



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)

TABLE OF CONTENT


.png)

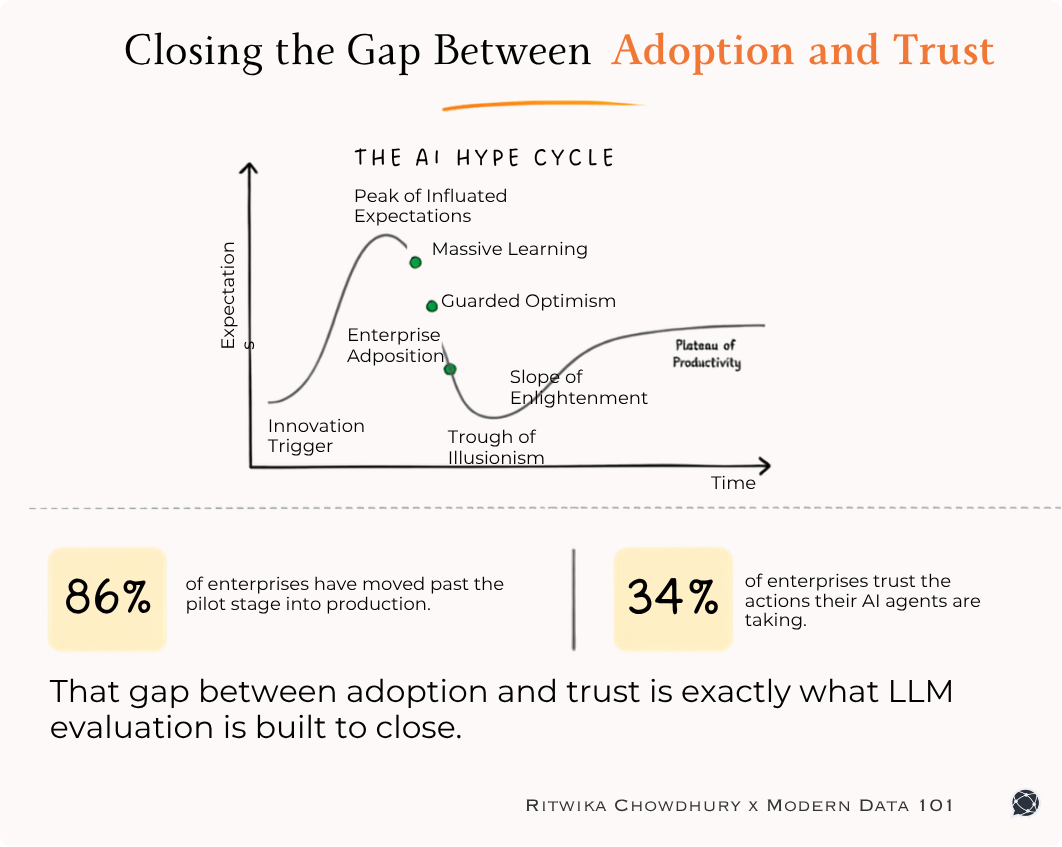
Poor quality data has a profound impact, costing organisations at least $12.9 million a year. There are several fragmented, duplicated, and unreconciled records that nobody can agree on, and that every downstream system quietly inherits. These add up as a reason for this cost that organisations have to bear.
While poor data quality manifests in many forms, like missing values, stale records, schema inconsistencies, governance gaps, and lineage issues, one of the most persistent and expensive causes is unresolved entity identity. Duplicate customers, fragmented supplier records, and inconsistent representations of the same real-world object create conflicting versions of truth that every downstream system inherits.
That’s how enterprises keep focusing on entity resolution for an improved data management regime, but the core of this debate among CDOs and other decision makers is not whether or not they require thorough entity resolution, but ‘how’ they should approach it.
For decades, the default answer was rules-based matching. While this remains effective for stable, well-defined domains, modern enterprise data environments increasingly expose its limitations at scale. Think of a mid-sized enterprise runs hundreds of applications simultaneously, each generating records in its own format, on its own schedule, with its own tolerance for inconsistency.
So the real question is whether rule-based ER would actually work and give the same ROI as it did some years ago.
This article discusses the fundamentals of two methods of ER: AI-Native vs Rule-based ER, and how organisations can decide what’s going to be the scalable option for them.
