


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


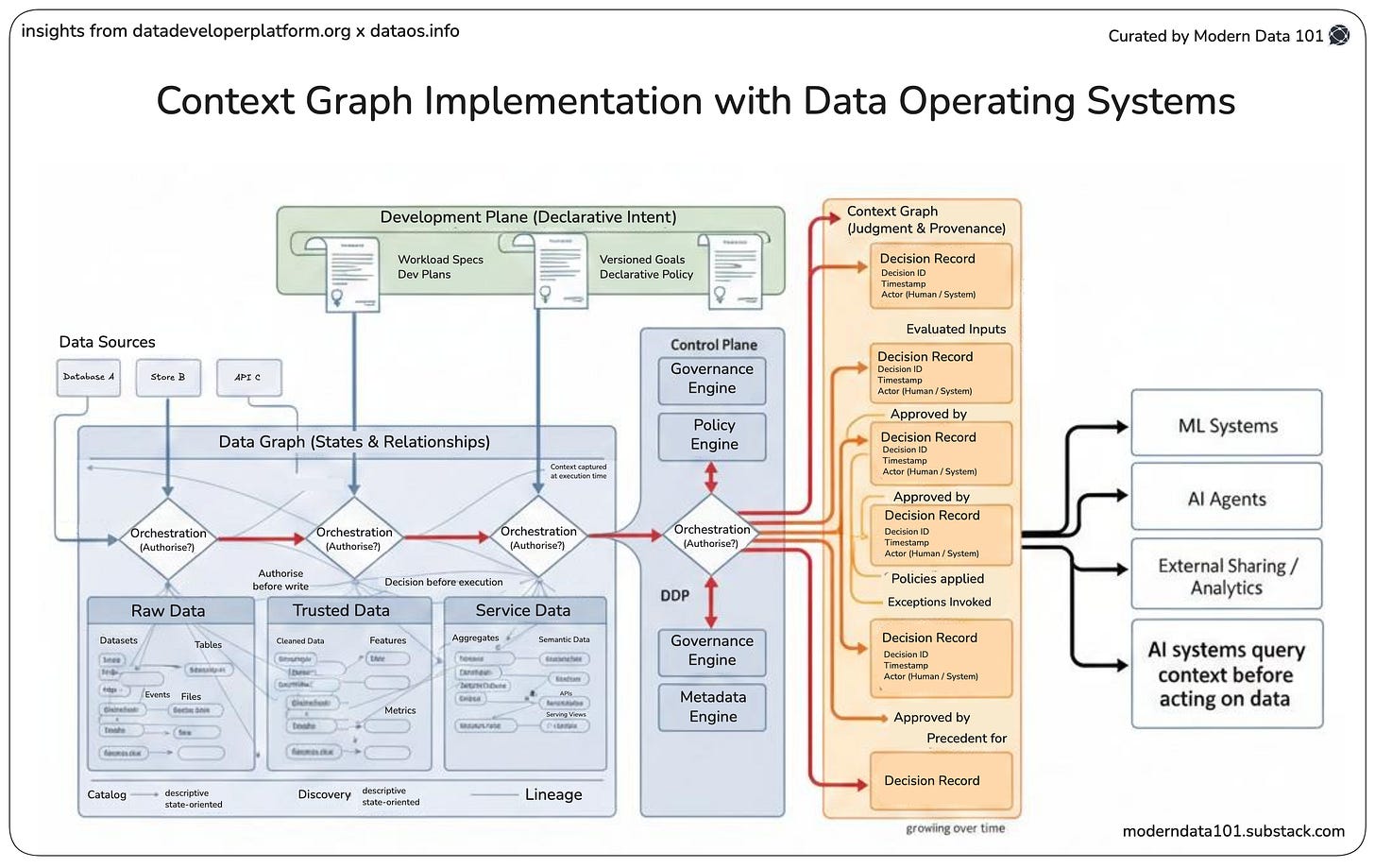
%20(1).png)

.png)
TABLE OF CONTENT


.png)

Your knowledge graph is only as intelligent as the entities inside it. Right now, a significant portion of those entities are duplicates. The same customer, product, or supplier living under three different identifiers, each spawning its own set of downstream decisions, analytics, and errors.
This goes beyond data hygiene and having messy data as a problem; rather, it’s a strategic liability that erodes the business. And instead of fixing the root cause, most teams resort to patchwork fixes, cleaning data in fragments rather than addressing it in the system design itself.
