



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.jpg)


TABLE OF CONTENT



Enterprises everywhere are pouring resources into AI to unlock efficiency and innovation, and outpace competition. Yet beneath the surface, data pipelines are convoluted in a hidden architecture of constraints, blocking AI from realistically scaling.
Key Findings:
This paper highlights four technical barriers to practical or scalable AI solutions: semantic ambiguity, data quality degradation, temporal misalignment, and format inconsistency. These issues require inline governance solutions and data architectures specifically designed for machines instead of human users.
Organizations must transition from traditional ETL-based data pipelines to AI-native data product architectures that ensure quality, provide semantic clarity, and deliver the reliability necessary for production AI systems.
In this paper, you’ll find:
Most organizations operate data ecosystems built over decades of system acquisitions, custom development, and integration projects. These systems were designed for transactional processing and business reporting, not for the real-time, high-quality, semantically rich data requirements of modern AI applications.
Research shows that 50% of organizations are classified as "Beginners" in data maturity, 18% are "Dauntless" with high AI aspirations but poor data foundations, 18% are "Conservatives" with strong foundations but limited AI adoption, and only 14% are "Front Runners" achieving both data maturity and AI scale².
Most organizations operate fragmented data flows where information moves from System A through custom ETL processes to a data warehouse, requiring manual quality assurance. Simultaneously, System B feeds data through separate custom ETL processes to a data lake for feature engineering. Legacy systems add another layer of complexity, routing through additional custom ETL processes to analytics platforms for model training. This fragmented approach creates four critical failure points that prevent reliable AI deployment.
Research reveals the following impact:
The Problem: Traditional data pipelines decouple business context from data during transformation (traditional legacy transforms with barely any insights from business personas). AI models are left to operate on technically correct but meaningless data which doesn't translate to the business user's mindspace.
Customer data arrives as a cipher. Codes without context. In the row, “CUST001, A, 3, 1299.50, 2024-03-15,”
Without semantics, none of it is information. "Insight" is out of question.
Production system data often strips reality to bare codes. What remains are fragments (item IDs, quantities, status flags, warehouse markers), technical skeletons with no flesh of meaning. The system speaks in numbers and letters, but without embedded rules of the business, its voice is mute.
AI Impact: When training on such stripped-down records, machine learning learns only the shape of the code, not the map of the business. The result: outputs that are precise in form yet misaligned in intent: recommendations that look correct to the machine but fall apart in practice.
The Problem: Pipelines are not neutral. Each transformation step is both an act of refinement and an act of distortion. What begins as reasonably accurate data at the source (say 95% fidelity) rarely arrives intact at its destination. Instead, every join, aggregation, mapping, and enrichment introduces subtle fractures.
Data rarely decays all at once. It corrodes step by step, each transformation shaving away a fraction of truth until what reaches the AI model barely resembles its origin.
At the source, systems begin with a respectable accuracy, around 95%. Then the slow erosion begins. The first ETL transformation trims this to 90%. A second pass brings it down to 85%. Feature engineering, meant to enrich, cuts deeper, leaving only 75%. By the time the dataset arrives at the AI training stage, what once stood near 95% strength is now diluted to 60–70%: dangerously below the 99%+ reliability required for machine learning to hold its promise.
This erosion becomes vivid in something as common as customer order processing. It begins with customer data extraction at 95% accuracy, but as order history is joined, mismatched IDs across systems drag it to 88%. Product category mapping pulls it down further to 79%, where inconsistencies in business rules across departments chip away at trust. When the final step of calculating customer metrics arrives, the compounded effect of dirty inputs leaves accuracy hovering around 71%. What begins as small cracks at the edges soon spreads into the foundation—null values, mismatched identifiers, conflicting rules, and aggregation errors that multiply with each step.
An e-commerce recommendation engine trained on such data does not fail spectacularly but rather dissolves quietly into irrelevance. It begins to recommend products to customers who never purchased them, misfires with suggestions outside their budgets, overlooks seasonal preferences, and ultimately generates results that feel detached from reality.
The Problem: Enterprise systems do not march in sync. They run on their own clocks, scattered across time zones and schedules, and in doing so, they fracture the temporal fabric of data. This misalignment slips quietly into AI pipelines, where training models unknowingly draw on fragments of the future to explain the past.
