



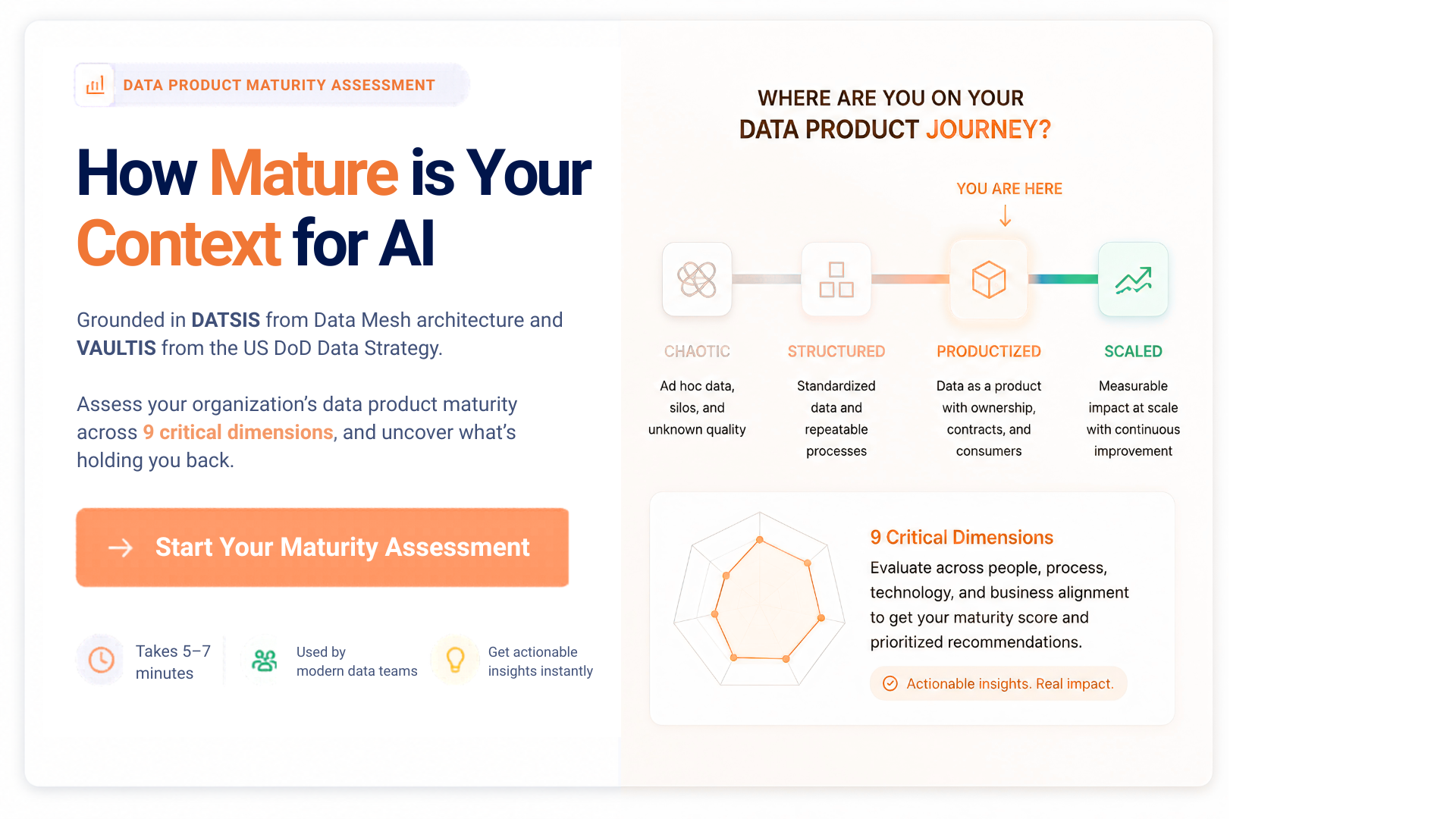
Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
.png)

.png)

.png)

TABLE OF CONTENT


.png)