Entity resolution: identifying when two or more records refer to the same real-world entity is foundational to any serious knowledge graph initiative. Get it wrong and every downstream use case, from graph-based recommendations to supply chain intelligence, inherits the same structural flaw.
The earlier Master Data Management designs were built for relational databases in mind and not graph-native architectures. They rely on deterministic matching rules, manual stewardship workflows, and fixed schemas. None of those assumptions holds when you are building a graph across millions of entities, hundreds of data sources, and continuously ingested signals.
[related-1]
Beyond volume, the core challenge lies in data variety. In a knowledge graph, a single entity often originates from disparate sources such as CRMs, procurement systems, web scrapes, and internal documents, each bringing its own complications:
Traditional rules-based matching fails to scale when a graph crosses organisational boundaries or integrates third-party data.
The primary risk in these legacy methods is how they handle errors: Unlike systems that flag errors for review, these legacy methods often fail, allowing the graph to absorb every undetected duplicate as ground truth. Additionally, this lack of flexibility results in a corrupted data foundation that cannot support the dynamic, interconnected nature of graph-native architectures.
[data-expert]
Before selecting any tooling or strategy, decompose the problem into its fundamental units.
An entity is a real-world object with identity. Two records resolve to the same entity when they share sufficient evidence across one or more dimensions: string similarity, relational proximity, contextual embedding, or behavioural signal. The resolution architecture must handle three distinct layers: blocking, which reduces the comparison space; scoring, which applies similarity measures to generate match confidence; and clustering, which resolves scored pairs into canonical entity representations within the graph.