Say, a sales forecasting pipeline is stretched across the geography of an enterprise. Sales data is extracted at 8:00 AM Eastern, inventory follows hours later at 11:30 AM Pacific, weather feeds arrive at 2:00 PM Central, and marketing campaign logs finally trickle in at 4:00 PM Mountain. What seems like harmless scheduling reveals itself as a structural fault: the training data does not respect time’s arrow.
In this arrangement, the model learns to predict morning sales using afternoon weather, or interprets campaigns launched late in the day as if they were already in play when the transactions occurred. Temporal leakage creeps into the training loop, and the model builds a world that can never exist in production. It assumes knowledge that will never be available at the moment of prediction, embedding a subtle but fatal flaw into its design.
During production operation, the temporal misalignment becomes critical. When making 8 AM sales predictions, the system expects 2 PM weather data that hasn't been collected yet. Marketing campaign effects assume future campaign launch times that haven't occurred. Inventory optimization requires data that won't be available for several hours.
Temporal misalignment is just as corrosive in customer support as it is in sales forecasting. A customer submits a question at 9:00 AM, but the knowledge base they depend on is not updated until 2:00 PM, and the ticket carrying final resolution details is closed only at 4:30 PM. The dataset appears whole, yet it is stitched together from events that never coexisted in time.
When trained on this sequence, the chatbot absorbs a false rhythm. It learns to resolve morning inquiries with answers that were written hours later, and to draw on resolutions that only appeared at the end of the day. In production, this illusion collapses: the 9:00 AM customer cannot see into 2:00 PM.
The model expects knowledge that does not yet exist, and in doing so, it builds confidence on ground that is not there.
The Problem: Enterprise systems rarely speak the same language. Each one encodes the world in its own dialect of identifiers, formats, and categories, and with every new AI use case, these differences compound into unbounded overheads; creating integration challenges that multiply with each new AI use case.
An e-commerce system may describe an item as “PROD_12345” under a neat hierarchy like Electronics > Computers > Laptops. The inventory system insists on “12345-LAPTOP” with cryptic department tags such as “ELEC.” Financial systems add another layer of complexity with item codes like "L-12345" and numeric department codes.
Price representation creates additional integration challenges. E-commerce platforms display prices with currency symbols like "$299.99", inventory systems store decimal values like "299.99", and financial systems might use integer cents like "29999". Stock status varies from boolean true/false values to numeric quantities to single-character codes.
Timestamp formats compound the integration nightmare. E-commerce timestamps follow ISO standards, inventory follow regional formats with time zones, and finance reduces all to compressed numeric strings. What should be a single moment or a single product splinters into incompatible versions of reality, frustrating any attempt at correlation or temporal analysis.
A CRM logs a customer as “CRM-2024-001234.” A support ticket system knows them only as “TKT_15MAR24_1430.” A knowledge base links their issue to an article tagged “KB-BILLING-299.” What one system calls a “Billing Question” of medium priority, another abbreviates to “BILL_INQ” with a numeric urgency, while the knowledge base files it away as “Payment Issues” with its own difficulty rating.
To an AI system charged with routing support, this noise of identifiers and categories is inconvenient and debilitating (leading to hallucinations). Correlation requires painstaking ID mapping. Terminology demands translation. Priority scores refuse to align. And knowledge base retrieval falters under mismatched vocabularies.
AI Impact: Recommendation engines struggle to connect user preferences that aree scattered across incompatible systems. When product identifiers do not line up, inventory managment systmes collapse producing forecasts unrelated to stock realities. Customer service AI drifts into irrelevance when category mismatches block accurate routing and retrieval. Fraud detection (which depends on subtle signals across domains) misses critical patterns as evidence dissolves in the noise of conflicting formats.
Traditional data governance operates as external oversight after processing, where data flows through pipelines and processing steps, produces outputs, undergoes quality checks, and finally receives business review. This sequential approach creates several problems for AI applications.
Modern data product architectures embed governance directly into data processing, creating a unified approach where data products combine raw data with embedded rules, quality guarantees, and business context in a single, manageable entity.
A customer profile data product with embedded governance transforms data from a loose collection of attributes into a contractually reliable foundation for business. Quality thresholds are no longer vague aspirations but enforceable standards: completeness above 99.5%, accuracy surpassing 99.8%, freshness guaranteed within fifteen minutes, and consistency upheld through automatic checks such as email validation, phone normalization, and address geocoding.
Business rules become part of the data fabric itself. Age values are constrained within 18 and 120. Purchase histories are unable to accept negative values. Loyalty status is bound to a closed set of categories (bronze, silver, gold, platinum) rather than drifting into variants. Geographic fields align strictly to postal codes, eliminating the chaos invalid regions. The data product ceases to be passive storage; it enforces logic as it flows.
