


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...




%20(1).png)
TABLE OF CONTENT



402.74 million terabytes of data are generated each day, yet most organisations still haven’t cracked the code of turning data into decisions. The problem isn’t volume; it’s the inability to discover, understand, and trust data, worsened by silos and poor documentation. As predictive analytics, automation, and AI-driven decision-making scale, the gap between available data and accessible data widens. Agentic AI systems depend on fast, reliable access to high-quality data.
That’s where data discovery becomes critical.
Modern enterprises need data that is findable, connected, metadata-rich, and immediately usable. This is why data products and a well-designed Data Developer Platform (DDP) are becoming the baseline, making discovery scalable, systematic, and actionable.
[playbook]
In simple terms, data discovery is the process of identifying, understanding, and exploring data across an organisation. It assists teams in finding the right datasets, identifying where they came from, evaluating their quality, and also understanding how they can be used impactfully.

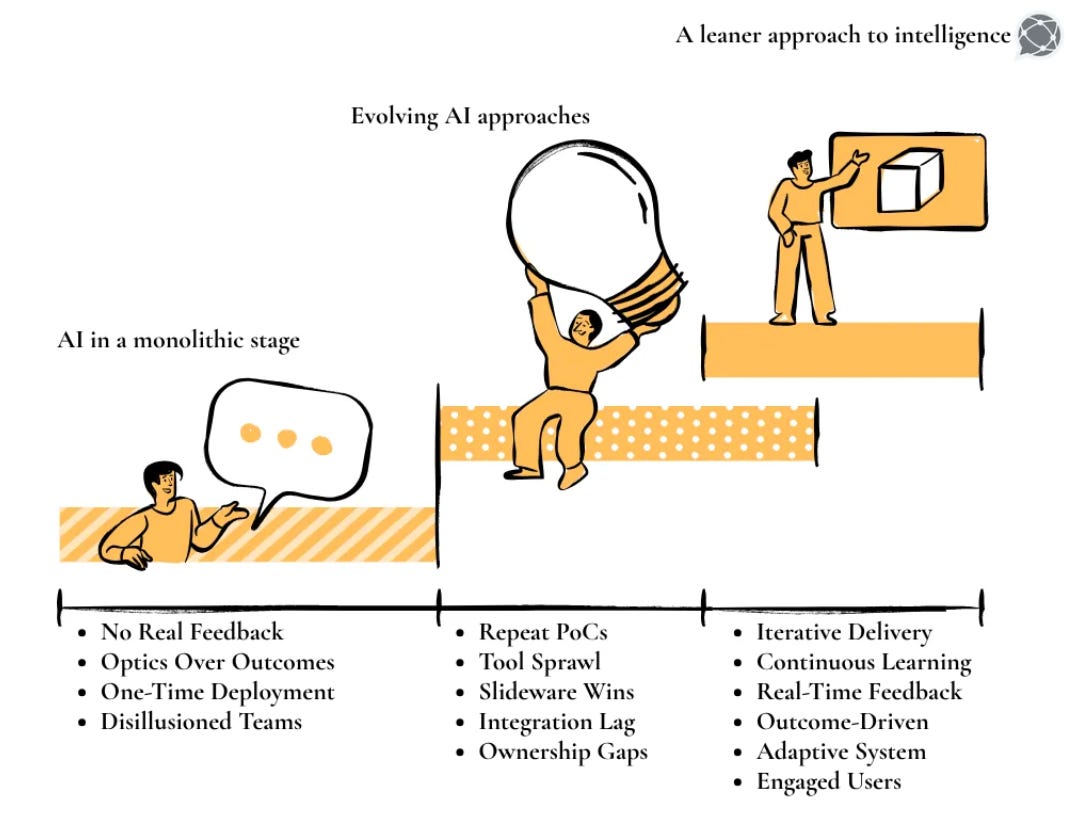
Traditional data discovery primarily focused on BI dashboards and manual exploration. Analysts used to build charts, search for tables, and visually inspect patterns. However, for 2026, this approach is too fragmented and too slow for its own good.
Enterprise data discovery has changed a lot, and this can be summed up in four different ways:

Data discovery today isn’t just about simply “finding data” anymore. It’s now become about understanding the purpose, connections, quality, and readiness for use by both AI systems and humans.
As to how data discovery makes a strong case for enterprise success, I’ve mentioned a few reasons below:
Organisations make multiple decisions every day. Without the proper data discovery framework, teams waste a lot of time searching for the right datasets or recreating the existing work. With semantic search and automated discovery, employees and AI systems instantly get to know what data exists, who owns it, and how trustworthy it is.
You must have heard it quite a few times as a data evangelist:
“Models are only as good as the data that feeds them.” It’s always going to hold!
