


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



For years, data was merely a technical component of applications, a simple support mechanism for maintenance. Today, it has taken on a new dimension: it has become a product with its own uses, requirements, and lifecycle.
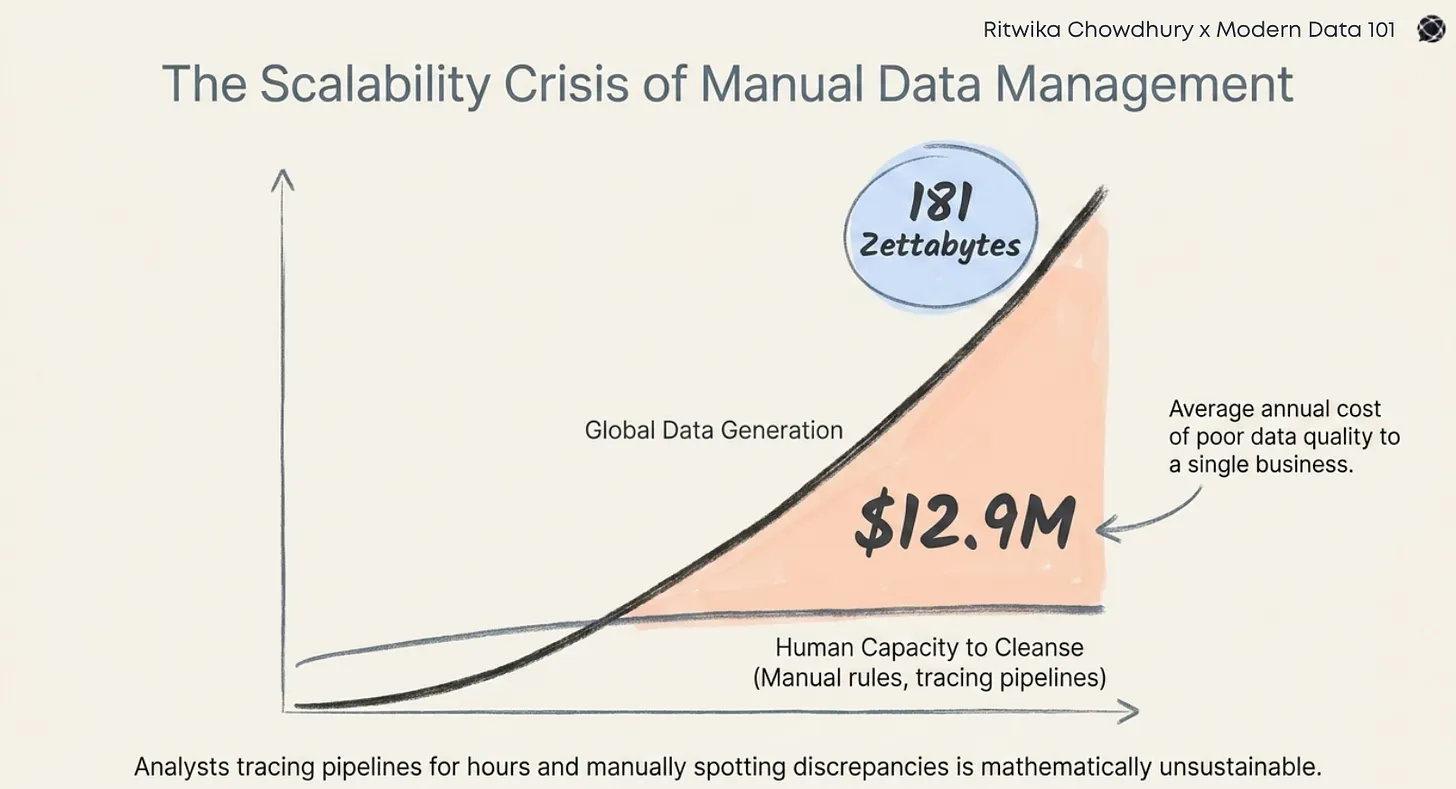
However, most data systems still act like fragile pipelines:
These situations have shaped a clear conviction: The real challenge today is to design systems that adapt, preserve trust, and remain coherent as the business evolves.
A robust data product is therefore much more than a workflow. It is a long-lived digital asset that encodes business meaning, enforces data quality, traces change, and supports continuous evolution without friction.
In this article, I’m laying out five engineering pillars that I’ve seen consistently turn data products from “some scripts that work for now” into components you can trust long-term.