On top of this, semantic annotations correlate raw attributes with business meaning. Customer segments inherit definitions from marketing categories, with metrics such as lifetime value and behavioral patterns recalculated on a weekly cadence. Churn risk is not a vague score but a precisely defined probability of departure within ninety days, expressed between zero and one and tied explicitly to model versioning. With governance, business rules, and semantics woven together, the customer profile emerges as more than data, it becomes a living product with guarantees, context, and trust built into its very design.
Inventory data products implement real-time validation to prevent the common data quality issues. When inventory records show negative values without implying backorder status, the system immediately flags validation alerts. Future timestamps get detected / rejected to prevent temporal inconsistencies. Location codes undergo validation against approved warehouse and distribution center listings to ensure operational accuracy.
These data products automatically enrich raw inventory records with essential business context. Seasonal demand factors get calculated based on product category and current time period, providing AI systems with seasonality intelligence.
Inline governance does more than tidy data; it reshapes outcomes. Research shows that when quality rules are enforced at the source, model accuracy climbs from the mid-seventies into the ninety-percent range. Data preparation, once consuming the majority of a project’s timeline, shrinks from sixty percent of effort to just twenty. Even the brittleness of production deployment is transformed, with model failures falling by 85%.
The effect is most striking in real-time decision systems. Fraud detection engines, armed with validated inputs, cut false positives by sixty percent. Recommendation systems, enriched with semantic context, see click-through rates surge 40%. Inventory management guided by business rules, reduces stockouts by more than 1/3rd.
Modern enterprises operate across distributed data landscapes where systems are constantly evolving, being replaced, or undergoing transformation. In this dynamic environment, the semantic layer within data products becomes the critical foundation that provides consistent business context regardless of underlying system changes.
Traditional approaches lose semantic meaning when data crosses system boundaries. A customer record becomes a collection of meaningless field names and codes. A transaction loses its relationship to business processes. Product information becomes disconnected from operational rules and constraints.
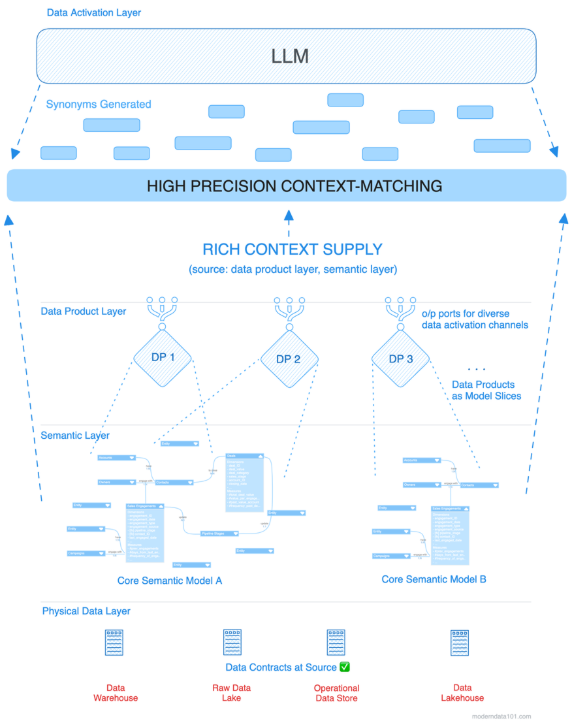
The semantic layer in data products serves as the authoritative source of business meaning that persists across system transformations. Instead of raw technical fields, it provides rich business context that AI systems can understand and act upon.
Consider a customer record: raw data might show "segment: 3, score: 847, flag: Y" which provides no actionable insight. But the semantic layer transforms it into meaningful context: "high-value customer with excellent credit, eligible for priority support and premium offers." This context enables AI agents / systems to make appropriate business decisions rather than only statistical correlations.
As underlying systems evolve, the semantic layer maintains business continuity. When organizations replace legacy systems with modern platforms, field names change, data formats shift, and business logic gets restructured. Without semantic layers, every AI system breaks during these transitions.
For example, a legacy system might represent premium customers as "cust_type: PREM" while a new system uses "customer_tier: premium." The semantic layer recognizes both representations refer to the same business concept: high-value customers deserving specialized treatment. AI systems continue functioning seamlessly because they work with consistent semantic meaning rather than brittle technical formats.
