



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)
TABLE OF CONTENT


.png)

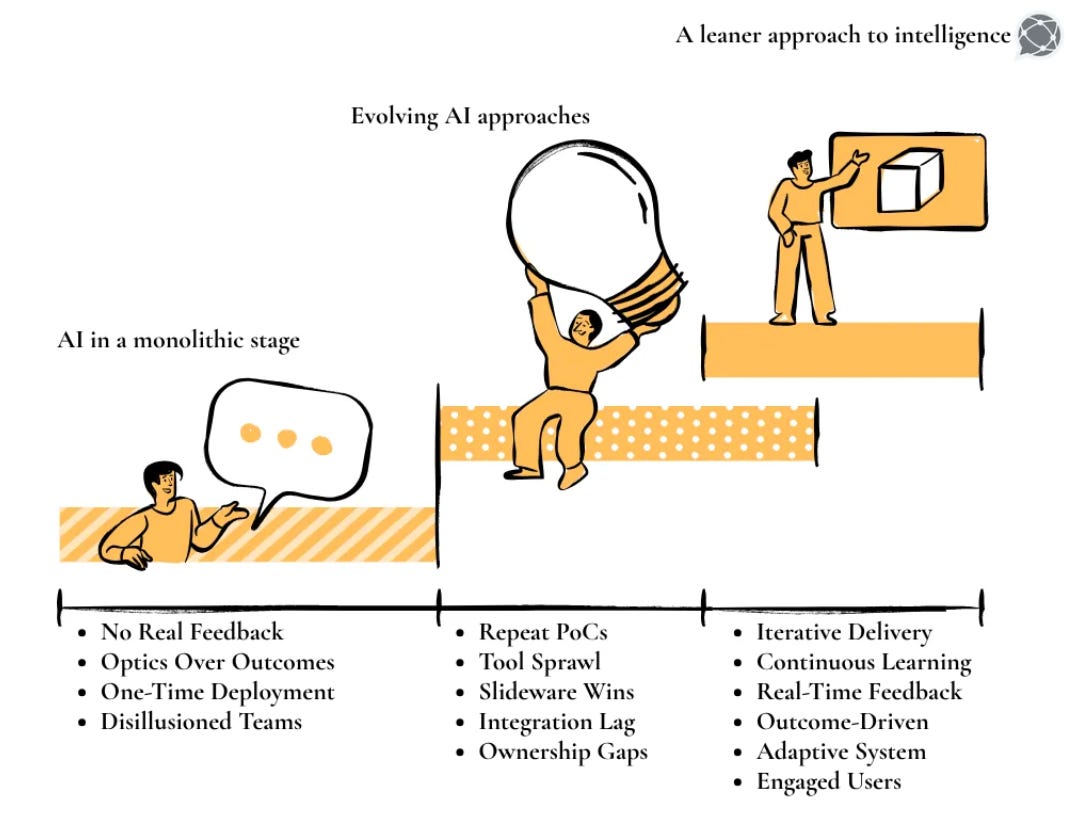
The rolling out of Generative AI tools like ChatGPT, GPT-4, Claude, and others has fundamentally transformed how organisations look at generative AI platforms. Enterprises are no longer asking if they should adopt generative AI; they’re asking how fast and how deep.
