


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)

.png)
TABLE OF CONTENT



In 2026, unified data platforms are the foundation for reliable AI, lower costs, stronger governance, and faster decision-making.
Think of a unified data platform as a single source of truth that eliminates “swivel chair” work across disconnected tools. Instead of dealing with fragmented pipelines and messy ETL, teams get what they need in one self-serve environment. By breaking down silos, everyone works from the same definitions, avoiding conflicting answers to basic questions.
Fragmented stacks create drift, waste, and delays, where unified platforms deliver consistency, efficiency, and trust.
This is what enables unified data platforms to act as the foundation for building scalable data products.
The real value is a governance-first approach where security and data quality are built in, so every AI model runs on consistent, reliable logic, not just lower costs.
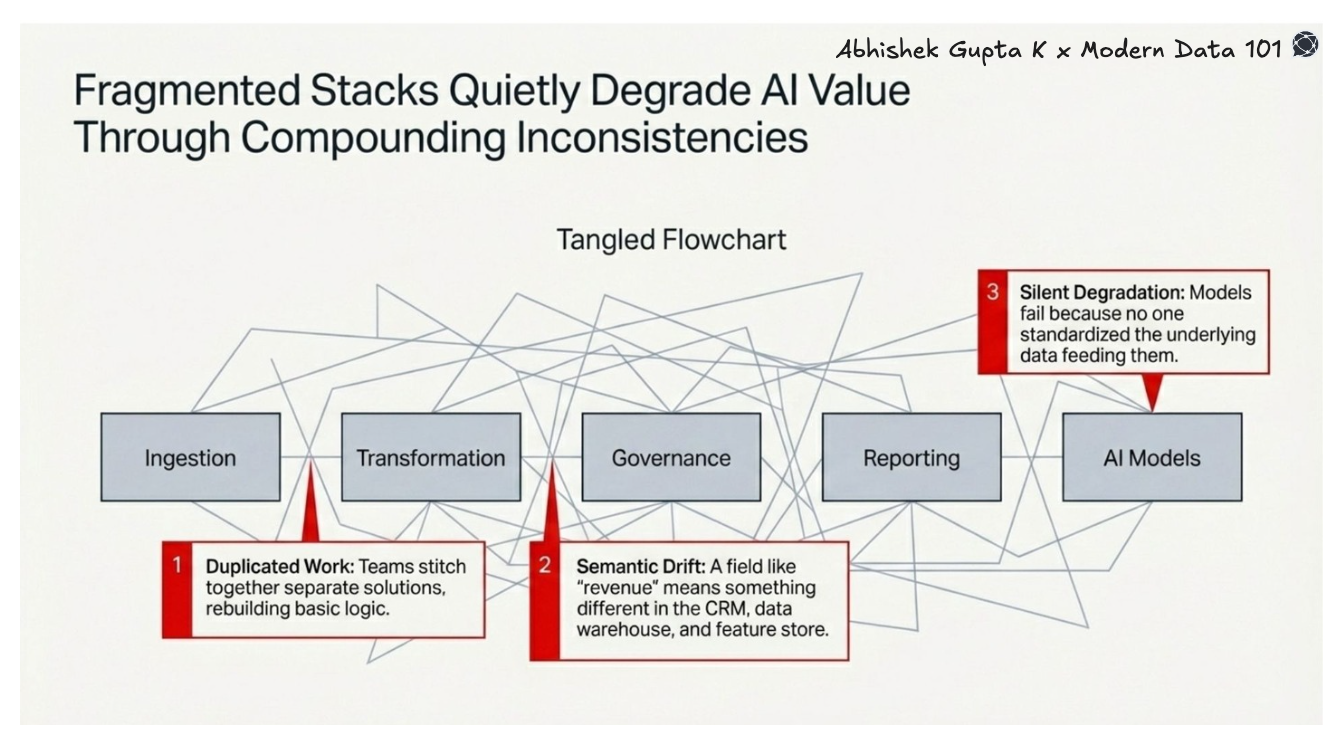
The issue isn’t a lack of tools, but it’s that the existing ones don’t connect. Their systems for ingestion, cleaning, and reporting don’t talk to each other, creating a heavy coordination burden that slows everything down and keeps AI projects from ever reaching production. Without consistent, standardised data, models end up running on conflicting logic, leading to silent failures that go unnoticed. A unified data platform cuts through this mess, giving teams a single, governed foundation that’s no longer optional if they want to scale AI.
[related-1]
Here are the six benefits that matter most, and why they go well beyond what most articles in this space actually discuss:

The most visible benefit (and also the most fundamental) of a unified data platform is its capability to eliminate the fragmented, siloed data landscape that causes inconsistency across teams and systems.