AI-powered data discovery capabilities, such as profiling, lineage visualisation, and quality scoring, help teams understand data constraints before building models. This cuts down errors, bias, and unexpected performance issues.
[data-expert]
Regulations, such as GDPR, CCPA, and related industry-specific standards, require organisations to maintain complete visibility into how data flows through systems. This is supported by data discovery through:
With clear visibility, enterprises get to reduce risk and also improve compliance in the process.
One of the highest hidden costs in large enterprises is the duplication of data work. Teams often end up creating multiple versions of the same dataset as they’re unaware of a trusted version already out there. Enterprise data discovery takes away this confusion by providing AI systems and employees with a unified view of all available assets.
[related-1]
With self-service analytics, non-technical teams can easily explore insights without waiting for engineering teams. Visual lineage, easy navigation, and semantic search enable anyone, from marketing to operations, to find and use data responsibly.
Future AI systems will autonomously retrieve, evaluate, and apply data.
Without discoverable, governed, and high-quality datasets, these AI agents cannot perform their actions safely. Data discovery is a necessary prerequisite to enable AI autonomy at scale.
[related-2]
Practical data discovery tools share a set of standard capabilities, each supporting a different part of the process.
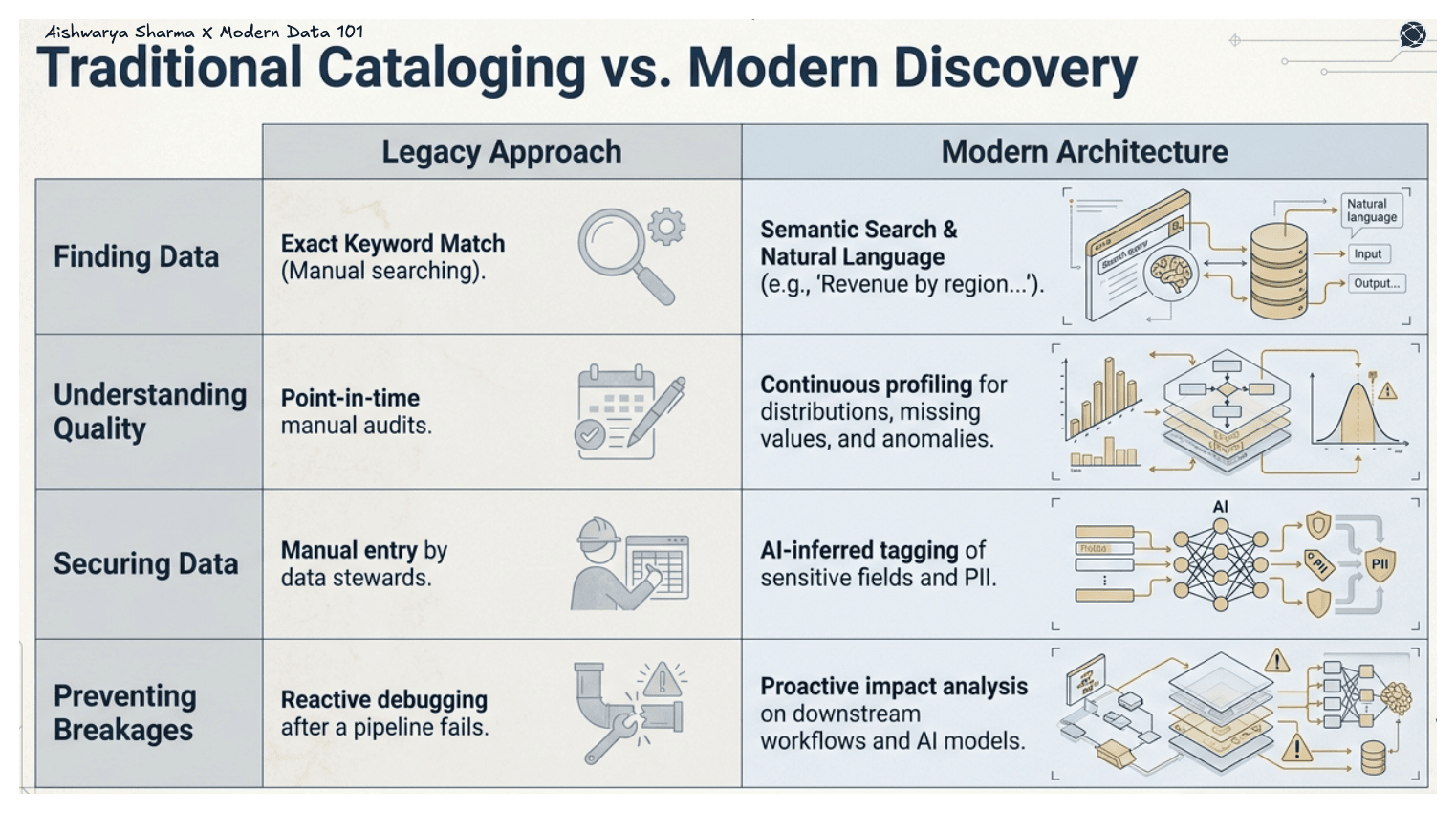
1. Data Profiling and Quality Assessment
Profiling examines the distributions, anomalies, schema, and completeness. Data quality assessment, on the other hand, highlights other crucial aspects such as missing values, duplicates, outliers, or inconsistent formats, allowing teams to trust what they’re using.