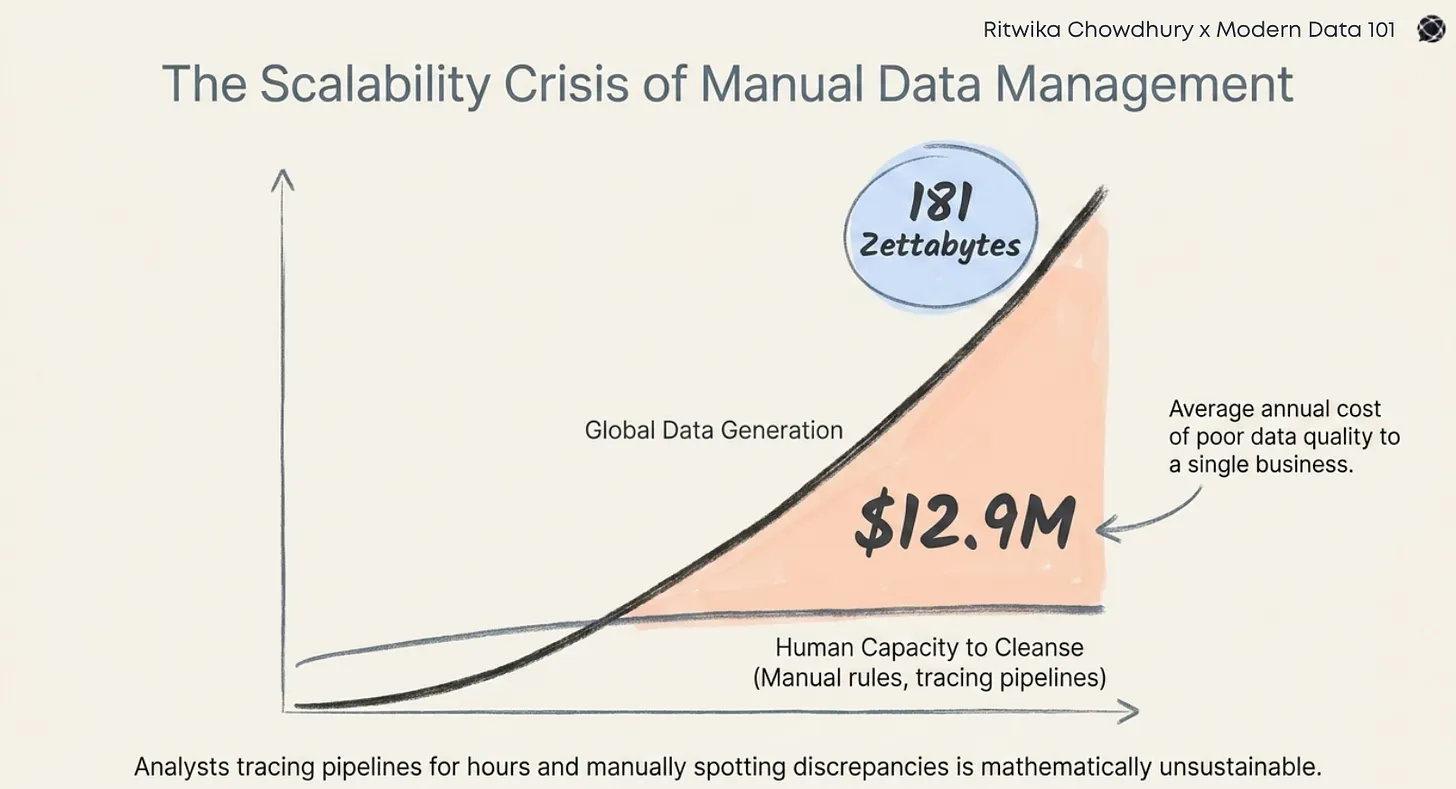
Here’s the cold truth: generative AI in business is no longer speculative. In 2024 alone, private investment in generative AI reached $33.9 billion, comprising nearly one-fifth of all AI sector funding (up 18.7 % from 2023). Meanwhile, adoption is accelerating. 78 % of organisations now report using AI in at least one business function, and 71 % indicate they use generative AI in some capacity. Despite that momentum, many enterprises struggle to move from pilots to production.
The numbers tell a compelling story! LLMs have pushed the frontier of possibilities organisations can achieve with GenAI, and they are scrambling to catch up.
But underneath the rush lies a critical challenge: unless your data foundation is ready for generative workloads, your AI ambitions risk underdelivering (or failing outright).
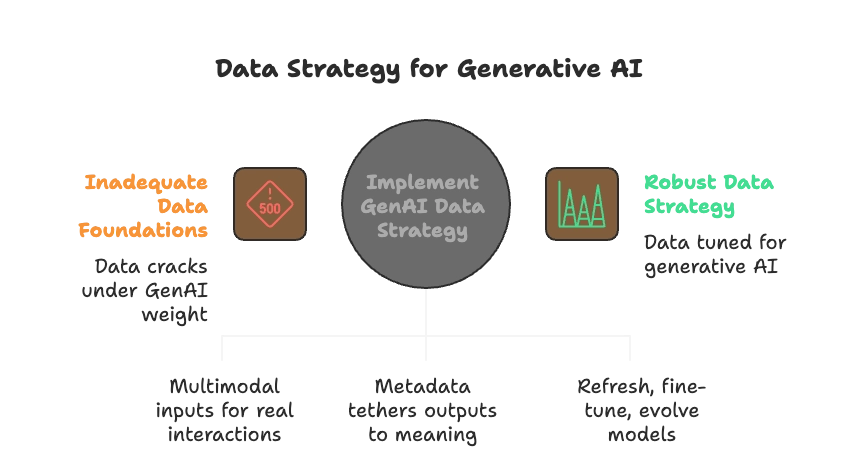
Synergy between GenAI and Data Strategy
GenAI and the data foundation must be co-designed, with data readiness, data quality, and governance baked into the AI journey.
