


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)

.jpg)
TABLE OF CONTENT


.png)

AI data management is the practice of structuring, governing, and packaging enterprise data so AI systems can consume it reliably at scale. The data beneath AI deployments fails is built for human analysts, not machines, and that is why it fails. This post is for data leaders evaluating what AI-ready infrastructure actually requires.
This post is for data leaders evaluating what AI-ready infrastructure actually requires.
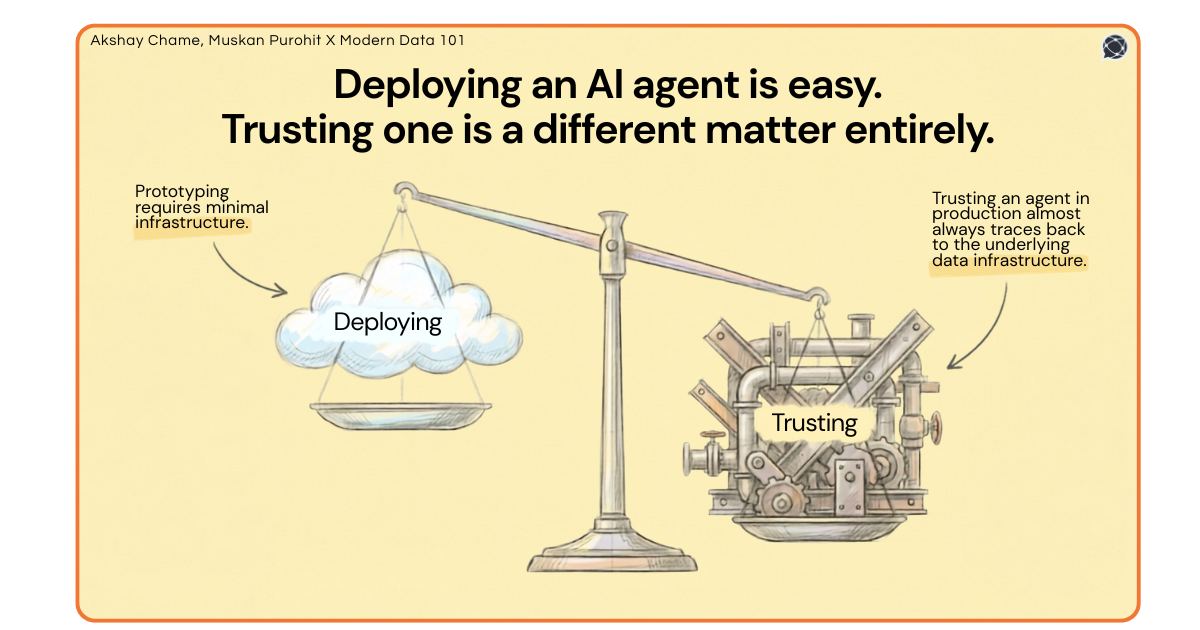
Deploying an AI agent is easy. Trusting one is a different matter entirely, and that gap almost always traces back to data management infrastructure.
The failures tend to look deceptively simple: a procurement agent can't reconcile supplier records because the same vendor exists under four different names across three ERP systems, or a customer service agent surfaces pricing that's six weeks out of date. This is what happens when data built for human interpretation gets handed to machines that can't fill in the gaps themselves.
"AI-ready data" has become one of those phrases that sounds self-explanatory until you try to build for it. The requirements are specific, and most data estates weren't designed with any of them in mind.
Traditional pipelines were built for human latency: batch schedules, daily refreshes, an analyst reviewing the output the next morning.
Agentic AI operates differently; it doesn't tolerate ambiguity. When an agent queries a customer entity, it needs one authoritative answer, not three slightly different records from three source systems. When it reads a product catalogue, it needs consistent schemas, not the structural patchwork that accumulates when systems coexist without a unifying contract.
The requirements shift is significant:
.png)
Engineering teams will recognise this immediately. It maps directly to what they encounter when trying to productionise AI workflows on top of existing data estates.
[report-2025]
.png)
There's a tendency to frame AI readiness as a data quality problem: are the records complete, are the formats consistent, is the pipeline fresh? That framing is just incomplete because the deeper issue is whether the data means anything unambiguous to a machine reading it without context, and that's a metadata question.
If a customer_id could mean three different things depending on the system it came from, the agent doesn't know which one applies. That ambiguity has to be resolved somewhere because if it's not in the metadata, it resolves incorrectly in the output in the wrong manner.
The cost of getting metadata wrong has changed. A human analyst misreading a field definition causes a bad report. An agent misreading it can trigger cascading automated decisions, repriced contracts, rejected claims, and incorrectly routed escalations. It's the plumbing that determines whether AI automation is trustworthy at all.
.png)
[related-1]
Entity resolution has been a data engineering concern for decades, matching records that describe the same real-world thing across systems that never agreed on a common identifier. It was always worth doing properly. In agentic workflows, doing it badly has immediate operational consequences rather than just untidy reports.
Consider a compliance automation agent cross-referencing counterparties against a sanctions list. If the same counterparty appears under four different identifiers across trading and onboarding systems, the agent either flags everything conservatively or misses matches. Neither outcome is acceptable.