Each layer introduces its own failure modes. Poor blocking creates false negatives at scale. Weak scoring produces noisy match candidates. Bad clustering produces fragmented or overmerged nodes that corrupt the graph structure.
[related-2]
The transition from rule-based to native AI entity resolution is less of a step-by-step transition and more of a transition from an architectural point of view. An AI-native data platform treats resolution as a learning problem rather than a configuration problem. Instead of manually authoring match rules, the system learns entity signatures from labelled examples, adapts to new data patterns, and improves confidence over time.
Large language models and embedding models have fundamentally changed the blocking and scoring layers. Dense vector representations allow the system to match entities based on semantic similarity rather than string overlap, capturing cases such as "IBM Corp," "International Business Machines," and "IBM Corporation" without a single explicit rule. This is valuable in knowledge graph construction, where entity names originate from sources with no standardised taxonomy.
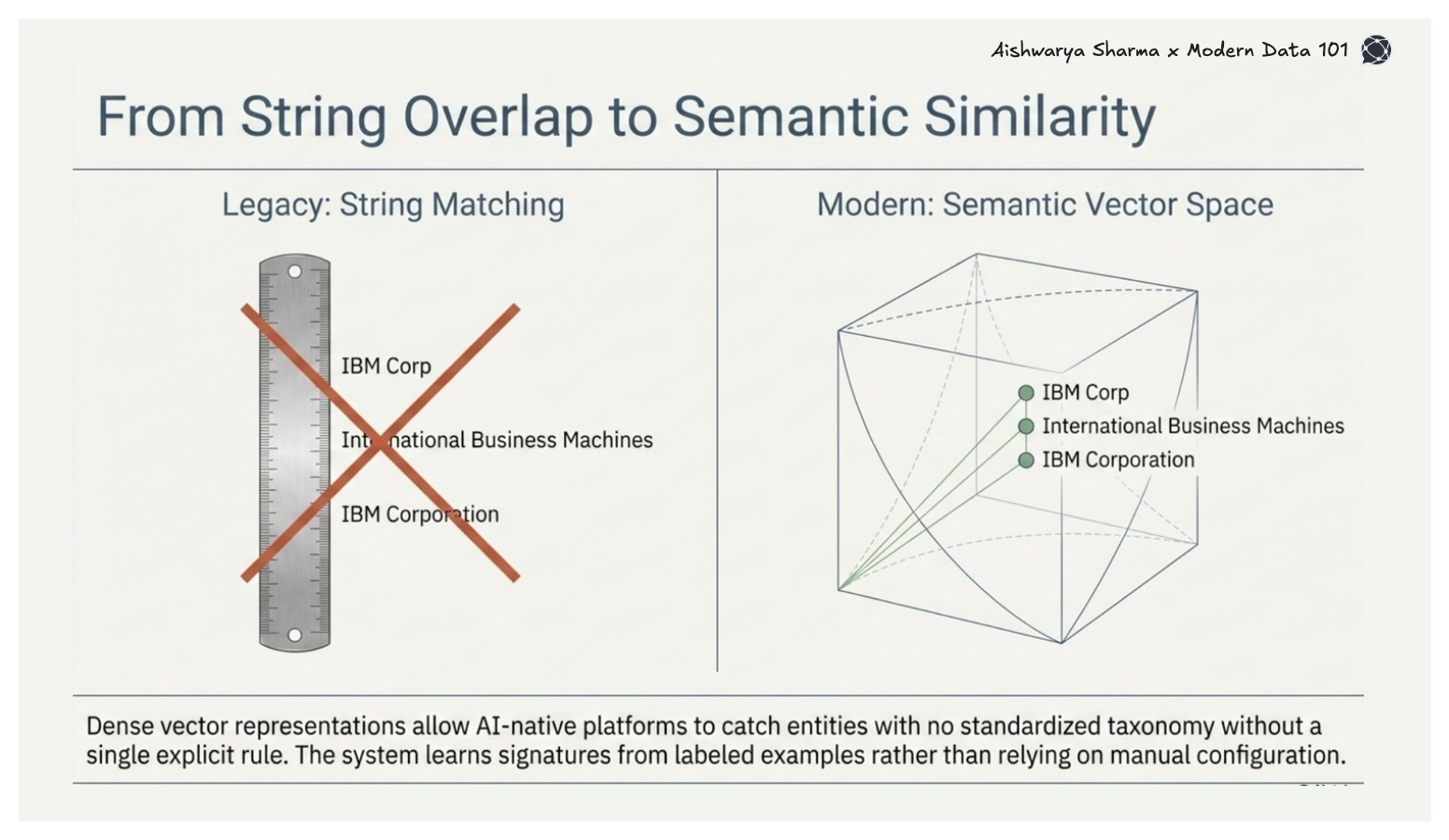
[related-3]
There are certainly no uniform approaches that can be used when building graphs. But there is a class of these that often performs quite well on a large scale:
Approximate nearest neighbour search combined with embedding-based blocking reduces the pairwise comparison problem. Rather than comparing every record to every other record, which scales quadratically, you project entities into a vector space and retrieve candidates within a similarity threshold. Multiple libraries make this tractable at a billion-record scale.
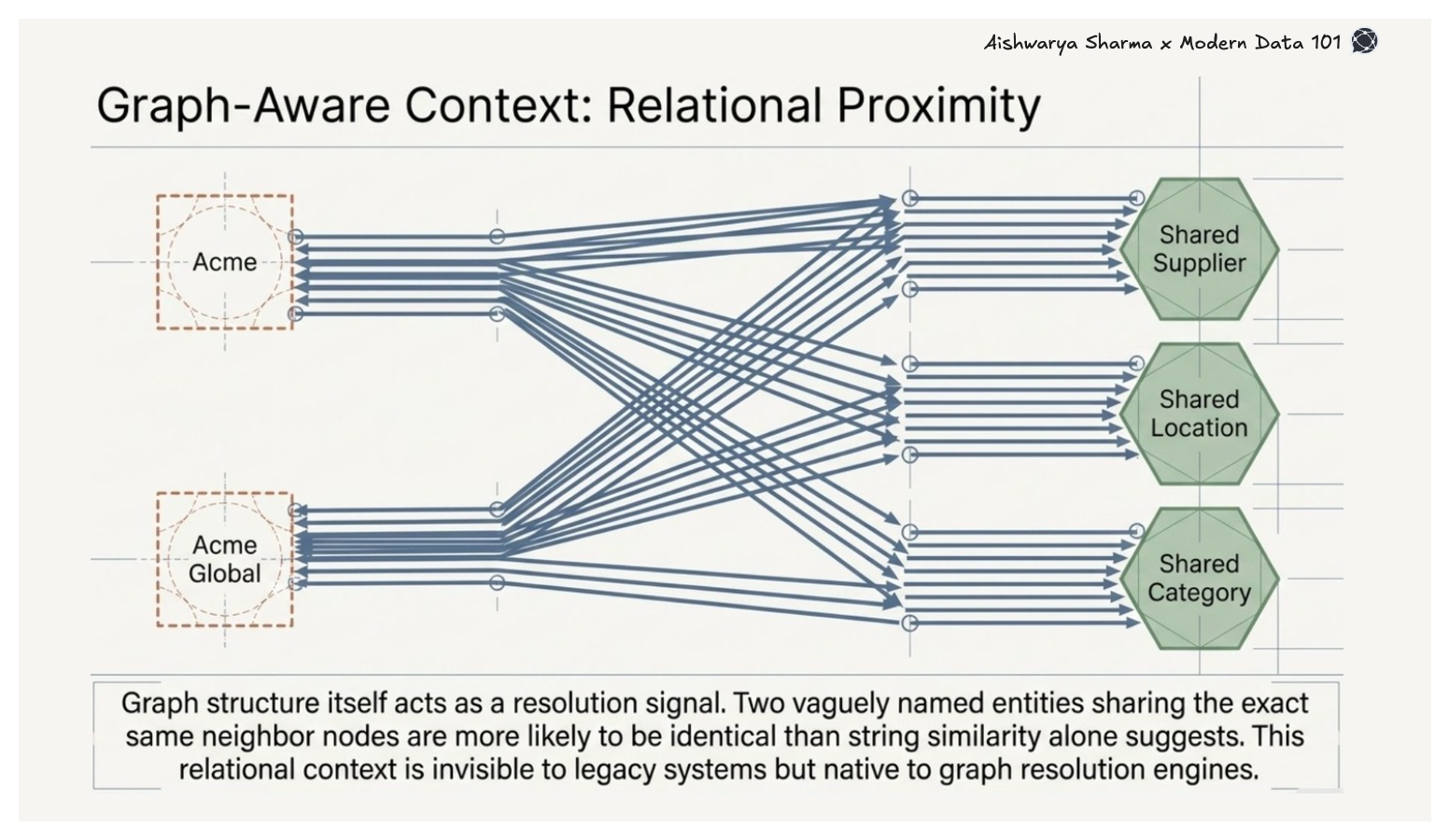