Generative AI implementation requires data that behaves differently. Unlike traditional AI, which could thrive on neatly labelled, structured sets, generative systems draw from an ever-widening pool of text, images, code, audio, and beyond. What elevates this from “just more data” to a true strategy shift is the demand for:
💡The “good enough” data foundations of yesterday that are built for dashboards or predictive models, crack under this weight. Without a strategy tuned for generative AI, organisations inherit higher hallucination rates, bias amplification, compliance blind spots, and ultimately, an erosion of business trust.
The excitement around generative AI applications hides a harder truth: these systems don’t behave like the analytics or predictive ML platforms enterprises are used to. Think about a Chief Data Officer or a strategic decision maker for AI, anyone charged with scaling GenAI responsibly, the challenges are less about the model itself and more about the new kinds of data demands that underpin it.
LLMs can generate fluent, human-like responses, but without enterprise context, they’re irrelevant and sometimes risky. Unlike predictive ML that often operates on pre-labelled datasets, Gen AI platforms and systems must be grounded in proprietary knowledge, lineage, and metadata. Missing this layer turns an otherwise powerful model into a “generic chatbot” with little business value.
Unlike other AI systems, GenAI requires continuous feedback like prompts, corrections, user ratings, and reinforcement from domain experts. Yet most organisations treat this feedback as transient rather than as structured data. Without a strategy to capture and productise feedback, enterprises can’t improve models systematically or scale human-in-the-loop governance.
[related-1]
LLMs have a myriad of needs. Every extra gigabyte of data moved, duplicated, or poorly prepared multiplies the compute spend. Unlike predictive AI, where training was episodic, GenAI workloads often involve ongoing retrieval, fine-tuning, and embedding updates. Without a reuse-first data product strategy, costs spiral and ROI erodes.
Generative AI implementation and adoption also bring along the need to convert unstructured data into structured, usable formats. Most enterprise data exists in text, documents, images, or logs, which are hard to analyse or govern without transformation. GenAI can surface insights directly from unstructured sources, but for scalable AI, analytics, and compliance, organisations still need structured data products that make this information reliable, reusable, and governable.
Addressing the unique challenges of generative AI requires more than incremental tweaks to existing data operations. Enterprises need a purpose-built strategy that aligns data, governance, and technology to the scale and nuance GenAI demands.
The missing link in most GenAI strategies is often the ability to operationalise data as a product. Generative AI demands diversity, context, trust, and continuous feedback, and that requires a foundation where every dataset behaves like a first-class, consumable product. This is where a data developer platform comes into play.
.png)
Generative AI thrives on diversity and context, yet most organisations still operate in fragmented silos. Deploying a unified data platform that brings structured, semi-structured, and unstructured data into a coherent, accessible ecosystem.
[related-2]
This focuses on connecting the dots between data products and the domains, ensuring they are discoverable, reusable, and ready for AI consumption. A unified stack reduces duplication, accelerates experimentation, and ensures every model is grounded in reliable enterprise knowledge.
Scaling generative AI applications across the enterprise is like a marathon. A phased, iterative approach allows organisations to embed learning at every stage while managing risk. It begins with assessing current data assets, identifying gaps, and mapping high-value GenAI use cases, then moves into implementation, where pipelines are built, datasets are productised, and GenAI capabilities are integrated on top of the unified data stack.