Entity resolution is the process of identifying and linking records across disparate data sources to produce a single, trusted "golden record" for every key business entity.
Though this sounds straightforward, it often is not. Think, for n records, there are n(n-1)/2 unique pairs to evaluate. Scale your data by 10x, and your comparison problem grows 100x.
Many downstream initiatives, including analytics, operational applications, agentic workflows, LLMs, and real-time personalisation, depend on trusted entity resolution. When identity is fragmented or inaccurate, every consuming system inherits that uncertainty. For AI systems in particular, this can result in confidently incorrect outputs rather than obvious failures.
Practitioners have a name for this: false precision. It is considerably more dangerous than an obvious failure.

Rules-based entity resolution works on a simple premise: define the logic, run it against your records, and match on what aligns.
For instance, if two records share the same tax ID, then merge them. A name matches within an acceptable edit distance, then flag it for review. The rules are explicit, auditable, and fast to implement on well-structured data.
For bounded, stable, compliance-critical scenarios, this still makes sense. A single CRM deduplication project, or a regulated dataset where every match decision needs a traceable, deterministic justification. Small, clean, consistent data where the matching logic won’t need to change next quarter.
That’s where it works. The problems start immediately after.
[playbook]
The real enterprise decision is rarely rules versus AI. It is determining where deterministic rules remain valuable and where learning-based approaches become necessary. We know how rule-based traditional ER encodes identity as logic. Rules, thresholds, and deterministic joins defined what counted as “the same.” That works effectively when data was stable, structured, and limited in scope.
[related-1]
AI-native ER treats identity as the element the system learns and continuously refines, using machine learning and LLMs to observe how records relate across real data, not how we assume they should match. Similarity is hence inferred.
Records are represented as embeddings, allowing the system to reason over meaning rather than exact values.
Candidate matches are surfaced through embedding similarity and learned representations. And instead of binary decisions, the system assigns probabilities, reflecting the inherent uncertainty in identity. Beyond statistical similarity, enterprises also need explicit business semantics, including controlled vocabularies, taxonomies, equivalence mappings, and domain definitions, to make resolved identities understandable and reusable.
Every correction, every downstream failure, every interaction becomes a signal. The system updates its understanding of identity over time. What counts as “same” evolves with the data and the business context. This changes the role of entity resolution entirely.
Entity resolution increasingly acts as a reusable enterprise capability that supports analytics, operational applications, data products, and AI systems through a consistent understanding of identity. AI-native ER builds and maintains an adaptive model of identity in an environment where identity itself is fluid.
[state-of-data-products]
Before discussing how to improve entity resolution outcomes, it helps to separate the different layers involved.
Entity resolution itself is only one layer of the architecture. Matching models, whether rule-based or AI-native, determine which records likely refer to the same real-world entity. The output of that process is represented through golden records or identity graphs, which provide a persistent view of identity across systems.
Above this sits the governance layer, where ownership, accountability, and quality management ensure identity remains trustworthy over time. A semantic layer provides shared business meaning through controlled vocabularies, taxonomies, equivalence mappings, and domain definitions. Finally, downstream consumers such as analytics applications, operational systems, and AI agents rely on these layers to make decisions.
Treating these as separate but connected capabilities helps explain why matching accuracy alone is never enough. Identity must also be governed, understood, and consumable.
AI-native matching models can significantly improve entity resolution in environments where data is incomplete, inconsistent, or highly variable. However, matching accuracy alone does not guarantee trustworthy identity. Over time, models drift, business definitions change, and data quality issues emerge that no matching algorithm can solve on its own.
Sustaining accurate entity resolution therefore requires more than better models. It requires clear ownership, shared definitions, continuous feedback, and operational accountability. This is where data products and semantic infrastructure become important. They do not replace entity resolution models; they provide the governance and context that allow those models to remain useful and trustworthy over time.

Data products introduce something different: accountability and context at the point where data is created and consumed.
Entity resolution without product ownership degrades consistently, where rules are unmaintained, and models drift as data patterns shift. Often, match quality erodes across quarters while every downstream system continues consuming the golden record as though it were still accurate.