2. Natural Language Exploration and Semantic Search
Modern discovery tools use semantic search to ask questions such as:
“Revenue by region for last fiscal or quarter…”, and discover reliably tagged, high-quality datasets to match the intent behind.
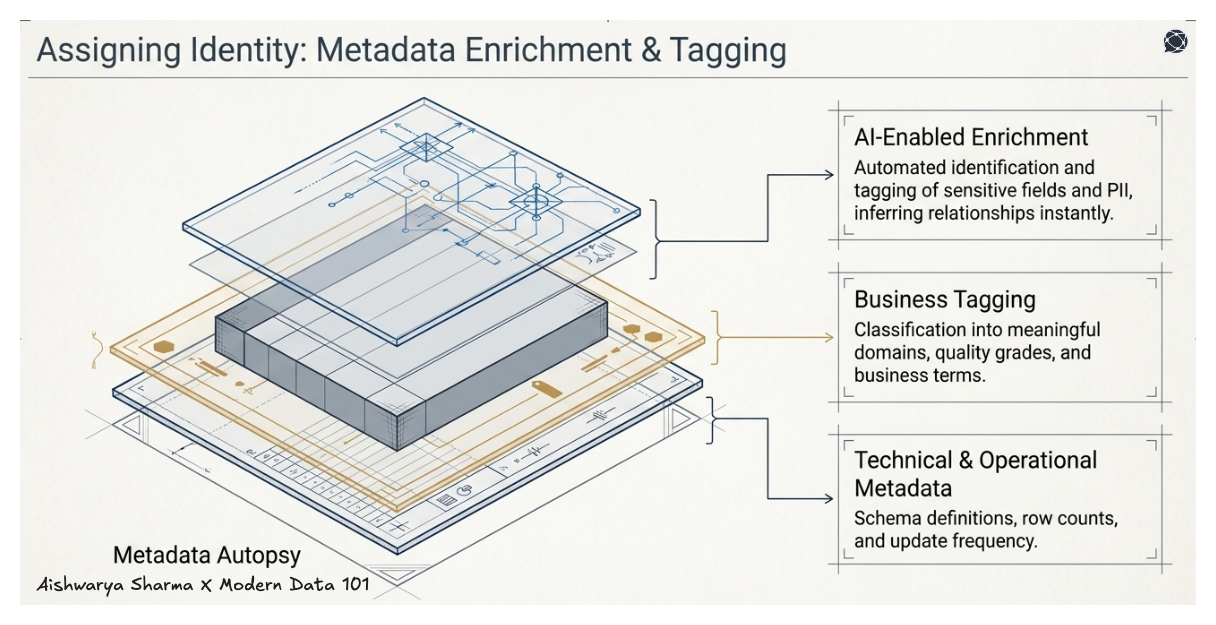
3. Metadata Management and Enrichment
Metadata of any nature, technical, business, or operational, is at the core of enterprise data discovery. AI-enabled enrichment automatically helps in tagging sensitive fields, identifies PII, and then infers relationships, to name a few essential activities in the process.
4. Data Lineage and Impact Analysis
Data lineage depicts where the data originated, how it transformed, and where it is consumed. Impact analysis enables teams to be warned early before making any changes that could break workflows, dashboards, or AI models.
[related-3]
5. Tagging and Classification
Tagging helps in organising datasets into meaningful categories, such as sensitivity levels, domains, quality grades, business terms, and more.
6. Automated AI Recommendations
AI assists in recommending datasets, highlighting frequently used assets, and then identifying duplicate data.
7. Collaborative Governance
Glossaries, annotations, and governance rules bring a common understanding between ownership and compliance. When combined, these components constitute the backbone of optimal data discovery in current businesses.