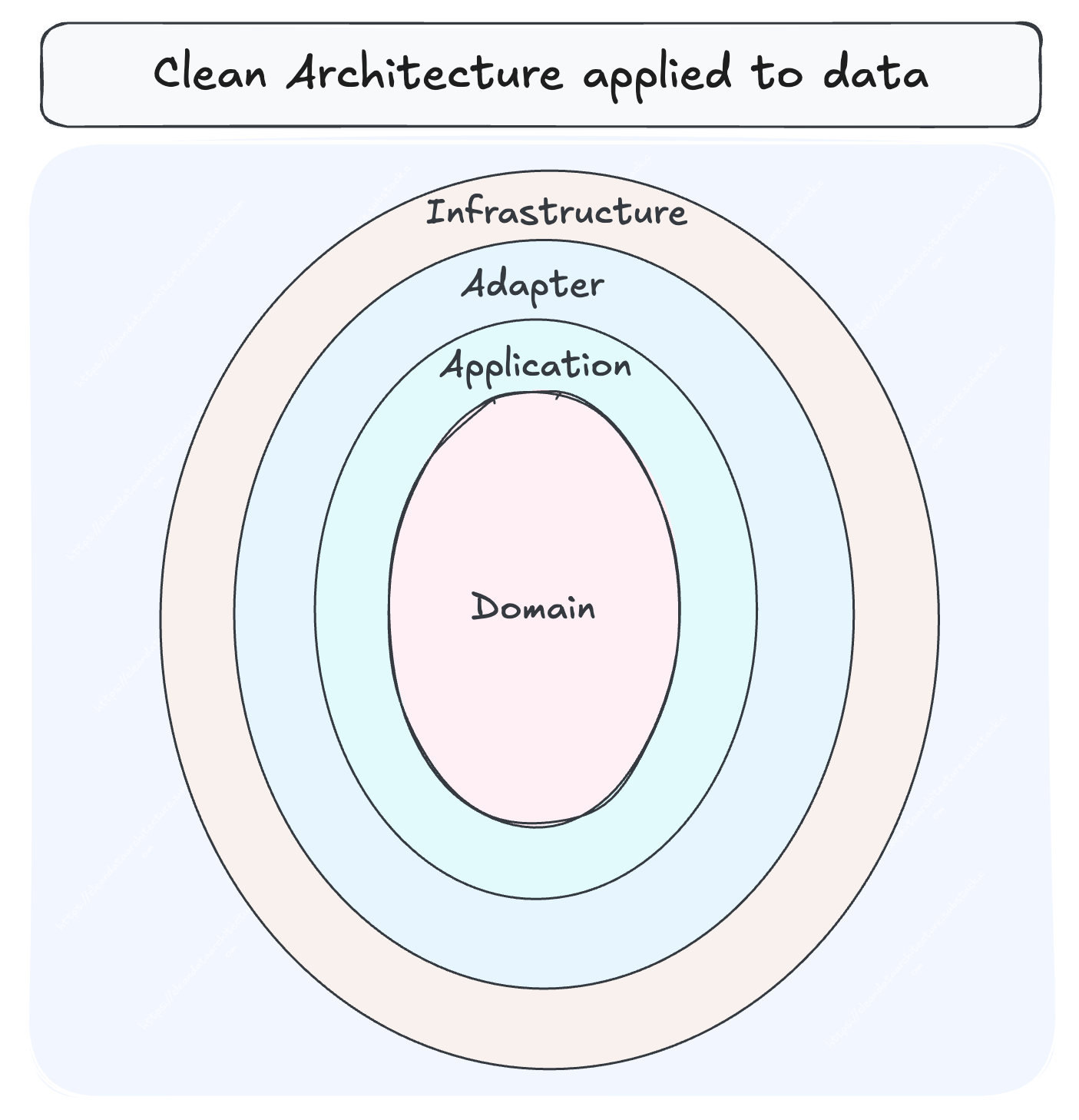
Clean Architecture, based on the classic onion model, gives you a practical way to create a demarcation between what should stay stable and what will inevitably change. In real world scenarios, infrastructure shifts all the time, but the business logic usually doesn’t. The onion just makes that separation obvious.
At the center is the code that should barely move: the rules, the definitions, the meaning of the business itself. As you move outward, the layers get more volatile and more technical. And that’s the whole point.