Data products break this pattern. Each data product carries a clear definition of the entity it represents, the context in which that entity is used, and ownership accountability for its quality. Precision, recall, and F1 score remain technical measures of match quality, but ownership ensures they are monitored, acted upon, and connected to business outcomes rather than treated as isolated model metrics.
A drop in match accuracy triggers the same response as a drop in any other product’s reliability, such as investigation, remediation, and root cause analysis.
So instead of one abstract notion of “customer,” you get billing identity, marketing identity, and support identity. Each has its own semantics. AI-native ER operates across these, not by flattening them into a single forced global ID, but by learning how they relate. The result is an identity graph that respects domain boundaries rather than papering over them.
[related-2]
Consider what a well-resolved but semantically bare golden record looks like to a downstream AI agent: a merged identifier with a set of reconciled attributes. It knows the entity exists. It does not know whether that entity is a tier-one supplier or a one-time vendor, whether it falls under a specific regulatory jurisdiction, or how it relates to the other entities in the same knowledge domain. The agent has an identity without context.

A controlled vocabulary ensures that attribute naming is consistent across every domain your data product serves, so that “customer” means the same thing to your CRM data product as it does to your billing data product and your support data product.
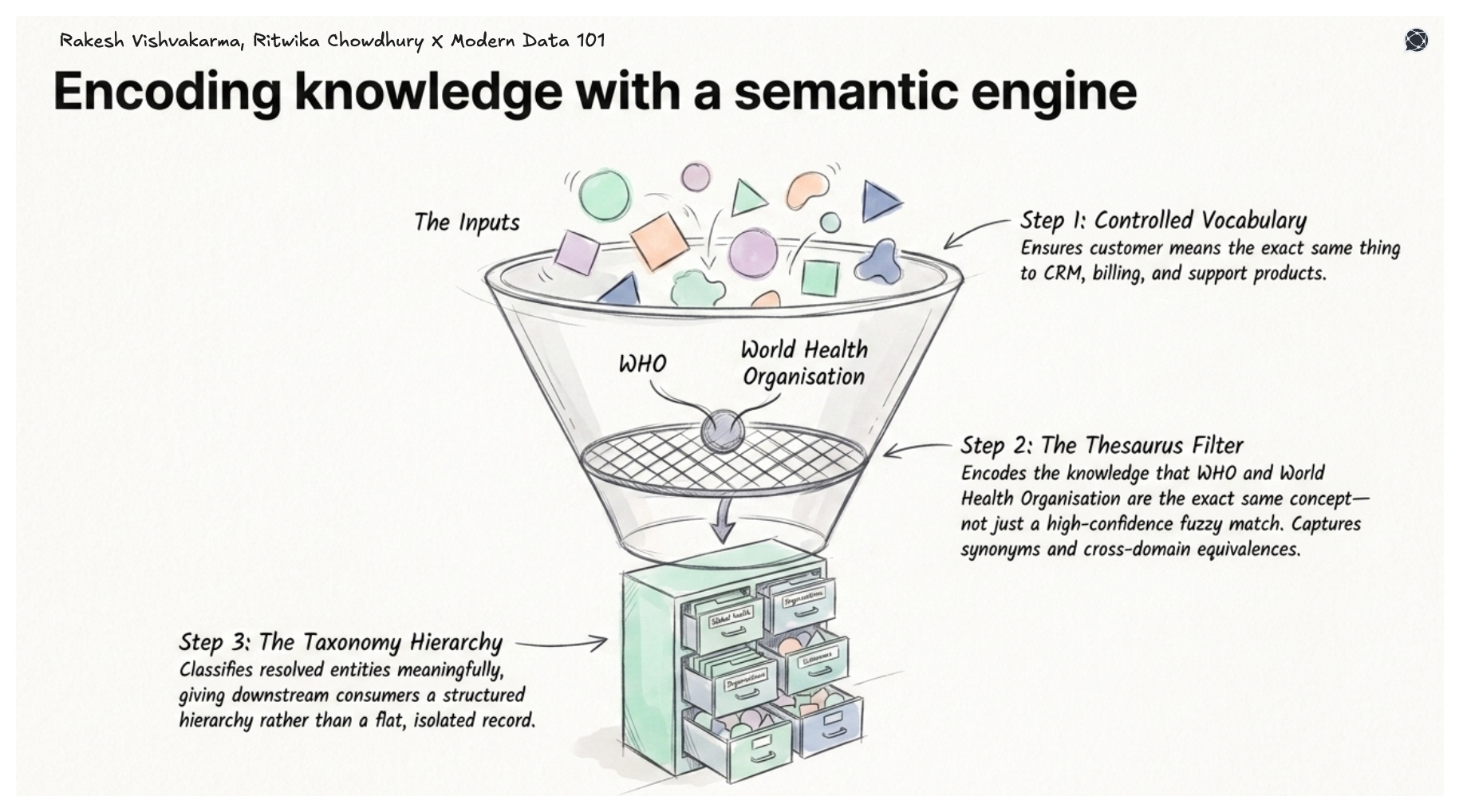
A taxonomy classifies resolved entities meaningfully, giving downstream consumers a hierarchy they can reason over rather than a flat record they can only retrieve. A thesaurus captures synonyms, alternative labels, and cross-domain equivalences that neither rule sets nor ML models generate on their own, encoding the knowledge that “WHO” and “World Health Organisation” are the same concept, not just a high-confidence fuzzy match.