Graph-aware resolution goes further by using the graph structure itself as a resolution signal. Two entities sharing the same neighbour nodes, the same supplier, location, or product category, are more likely to represent the same real-world entity than string similarity alone would suggest. This relational context is invisible to traditional deduplication systems but native to any graph-based resolution engine.
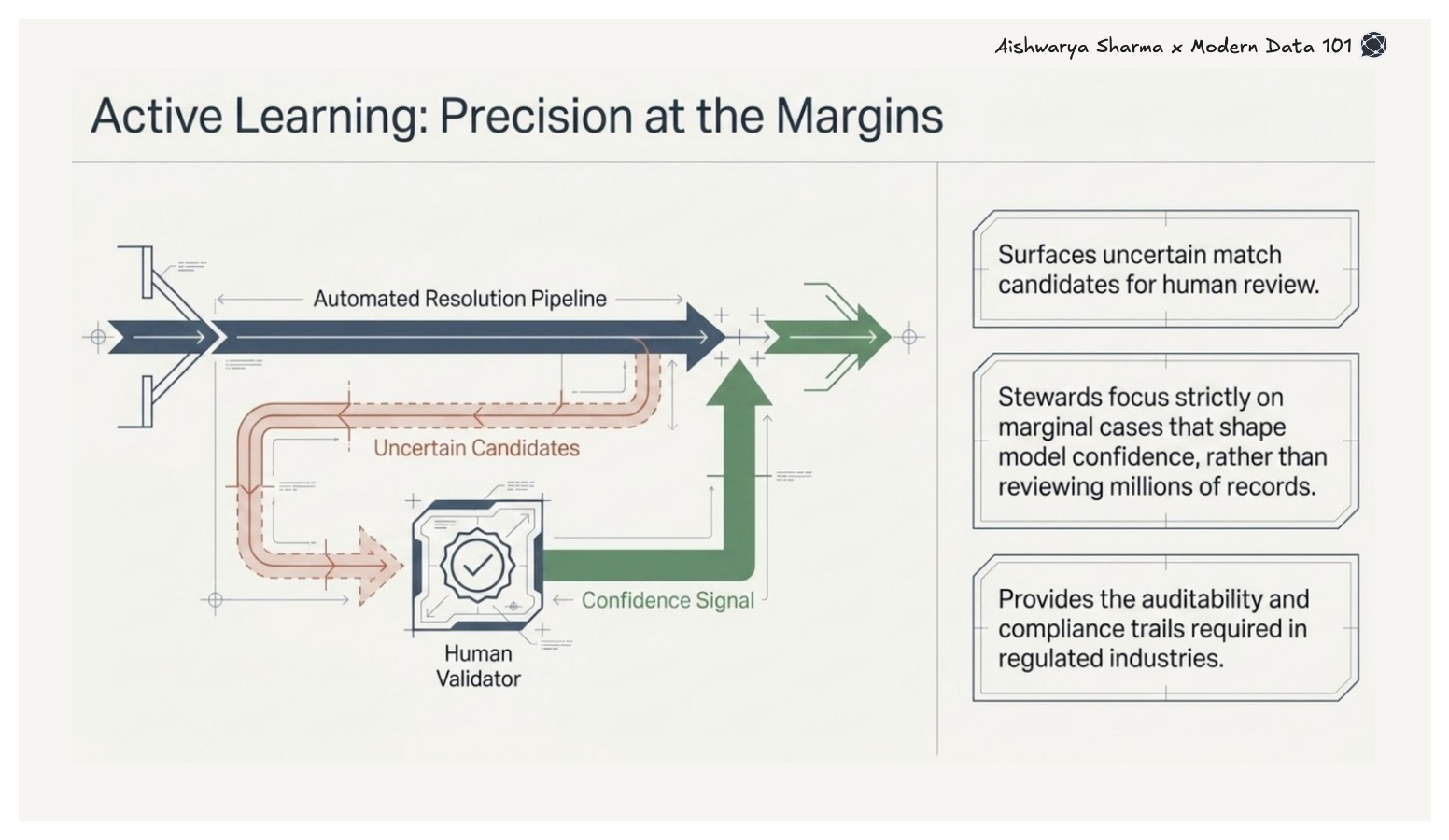
Active learning loops surface uncertain match candidates for human review, prioritising cases where expert judgment adds the most value. Rather than reviewing millions of records, stewards focus on the marginal cases that shape model confidence, a critical capability for regulated industries where resolution decisions carry audit and compliance implications.
[state-of-data-products]
The most common organisational mistake is treating entity resolution as a preprocessing step that happens once before the graph is populated. In modern enterprise environments, this traditional model fails to keep pace with realistic data velocity, creating a "data gap" between where information resides and where AI models need it.
To resolve this, the pipeline must be embedded within graph construction itself. This architectural ideal requires streaming resolution that evaluates incoming entities against existing graph nodes in real time, incremental clustering to update canonical representations without full graph reprocessing, and lineage tracking that preserves the source records behind each resolution decision.
An AI-native data platform that integrates natively with the graph layer allows resolution confidence scores to propagate as queryable graph attributes, ensuring the graph remains a high-precision foundation rather than a corrupted data set.
