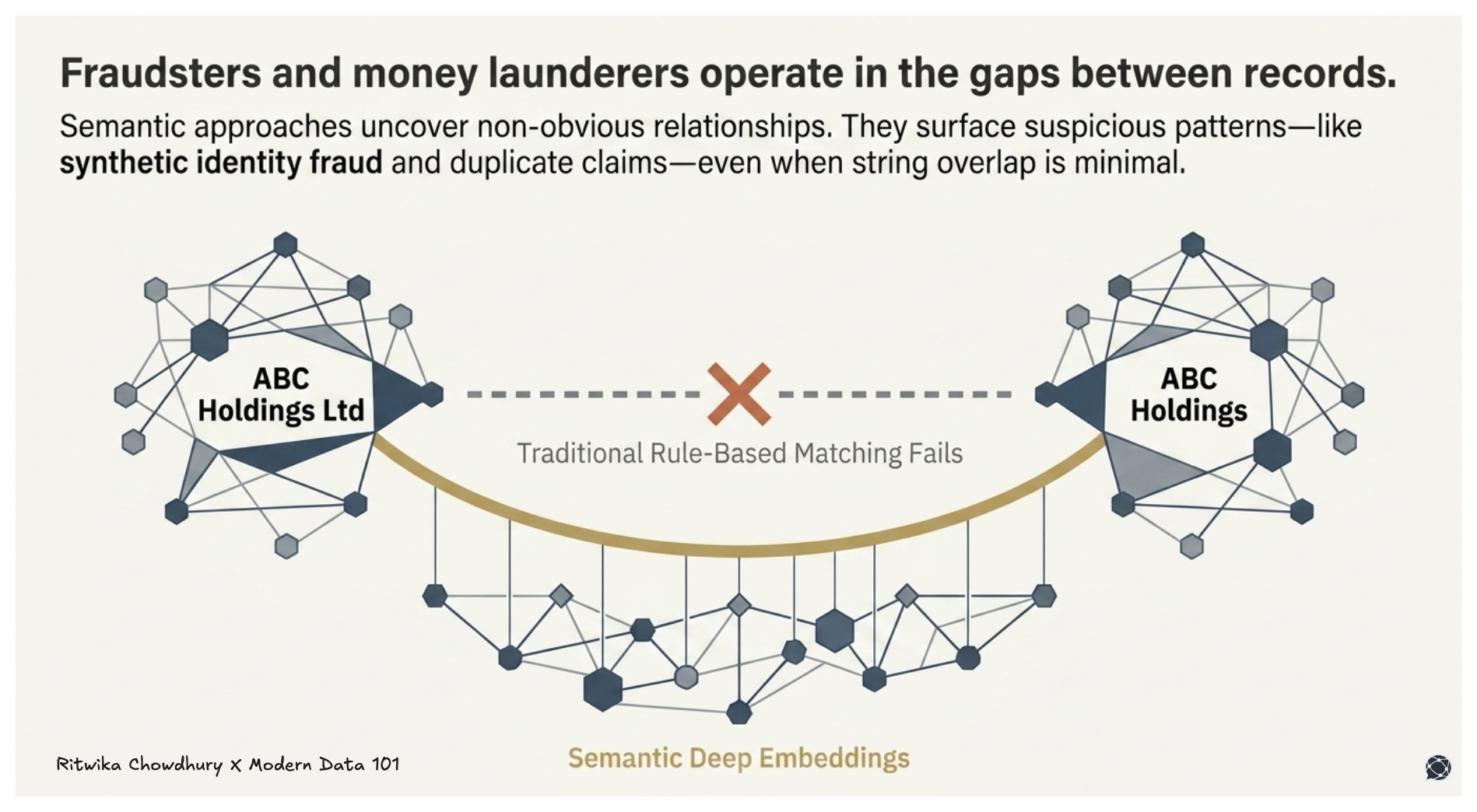
Semantic approaches go further than traditional rule-based matching because they can surface conceptual relationships even when string overlap is minimal, catching what purely syntactic systems miss entirely.
Beyond the strategic stakes, there is a grinding operational cost to unresolved data. Implementing entity resolution drives significant operational efficiency by automating the often laborious, time-consuming, and error-prone tasks.
That is of manually identifying and merging duplicate records, freeing up valuable human resources previously dedicated to data cleansing, reducing data processing times, and minimising errors in downstream applications. Compliance teams drown in false positives generated by duplicate records. Marketing teams target the same customer three times.
Finance teams often spend significant effort reconciling figures that ideally should never have diverged in the first place. A methodical, explainable, and data-driven approach to risk, enabled by entity resolution can substantially reduce false positives while also lowering the risk of false negatives, leading to measurable productivity gains across the organisation.
Semantic entity resolution matters because most data doesn’t agree on what the same entity looks like.
Without it, the same organisation, say Amazon, “Amazon.com, Inc,” and “AMZN” gets treated as different entities. That leads to fragmented views, broken analytics, and AI systems reasoning over incomplete or incorrect context
With semantic resolution, systems match on meaning, so they operate on a consistent, real-world view of entities.
Start with a high-impact use case where inconsistency hurts. Define core entities and metrics clearly. Map source data to these definitions and encode them in a reusable semantic layer. Make it the default access path for dashboards, APIs, and AI systems, instead of raw tables. Then iterate based on real usage and edge cases.
Yes, but partially. GenAI is useful for semantic matching (understanding that different representations may refer to the same entity), especially in messy, unstructured data.
But it’s not enough on its own as it lacks determinism, hard to audit and govern and can introduce false positives.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