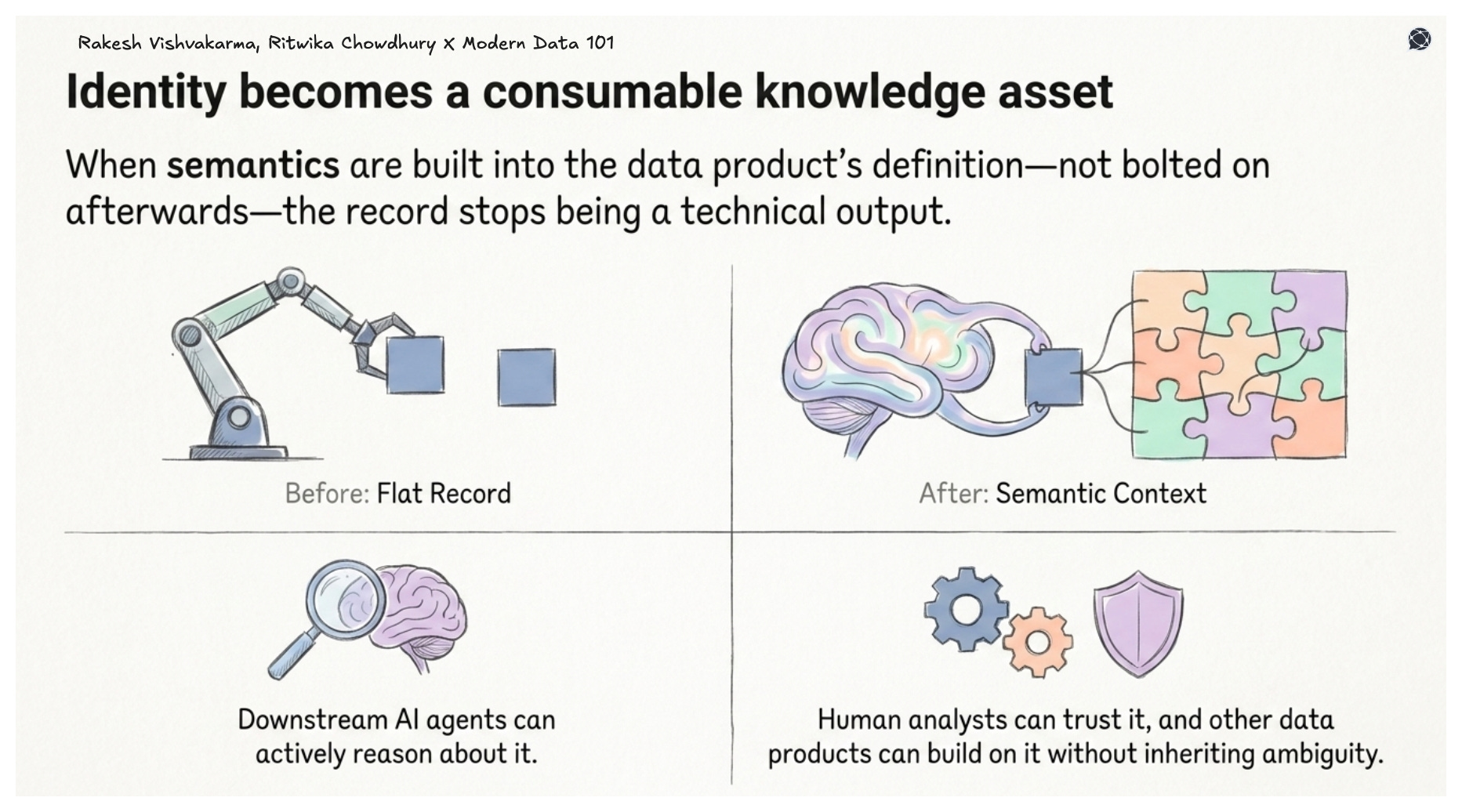
When this semantic layer is built into the data product’s definition, not bolted on afterwards, the record stops being a technical output and becomes a genuinely consumable knowledge asset. Downstream AI agents can reason about it. Analysts can trust it. Other data products can build on it without inheriting ambiguity.