The core stays calm while the edges take the churn. The further outward you go, the more technical and replaceable the components become.
Business logic sits at the core. A dedicated domain layer encapsulates the true semantics of the business:
The infrastructure forms the outer layers that can change without affecting the domain logic. We include in infrastructure:
Each domain carries its own:
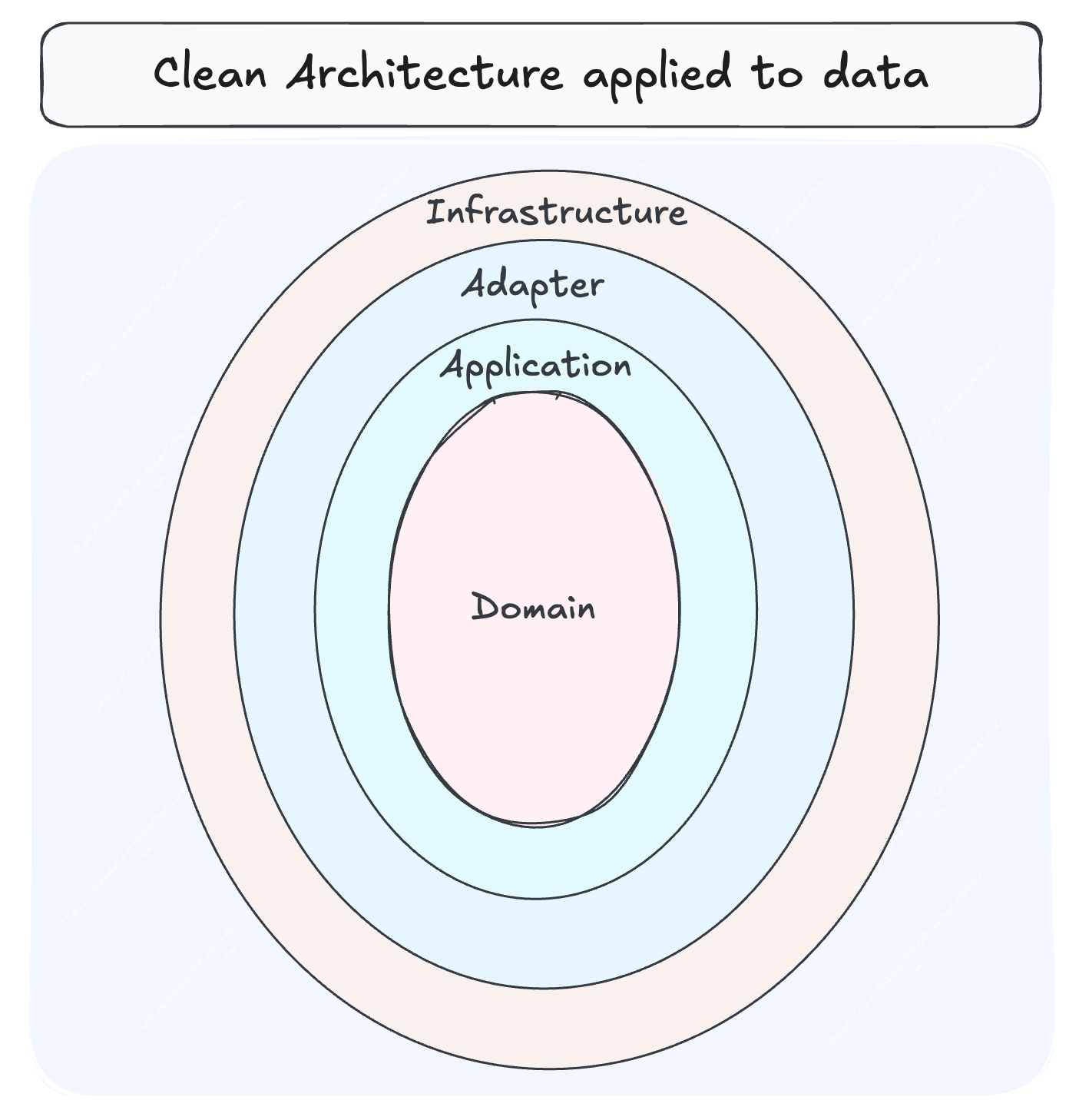
From the center outward:
Business rules depend on nothing. Outer layers depend on the components inward, never the other way.