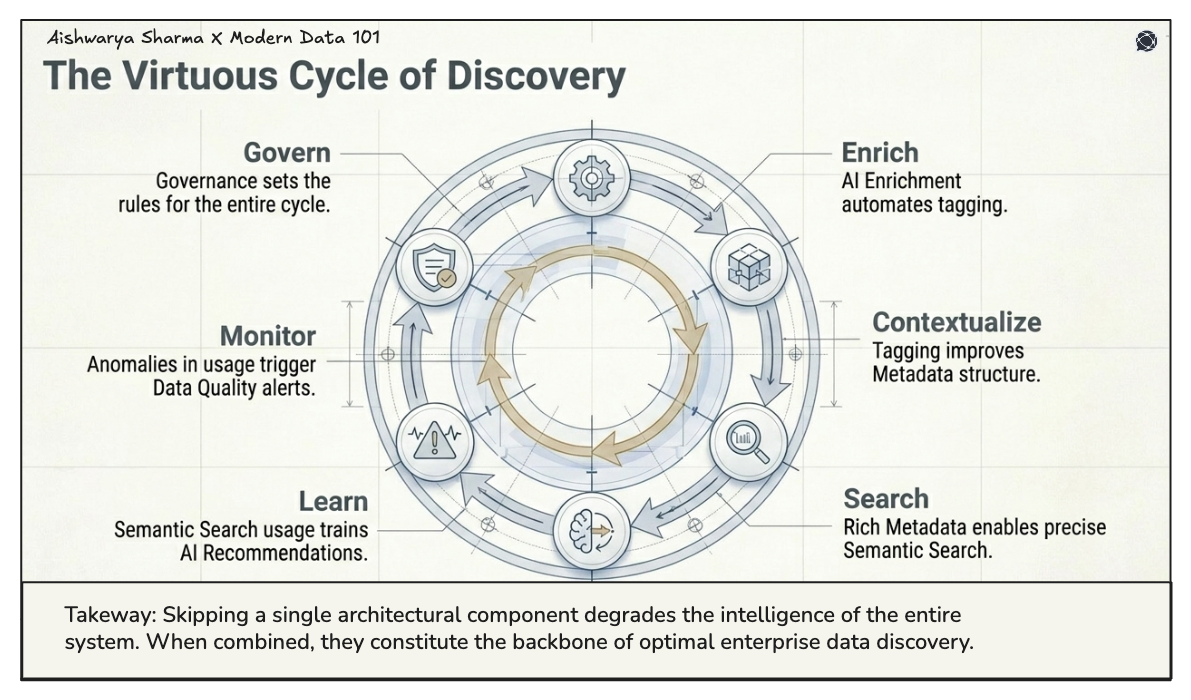
For enterprises today, data discovery is optimised when operating within a data product and data developer platform (DDP) ecosystem.
Turning a data asset into a data product packages data with its clear ownership, lineage, metadata, and context, alongside adding governance metrics like quality checks, SLAs, access controls, and standardised interfaces. This cuts down duplication, takes away the ambiguity, and also ensures that AI systems and users aren’t just finding data, but that they are discovering ready-to-use, consistently governed products.
Discoverability is one of the essential attributes that a data product must have, meaning it should be easy to find by consumers within the organisation.
1. A Data Developer Platform’s Modularity Makes the Discoverability Function
A DDP is built from atomic, modular resources that each serve a unique purpose in how data and metadata are structured. These standardised resources enable semantic uniformity across data products, e.g., consistent naming, taxonomy, metadata schemas, and APIs.
With such modular, composable blocks, every data product shares a common semantic foundation, which makes it far easier to discover them consistently across environments. Hence, search engines and discovery tools can use consistent metadata to index data products reliably. Users don’t hunt through silos; metadata is unified, referenced, and retrievable programmatically.
This is one of the ways DDP transitions from siloed “data assets” into discoverable, addressable, and interoperable data products.
2. DDP Amplifies Discoverability through Unified Metadata
Metadata is captured as part of the data product itself, through the platform’s central control plane and APIs. These capabilities enable rich descriptions that are machine-readable, semantic gateways for auto-indexing, and programmatic APIs for metadata and search. So a data product is addressable via standardised identifiers and metadata, making it findable through search, APIs, or catalog UIs.
3. Semantic Consistency Enables Search and Context
As a DDP enforces a shared semantic layer, taxonomies, ontologies, classifications, and semantic labels are standard across all products. This allows discovery tooling to be meaningful, not just present.
Users can find products by business domain, data topic or entity, by lineage connections, and by schema or metrics used. This is far superior to discovering raw data tables in disparate systems.
[related-4]
In a dynamic era where data volume is exponentially growing, data discovery is no longer optional. It’s now fundamental to AI adoption and operational excellence. Enterprises investing in structured discovery will get boosted by data products and a robust data developer platform, enabling users as well as AI systems to find, trust, and apply data instantly.
Data discovery assists organisations in quickly finding well-governed and trusted data to improve decision-making speed, cut down duplication, and offer teams self-service access. It also boosts compliance, ensures AI-readiness, and leads to better ROI from data investments.
An excellent approach is to treat discovery as a product capability. Teams, with a data developer platform, can automate lineage, unify metadata, enable self-service, and embed multiple quality signals. It also ensures that teams and AI models can always access contextual, trusted, and production-ready data.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



.avif "Brij Mohan Singh")