[related-3]
AI-native ER needs continuous supervised signals to stay calibrated. Data products provide them, such as confirmed merges, rejected matches, downstream breakages traced back to specific identity decisions. Because data products have defined ownership, these signals are attributable and available for retraining.
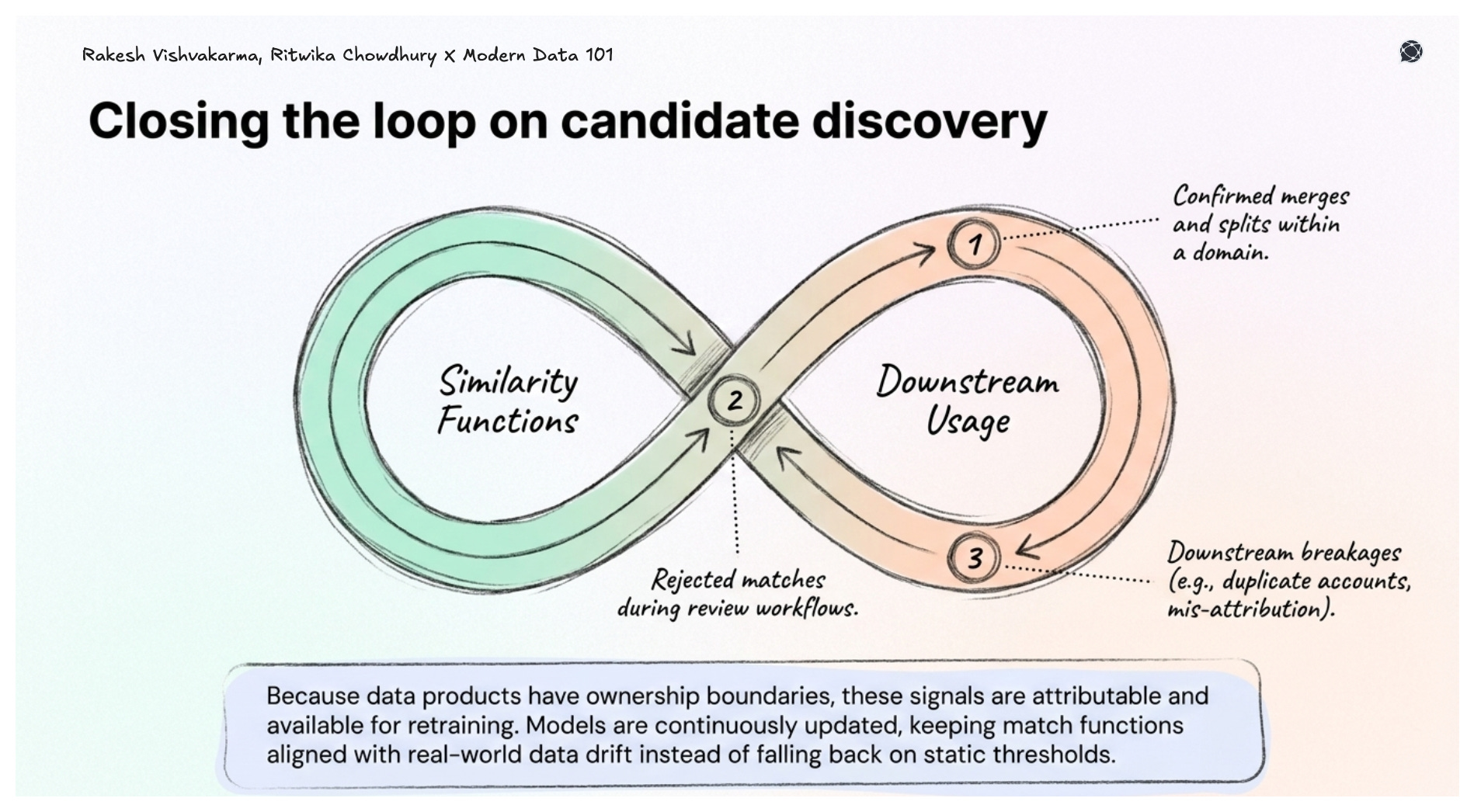
Without this, systems rely on static thresholds or one-time training datasets. Accurate at launch, degrading from that point forward.