.png)
Practically, this means that building a knowledge graph that can support downstream AI systems, one that encodes entity relationships, canonical identifiers, and provenance, is increasingly a precondition for reliable automation, not a future optimisation.
Treating data as a product, with an owner, a defined interface, a quality SLA, and a documented consumer contract was originally conceived for human consumers. It turns out to be even better suited to machine consumers.
An AI agent that consumes a well-defined data product with stable schemas, observable lineage, explicit ownership, and versioned outputs can be built to a contract. Changes to the underlying data are visible, and degradation triggers alerts. The agent's behaviour is therefore traceable and debuggable in ways that agents consuming raw warehouse tables simply are not.
As automation becomes more widespread, traceability and accountability become essential governance needs, not just tools for troubleshooting.
[related-2]
.png)
Traditional data governance was largely retrospective, auditing what happened, documenting lineage after the fact, and enforcing access policies through human review cycles. That model works when humans are making decisions and can be held accountable. It breaks down when decisions are being made at machine speed, at scale, by agents that no individual oversees in real time.
Access control, quality checks, and policy enforcement need to happen at the moment a data asset is queried or consumed, not in a weekly audit cycle.
The practical implication: governance frameworks need to be rebuilt around composable policy primitives that can be attached to data products and enforced at runtime. Governance needs to be embedded directly into the data management platform; enforced at runtime, not delegated to a review process that runs on a quarterly cycle.
[state-of-data-products]
The conventional instinct when confronting AI data management gaps is to reach for tooling first. But tooling built on top of unresolved entities and ungoverned access inherits every structural failure it was supposed to fix.
.png)
Start at the data contract layer: resolve entities, document schemas, and enforce access policy at the platform level before selecting any AI system that depends on them.
.png)
Good governance rests on transparency, accountability, fairness, and the effective use of resources in decision-making. For data governance for AI, this means policies enforced at the point data is queried, not reviewed after the fact.
Data is the actual content; metadata is the information describing it, such as author, file size, or creation date. In data management, metadata gives machines the context data alone cannot provide.
Metadata enables effective search, organisation, access control, and AI readiness by providing essential context and structure for large datasets. It is foundational to enterprise data management at scale.
AI-ready data is high-quality, clearly labelled, free from errors or duplicates, and includes semantic context and real-time updates. It is the baseline requirement for agentic AI to operate reliably.
Getting the data layer right is also what determines whether AI actually pays for itself. Our recent piece on Lean AI: Building a Scalable Data Platform for Enterprise AI ROI walks through what that looks like in practice.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