[playbook]
Most data products are still tested primarily at the unit level, and even this coverage can vary significantly depending on team maturity. Many data engineers are early in their careers, and pipelines are often treated as “scripts that work” rather than full software products.
A helpful framework to think about test coverage is the testing pyramid:

Let’s focus on the functional tests.
It should represent the business rules independently of the infrastructure.
Beyond this foundational testing, Behavior-Driven Development (BDD) is gaining traction in data engineering. BDD allows teams to capture complex business rules in executable, human-readable scenarios using the Gherkin language.
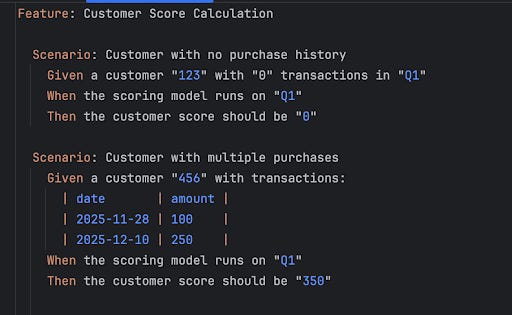
Business rules are expressed in natural language, versioned in Git, and validated before deployment.
A robust workflow looks like this:
By combining a solid base of unit and integration tests with functional BDD scenarios, data products can evolve safely, maintain trust, and make business rules explicit.
[data-expert]
Modern pipelines must be replayable on demand. A change in business logic should propagate to historical data safely and automatically.
A dedicated service handles everything that traditionally makes backfills painful:
No more clicking through 500 dates in an orchestrator UI. The system does the heavy lifting.
A data model is a living system - it grows, mutates, and sometimes breaks. A mature data product must support:
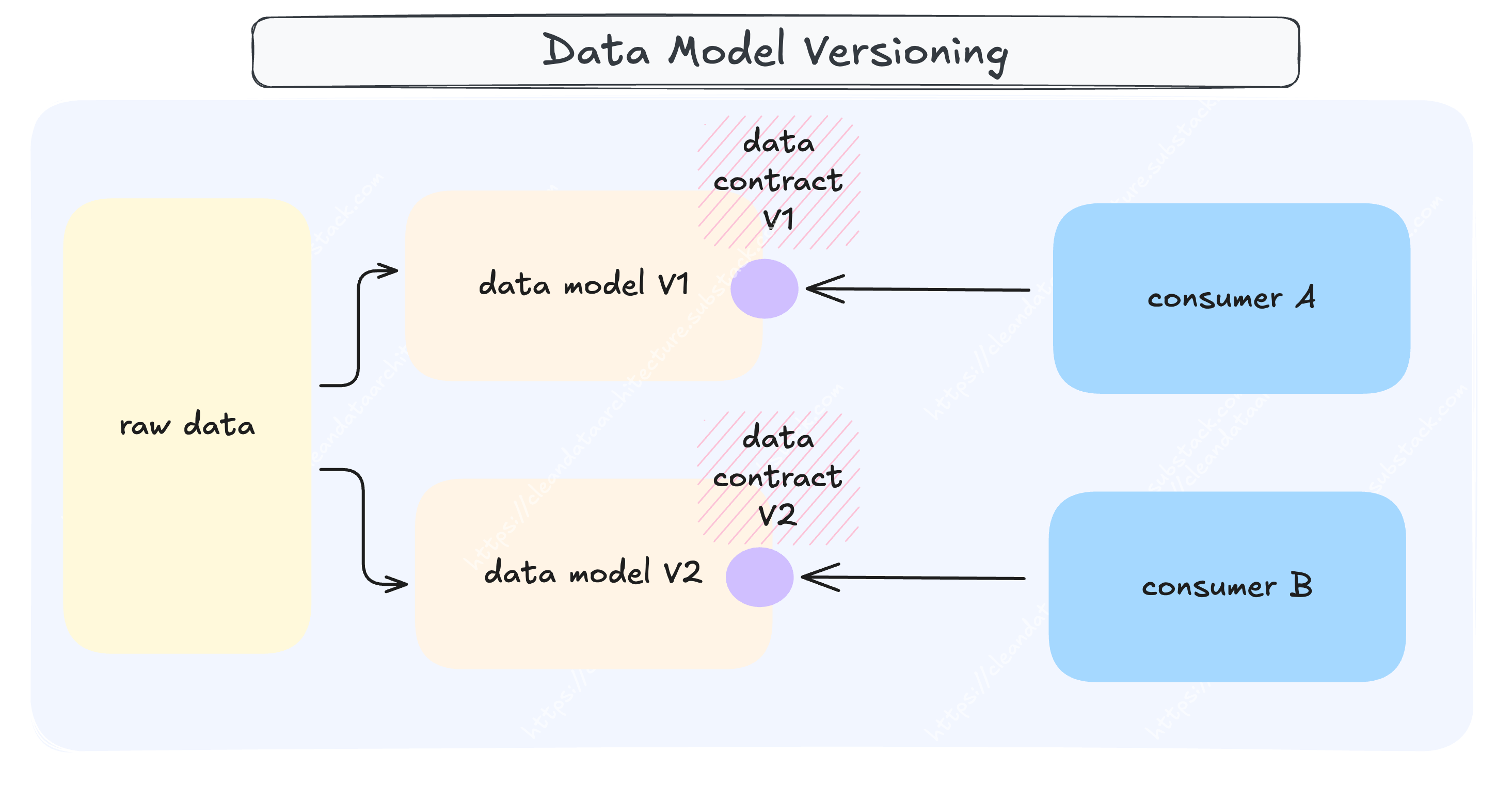
Your data model should evolve without stopping production and impact our consumers.