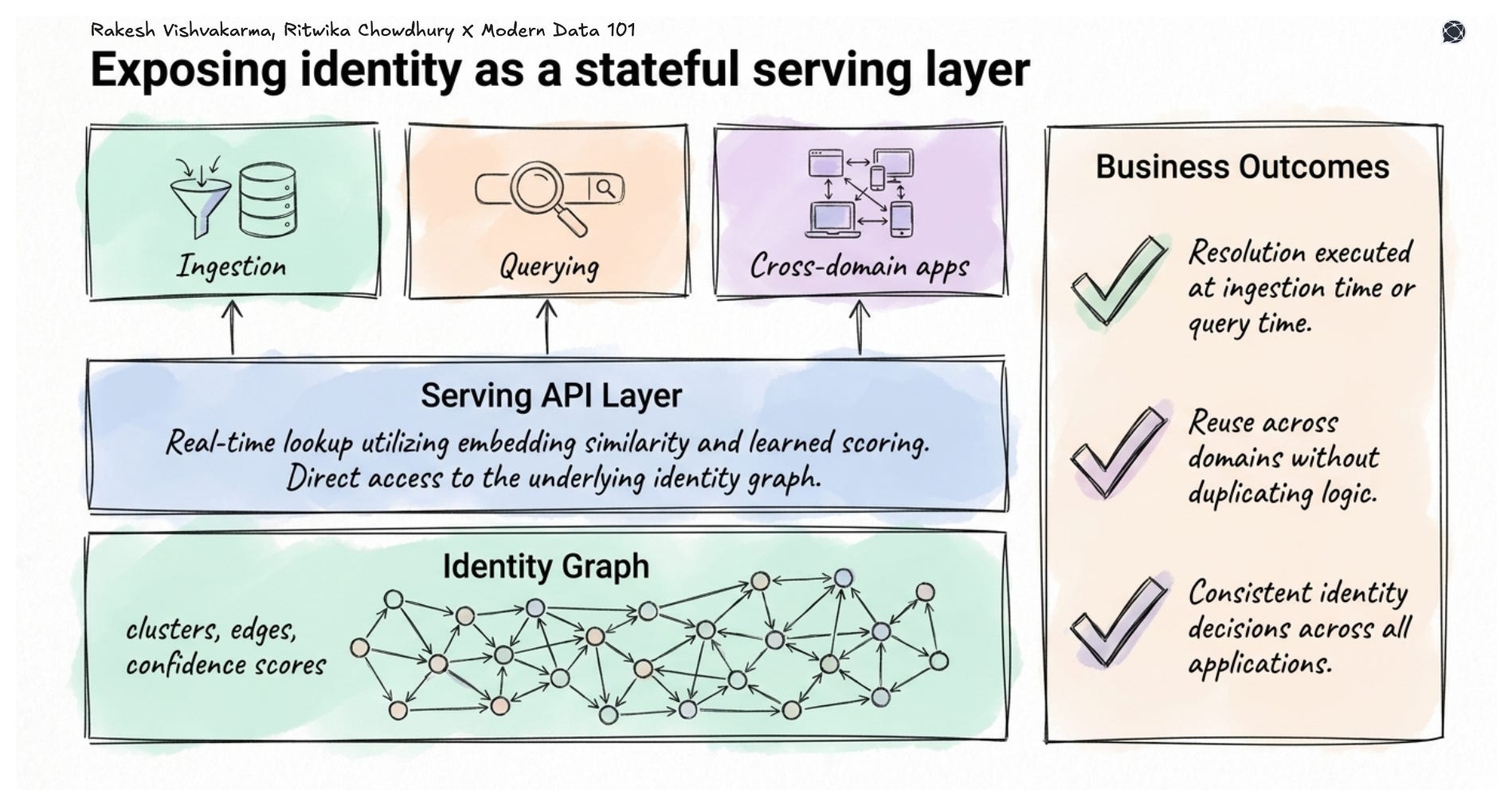
Traditional batch-oriented identity resolution becomes increasingly limiting when downstream applications require identity decisions closer to real time.