This move toward operationalised resolution is a strategic imperative; according to the IBM Institute for Business Value, organisations that deploy AI at an operational level, integrating it directly into core business processes, outperform competitors 44% more frequently than peers focused primarily on skills-based adaptation, across areas such as revenue growth and employee retention. Ultimately, continuous, AI-native entity resolution is a foundational revenue and risk decision, serving as the true engine of the knowledge graph.
[related-4]
Every duplicate entity in your knowledge graph represents a decision made with incomplete information. A customer split across three identifiers means your 360-degree view is actually three 120-degree views. A supplier duplicated in your system means your risk exposure model is wrong.
The organisations closing the gap between data investment and business outcomes are not doing so by acquiring more data. They are doing so by resolving the data they already have with greater precision. Entity resolution at scale, powered by an AI-native data platform, is the architectural capability that makes that possible.
Entity resolution identifies and merges duplicate records that refer to the same real-world entity, like a customer or product. This process ensures data accuracy and consistency, which is critical for building reliable knowledge graphs and making informed business decisions.
AI-native data platforms are designed specifically to support machine learning and artificial intelligence at scale. They automate tasks like entity resolution and deduplication, allowing organisations to manage complex, high-volume data more efficiently.
Knowledge graph-based retrieval enhances search by using relationships between entities to provide context-rich, relevant results. This approach enables smarter, semantic data discovery compared to traditional keyword searches.
Common data deduplication strategies include exact match, fuzzy matching, and advanced AI-driven techniques like embedding-based and graph-aware resolution. These help maintain data quality by identifying and removing duplicates across systems.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