Data quality is often treated as a low priority and mainly for reporting purposes.
However, this approach can lead to incidents that have a significant business impact.
Integrating data quality checks directly into data pipelines enables data producers to proactively detect anomalies. By exposing data quality metadata, data consumers can determine whether the data meets the required standards for their use cases and better control potential business risks.
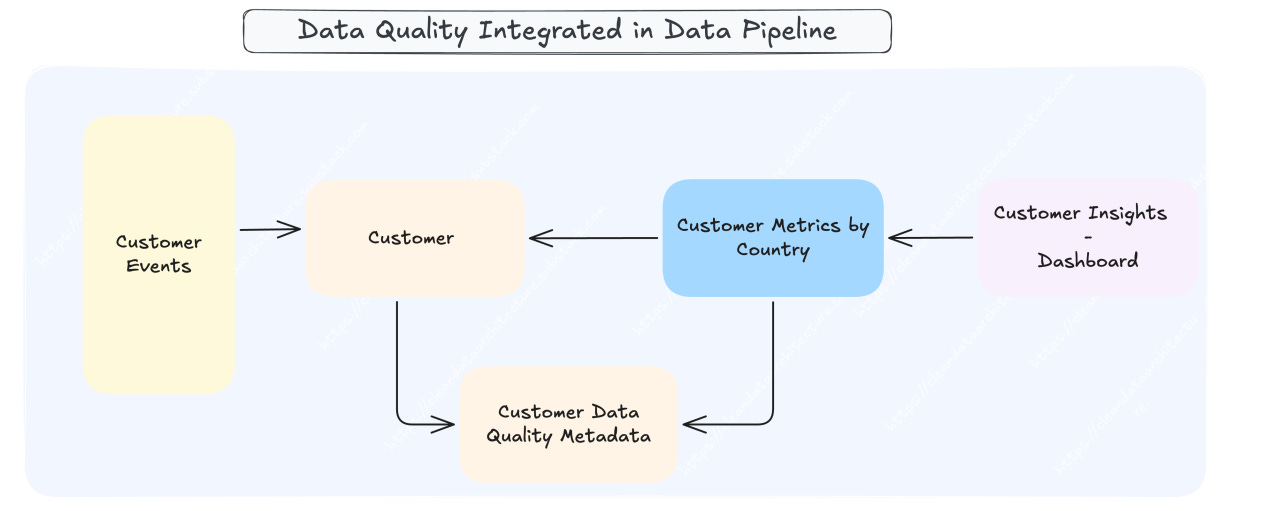
Coverage should include:
Silent anomalies are extremely expensive and too often detected by end users, not by the Data Product team.
When you look at each pillar on its own, it solves a specific challenge. But when we bring them together, they become consistent and create a unified approach. Downstream, users are able to trust and consume the data confidently. Even as business logic, schemas, or infrastructure evolves, downstream requirements are not compromised.
Clean architecture, automated tests, reprocessing capabilities, controlled schema evolution, and proactive monitoring create a foundation that lets teams move from reactive firefighting to predictable, stable operations.
This is what turns a simple pipeline into a robust data product, and a Data Engineer into someone who builds software-quality systems rather than fragile workflows.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