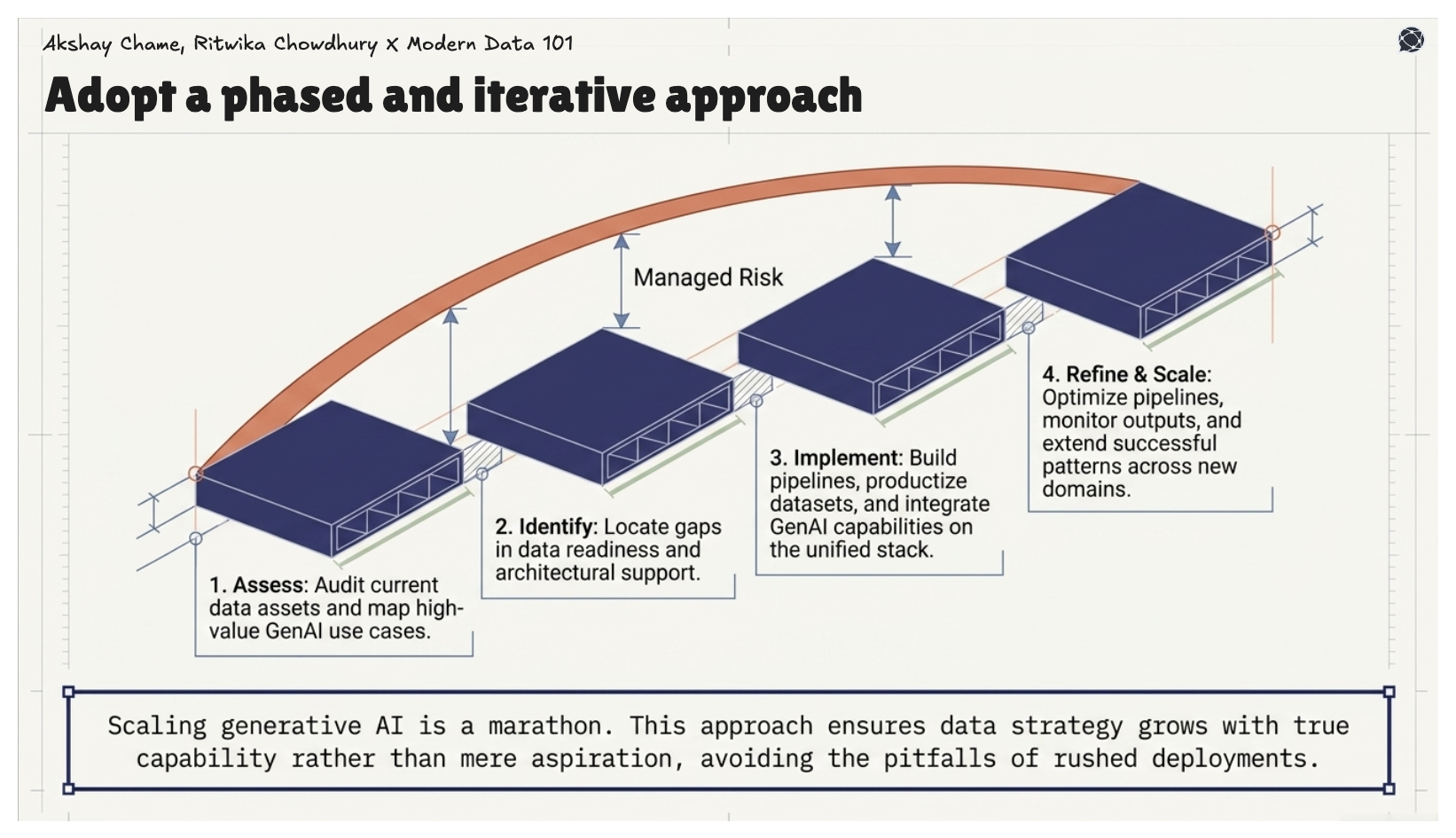
Organised strategies evolve through continuous refinement and scaling, by optimising pipelines, monitoring outputs, and extending successful patterns across domains. This approach ensures data strategy grows with capability rather than aspiration, avoiding the common pitfalls of rushed deployments.
Trust is the currency of generative AI, and a data governance strategy cannot be an afterthought. Hallucinations, bias, and compliance breaches are amplified without governance embedded into the data lifecycle. A robust strategy treats data lineage, provenance, and quality as first-class assets while aligning every dataset and model output with business outcomes and regulatory requirements. Operationalising trust ensures that generative AI scales safely and reliably, and that enterprise stakeholders have confidence in both the insights produced and the decisions made using AI.