Semantic infrastructure and data product thinking combined enable real-time lookup, access to identity graphs, and reusable APIs that can be consumed consistently across applications, analytics workflows, and AI systems. Resolution happens at ingestion or query time. Logic is reused across domains. Decisions stay consistent because everything draws from the same governed, continuously updated capability.
Entity resolution is, therefore a product in its own right, and the rest of your AI stack depends on it.
The honest answer is that most enterprises should not be choosing one or the other; they should be choosing where each earns its place.
Start with your data reality. For a narrow entity domain, structurally consistent records, auditability over a bounded dataset, and rules-based ER is the faster, cheaper, and more defensible path. Regulated industries with exact-match compliance requirements fall here: financial identifiers, government records, and clinical trial data.
Data spanning multiple systems, no reliable unique identifiers, global naming variations, AI agents and real-time data products consuming the output, AI-native is not just better. It is the only approach that does not create a maintenance liability faster than it creates value.
The practical decision comes down to four questions:
1. How much does your data vary? If the answer is significant, across systems, geographies, formats, or time, rules will break faster than you can write them.
2. How fast is your data growing? Rules-based ER scales with human effort. AI-native scales with data. Above a few hundred thousand records with ongoing volume, the operational cost of rules becomes untenable.
3. What consumes the resolved output? The answer matters because different consumers place different demands on identity resolution. Operational systems, analytics platforms, data products, machine learning models, and AI agents all rely on consistent identity, but some require decisions that are more current, context-aware, and continuously maintained than traditional batch pipelines can provide.
4. What is your tolerance for maintenance debt? Rules require constant authorship as data evolves. If the team accountable for ER is also accountable for data product quality, maintenance debt on the rules layer directly competes with product improvement.
The objective is not to optimise entity resolution for AI alone. It is to create a trustworthy identity foundation that can be reused consistently across enterprise systems, analytics, and AI workloads.
Against the current situation, the answer is a deliberate hybrid: rules as guardrails on high-confidence, exact-match cases, same tax ID, same passport number, same regulated identifier, and AI-native handling everything in the ambiguous middle where rules historically break down. The guardrails provide the audit trail compliance teams need. The model handles the volume and variation that rules cannot.
The worst outcome is not choosing the wrong approach. It is choosing neither deliberately, inheriting rules-based ER from a legacy implementation, layering AI tooling on top without governance, and ending up with two systems, neither of which anyone fully owns.
Rule-based AI follows explicit, human-defined logic (if–then rules). It’s deterministic, easy to audit, but brittle and hard to scale with complexity.
Learning-based AI (ML/GenAI) learns patterns from data. It adapts to variability and handles ambiguity, but is probabilistic, less interpretable, and depends heavily on data quality.
AI-first means prioritising using AI wherever it adds value. You still adapt existing systems and workflows to include AI.
AI-native is more on the architecture front, where the system is built from the ground up with AI as the core, and where data flows, interfaces, and decisions are designed around it.
Rule-based MDM relies on fixed match/merge rules, such as predictable and explainable, but rigid and hard to maintain as data evolves. It breaks under ambiguity and scale.
AI-native MDM learns patterns from data, including adaptive, context-aware, and better at handling fuzziness and relationships. But it can be opaque and needs feedback loops and governance to stay reliable.
Hence, Rule-based gives control but doesn’t scale; AI-native scales, but only works well when grounded in strong semantics and continuous feedback.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