A lot of businesses believe they have a Customer 360, but what they end up working with is a “Customer 120”: a patchwork of mismatched identifiers, stale contact details, and transaction histories fragmented across a dozen disconnected systems.
The gap between these two things is an identity problem.
When your Point of Sale system records a purchase from "John Smith", and your e-commerce platform logs a visit from "J. Smith," most systems register two separate individuals. The result: siloed metrics, distorted Customer Lifetime Value models, and personalisation campaigns that miss by a mile.
.png)
The path to a unified Customer 360 view is not paved with more storage or better dashboards. It runs through entity resolution: the disciplined, often underestimated process of linking fragmented records to a single, real-world individual.
In this guide, we break down why Customer 360 initiatives fail, what entity resolution actually requires, and how to build identity as a persistent, governed Identity Data Product that improves over time instead of degrading the moment your source systems change.
The core mistake is trying to force alignment at the application layer instead of the identity layer.
An enterprise launches a Customer 360 initiative. The team connects CRM, e-commerce, loyalty, and support data into a centralised warehouse. Dashboards are built. Reports are run. And then someone notices: the "same" customer appears seven times, with different email addresses, slightly different names, and purchase histories that never quite add up.
This is the predictable outcome of building a 360-degree view on top of unresolved identity. The data is there, and the architecture is there. But the identity layer is not.
Customers today interact across an average of six touchpoints before making a purchase decision: online shop, email, social media, mobile app, in-store, and support. Each new touchpoint creates another stream of data, and another opportunity for that data to enter a silo disconnected from the rest. Without a structured approach to unifying that data at the identity level, organisations build blind spots into the architecture by design, not by accident.
The first question a Customer 360 initiative must answer is not "where do we store the data?" but "how do we know that two records represent the same person?"
[related-1]
Entity resolution is the process of determining that two distinct records refer to the same real-world entity, even when the data is noisy, inconsistent, or deliberately obfuscated.
This distinction is important because it defines the complexity of what you are building.
Deduplication removes exact or near-exact copies of a record within a single system. It is a narrow operation: find the duplicates, collapse them.
Entity resolution is broader and harder. It asks whether a record in your CRM and a record in your loyalty program represent the same human being, even when they differ in name format, email address, postal address, or date of birth.
The methods differ accordingly:
.png)
Deterministic matching is the high-precision approach. Records are linked based on exact or near-exact matches on a defined set of fields like social security number, email, or passport ID. Precision is high while coverage is low. Deterministic logic alone fails the moment human data gets messy: an email address gets abandoned, a name is abbreviated, an address is mistyped.
Probabilistic matching estimates the likelihood that two records refer to the same entity based on weighted similarity across multiple attributes. Modern implementations apply machine learning to continuously refine match confidence scores as new data arrives. This approach handles the "fuzzy reality of human data", and it is now the standard in enterprise-grade identity resolution systems.
The industry standard is a hybrid approach: deterministic logic for precision on high-confidence identifiers, probabilistic models for recall across the long tail of messy, real-world data.
[related-2]
If you treat entity resolution as a one-time project, it will degrade the moment your source systems change. If you treat it as a Data Product, it becomes a competitive asset.
This is the most strategically important shift in how organisations approach Customer 360, and it is one validated thoroughly by the data product lifecycle framework.
A data cleanup project has a start date, an end date, and a budget. A Data Product has an owner, a quality SLO, a versioning policy, and a consumer interface. The former degrades by design. The latter improves over time.
Treating your resolved identity set as a first-class Identity Data Product means operationalising three things:
The team closest to the data defines the identity rules. A central IT team that does not understand the nuance of the customer journey or the difference between a household identity and an individual identity will produce resolution logic that fits nobody's needs.
As Jose Almeida’s governance framework documents, dirty data persists in organisations because of ownership gaps: the data is treated as a byproduct of business operations rather than as an asset with a named steward.
Resolved identity profiles should be accessible through a data catalog or marketplace, discoverable to marketing, sales, and data science teams without each team rebuilding resolution logic independently.
As data contracts and data product governance show, without discoverability, teams default to shadow resolution, creating private, incompatible versions of the same customer record.
[related-3]
A Data Product is held accountable to measurable quality standards. For identity, this means answering practical questions at design time:
These are product decisions that determine whether your Customer 360 is trustworthy at the moment of activation.
Explore how unified data stacks implement this pattern in production through DataOS, whose architecture treat governed data products as the central operational unit instead of isolated datasets.
[related-4]
Entity resolution is an act of engineering. Here is the architecture that separates robust identity graphs from resolution that breaks at scale.
.png)
Before writing a single matching rule, use an Entity Relationship Diagram (ERD) to define what "Customer" means to your specific business. Are you resolving individuals, households, or parent-child account structures? In B2B contexts, is a "customer" a contact or an organisation?
If these relationships are not mapped before you start, your resolution logic will sort records into the wrong buckets, and the errors will compound with every data refresh. This is not a technical decision; it is a business decision that requires domain experts in the room.
Deterministic matching alone is insufficient for production-grade entity resolution. Modern customer datasets are messy by nature: email addresses get abandoned, postal addresses contain typos, and names are abbreviated across systems. A robust Identity Engine combines:
When two records conflict (different phone numbers in two systems, mismatched date of birth), which record is the source of truth? Establishing these merge policies before the resolution pipeline runs is what prevents a unified profile from becoming a corrupted composite.
These policies should be governed through data contracts, formalised as machine-enforceable agreements that define which source system has authority over which attributes under what conditions. Without this, merge outcomes are arbitrary, and the Customer 360 becomes a liability rather than an asset.
The resulting artefact of this three-step process is the Golden Record: a single, authoritative, version-controlled unified customer profile that serves as the source of truth for every downstream system; marketing, analytics, AI, and compliance alike.
In regulated industries, entity resolution is not a competitive differentiator. It is a regulatory requirement.
For financial institutions, fragmented customer profiles are not just a data quality problem but a legal liability. Regulators in banking, insurance, and financial services expect a single, unified view of a customer's risk profile as a baseline for Know Your Customer (KYC) and Anti-Money Laundering (AML) compliance.
The regulatory stakes have risen sharply. The U.S. AML Act of 2024 and the EU's 6th AML Directive (6AMLD) both explicitly require that automated entity resolution systems provide clear, traceable decision processes, meaning resolution logic must be auditable, not black-box.
A recent study found that 74% of financial institutions cite international regulatory alignment and data reconciliation as major challenges, particularly when identity data is siloed or inconsistently recorded across jurisdictions.
The pattern repeats in healthcare (HIPAA-compliant patient record matching), in retail (GDPR consent management across fragmented profiles), and in any regulated industry where data subject requests require an organisation to locate and produce every record tied to a specific individual: a task that is operationally impossible without a resolved identity layer.
Entity resolution at the identity layer is not a hedge against enforcement. It is the prerequisite for compliance that scales.
The most dangerous Customer 360 architecture is the one that works perfectly inside one vendor's walls.
Leading enterprises are moving away from monolithic, proprietary identity platforms that demand you move all your data into their storage in exchange for resolution capabilities. The alternative is Composable Identity: resolution logic that works natively within your existing data warehouse or lakehouse, leaving data governance, lineage, and access control in your hands.
This mirrors the broader architectural shift that is illustrated in the consolidation of the modern data stack: vendors who offer resolution as a "managed service" bundled inside a proprietary platform are not simplifying your architecture. They are creating gravity: a dependency that grows heavier with every customer record you entrust to their system.
A composable approach means:
The Data Developer Platform standard provides an open framework for implementing exactly this kind of composable, governed identity architecture, where the identity engine is a modular component that plugs into the broader data platform, not a walled garden that replaces it.
[playbook]
AI is not limited by compute. It is limited by context. And without resolved identity, every AI model built on customer data is trained on fiction.
An AI personalisation model that trains on a customer's behaviour fragmented across ten different records does not produce ten partial insights. It produces one deeply confused, inaccurate model because it has no concept of which records represent the same person.
The same problem applies to churn prediction, CLV modelling, and next-best-action recommendations. These models require high-fidelity, unified profiles to generate predictions that are actually reliable. Entity resolution is not a preprocessing step that feeds AI. It is the foundational layer that determines whether your AI strategy produces competitive advantage or expensive noise.
This is why the analysis of data products and enterprise AI concludes that data products, including the Identity Data Product, are not optional infrastructure for the agentic era. AI agents cannot guess that Customer_ID_01 in your CRM is the same as loyalty_member_7893 in your rewards platform. They require a governed, resolved identity layer to reason accurately across your enterprise.
Resolved identity is the prerequisite for AI that actually knows your customer.
Deduplication removes exact or near-exact duplicate records within a single system. Entity resolution determines that two records in different systems, with different identifiers, name formats, or contact details, refer to the same real-world individual. Deduplication is a subset of entity resolution. Entity resolution handles the full complexity of human, messy, cross-system data.
A golden record is the single, authoritative version of a customer's data: the master profile that every downstream system trusts as the source of truth. Entity resolution creates the golden record by resolving all fragmented identities related to one individual across source systems and merging them into a single, version-controlled profile, governed by pre-defined merge policies.
For most enterprises, a managed or composable identity service within your existing data warehouse is the better default. Building a custom matching engine from scratch that handles scale, version management, and probabilistic fuzzy logic becomes substantial engineering debt. The right question is not build vs. buy. It is: does the solution I choose keep my data governance and lineage in my control, or does it lock my resolved identity into a proprietary platform?
AI and ML models require clean, unified, high-fidelity input data to produce accurate outputs. A model trained on ten fragmented records representing the same customer produces unreliable predictions on churn, lifetime value, propensity to buy, or risk. Entity resolution feeds your AI a single, resolved customer profile, which directly improves model accuracy, reduces bias from duplicate signals, and enables personalisation that reflects reality.
A genuine Customer 360 requires four things beyond storage: a resolved identity layer (entity resolution), a semantic definition layer (what "Customer" means across systems), a governed data product with clear SLOs (false-positive tolerance, refresh cadence, merge policies), and discoverability, so every team consumes the same resolved profile rather than re-resolving entities independently.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