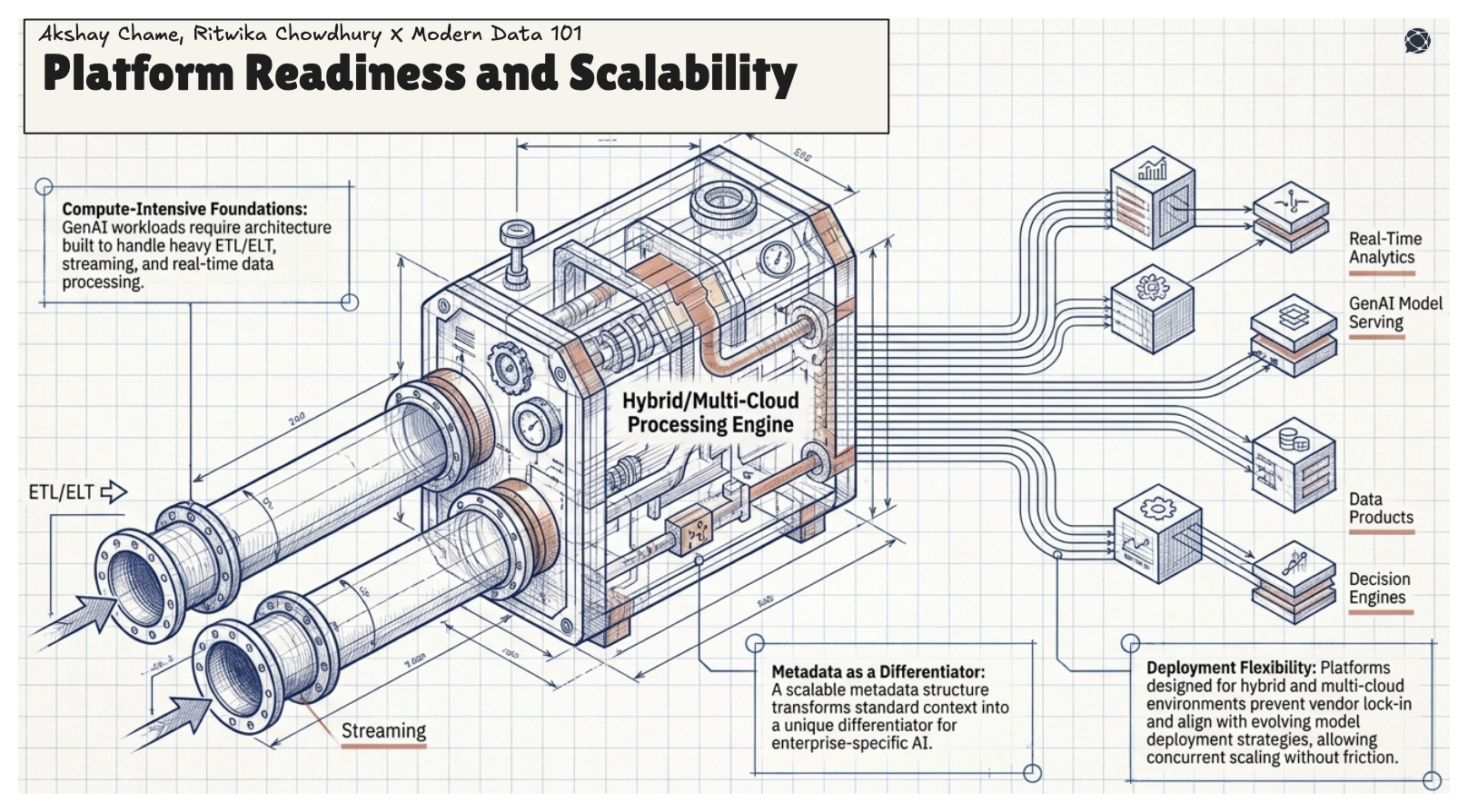
GenAI workloads are compute- and data-intensive, and the underlying platform must be built to handle them. The architecture should support ETL/ELT, streaming, and real-time data processing, while a scalable metadata structure turns context into a differentiator for enterprise-specific AI.
Platforms designed for hybrid and multi-cloud deployment enable avoiding vendor lock-in and remain aligned with evolving model deployment strategies. A platform built for scale allows multiple GenAI applications to be operationalised concurrently without friction.
Outcomes of Generative AI tools’ outputs are only as trustworthy as the feedback loops that refine them. Expert validation must be captured at every stage, from prompt design to output review, and integrated back into the data lifecycle. Metrics should go beyond accuracy to include usability, trust, and adoption, ensuring that both models and human users continuously improve. Treating human feedback as a first-class data asset transforms it into reusable intelligence that strengthens the enterprise’s AI ecosystem over time.
Gartner, in one of its reports, predicts that by 2027, over 50% of GenAI models in enterprises will be domain-specific, designed for particular industries or functions. This will drive more efficient, cost-effective, and precise AI solutions, enhancing both decision-making and operational performance.
GenAI applications are setting foot into creating newer trends with more personalised, context-aware interactions with near-accurate anticipation of customer needs, boosting satisfaction, engagement, and loyalty. Customer expectations will evolve toward on-demand, AI-driven services, demanding hyper-personalisation, seamless engagement, and proactive support across every touchpoint.
Generative AI creates content like text, images, or code, based on patterns in data, but it acts passively on prompts. Agentic AI can plan, reason, and take autonomous actions, coordinating tasks across systems or workflows. Essentially, generative AI produces outputs, while agentic AI decides and acts toward goals.
Two key use cases for generative AI are: creating content and media such as text, images, and code, and powering intelligent automation through chatbots or AI agents that handle tasks, workflows, or decision support. Both leverage data diversity and context to deliver business value.
Key components of a data strategy are:
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.

.avif "Brij Mohan Singh")