Traditional data preparation focuses on making data technically compatible with machine learning algorithms. Data products with semantic layers go further, they make data action-ready by embedding the business context necessary for automated decision-making.
Action-ready data includes not just the facts but the business rules, constraints, and implications needed for autonomous operation. An inventory record becomes more than stock levels or static restock insights. It now includes reorder policies, supplier relationships, financial impact, and response triggers. This 360 degree context enables AI systems to take appropriate actions autonomously without constant human intervention.
For inventory management, action-ready data would include demand patterns, reorder thresholds, supplier lead times, cost implications, and predefined responses to different scenarios. When stock levels drop below thresholds, the AI system goes beyond shallow insights like inventory is low. It also "knows" the business impact, appropriate response timeline, and automated actions to take.
In distributed architectures, the semantic layer must operate across multiple systems while maintaining consistency.
The semantic layer coordinates these distributed sources to create unified business context.
This coordination enables comprehensive understanding that no single system provides. Customer risk assessment combines payment history, support interactions, and demographic data. Purchase recommendations take inventory levels, profit margins, and customer preferences into account. The semantic layer is essentially enabling AI to decide by incorporating complete business context rather than partial views from individual systems.
Individual point solutions cannot address the complexity of distributed data environments. Organizations need comprehensive data management platforms that use data products as fundamental building blocks. These platforms must handle semantic layer creation, maintenance, and evolution across hundreds of data sources and dozens of AI applications.
Data products serve as standardized building blocks within these platforms. Each data product encapsulates specific business entities (customers, products, transactions, inventory) with consistent semantics, quality guarantees, and business rules. AI applications consume these building blocks rather than wrestling with raw system data.
The platform approach enables rapid AI deployment because new use cases leverage existing data products rather than starting from scratch. Customer churn prediction reuses customer profile data products. Inventory optimization leverages existing product and demand forecasting data products. Cross-selling recommendations combine customer, product, and transaction data products.
When data products provide action-ready context through semantic layers, AI implementation timelines collapse from months to weeks. Traditional approaches require extensive data discovery, custom integration development, business rule interpretation, and quality assurance, consuming 60-80% of project timelines.
Data product platforms eliminate this overhead. Data discovery becomes browsing a catalog of available data products with guaranteed quality and semantic richness. Integration becomes API calls rather than custom development. Business rules are embedded in semantic layers rather than requiring manual interpretation. Quality assurance is built-in rather than custom-developed.
This acceleration enables organizations to experiment with AI applications rapidly, validate business value quickly, and scale successful use cases efficiently. The semantic layer ensures consistent business context across all AI applications. Avoiding the fragmentation that occurs when each project creates custom data and even AI apps (that do not understand each other).
Perhaps most critically, semantic layers enable operational continuity during the constant system transformations that characterize modern enterprises. AI systems continue functioning when underlying databases are migrated, when SaaS vendors change data formats, or when legacy systems are replaced.
The semantic layer abstracts AI applications from these infrastructure changes. The flow of business context remains consistent and the context map keeps getting updated even as technical implementations evolve. This continuity is essential for mission-critical AI applications that cannot tolerate disruption during system transformation efforts (which is often).
Organizations implementing comprehensive data management platforms with semantic-rich data products report 40% improvement in AI decision relevance and 60% reduction in manual intervention requirements. More importantly, they achieve consistent AI performance across system transformations that would otherwise require complete AI system rebuilding.
Traditional data pipelines create strong barriers to AI's success that cannot be solved through incremental improvements. The challenges of semantic ambiguity, quality degradation, temporal misalignment, and format inconsistency require architectural transformation.
Data product architectures with inline governance provide the quality, semantic clarity, and operational reliability necessary for production AI systems. Organizations that recognize data infrastructure as the foundation of AI success will achieve sustainable competitive advantages, while those persisting with traditional approaches will find reliable AI deployment increasingly difficult.
The evidence is clear: AI-native data architectures are not optional for organizations serious about scaling artificial intelligence capabilities.
References
Additional industry evidence from Netflix Technology Blog (2023) "Building Netflix's Distributed Tracing Infrastructure" and Meta Platforms engineering documentation on data lineage architecture at scale.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
From MD101 🧡
230+ Industry voices with 15+ years of experience on average and from across 48 Countries came together to participate in the first edition of the Modern Data Survey. And together, we uncovered the truths beneath the hype cycles.
And much more!
Get your copy and share your insights with us 🧡
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