When data travels across five different systems before reaching a model or dashboard, it loses coherence. A field called revenue means something slightly different in your CRM, your data warehouse, your feature store, and your reporting layer. These differences compound silently.
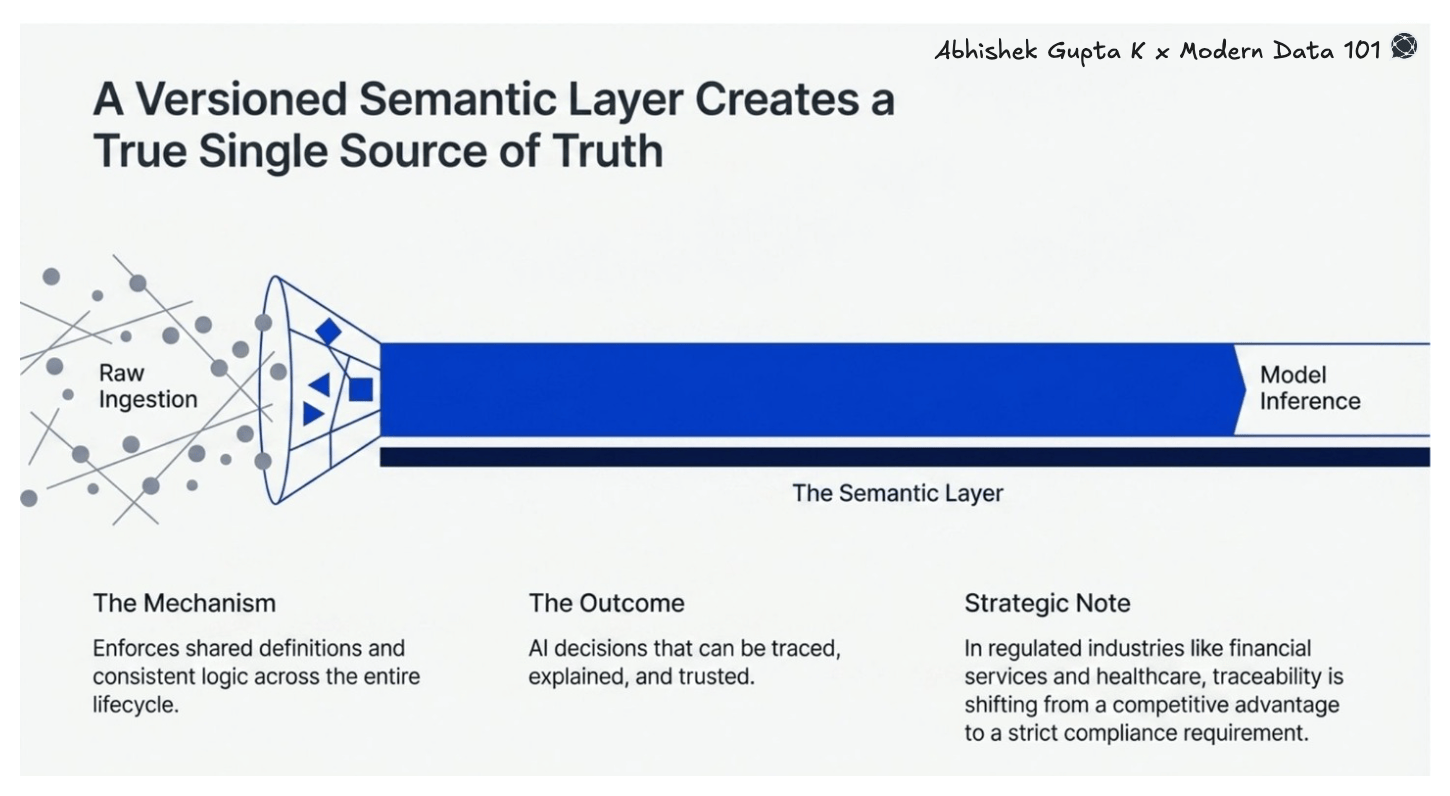
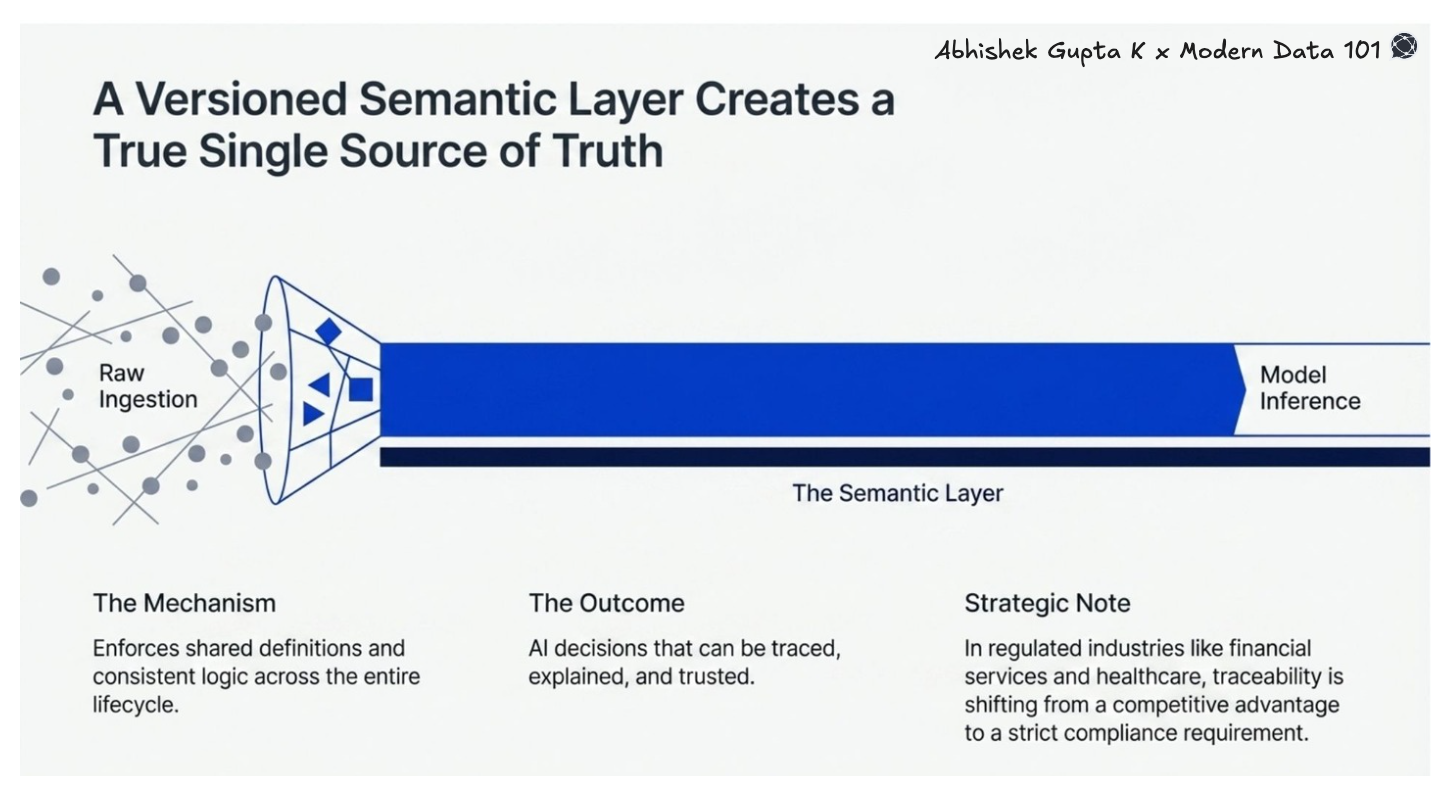
A unified data platform enforces a single, versioned semantic layer that travels with data across its entire lifecycle, from raw ingestion to model inference. The result is a true single source of truth: shared definitions, consistent logic, and AI decisions that can be traced, explained, and trusted. In regulated industries like financial services and healthcare, this traceability is quickly moving from a competitive advantage to a compliance requirement.
[data-expert]
When an analyst waits two days for an engineer to update a transformation, or a data scientist rebuilds a business metric because they cannot locate the canonical definition, those costs do not appear in a budget line. They appear in slower product iterations, delayed decisions, and the kind of quiet frustration that eventually becomes attrition.
But a unified data platform, along with consolidating tools, also consolidates ownership. Most total cost of ownership analyses of fragmented data stacks count the obvious costs: licensing fees, infrastructure spend, and headcount. What they consistently miss is the coordination overhead across pipelines, a problem typically addressed through DataOps practices.
This leads to analysts, engineers, and data scientists operating inside the same semantic layer with shared definitions and shared context. The coordination tax drops sharply. Decisions that once required three meetings and a Slack thread can be validated in minutes. For a team of twenty, the time savings alone regularly amount to several engineer-weeks per quarter, and that is before accounting for the reduction in rework.
[related-2]
Data governance in 2026 is moving beyond access control and schema documentation. Regulators, particularly under frameworks like GDPR, the EU AI Act, and emerging US data accountability legislation, are asking harder questions: What data was used to make this decision? What was its state at the time? Can you reproduce the output?
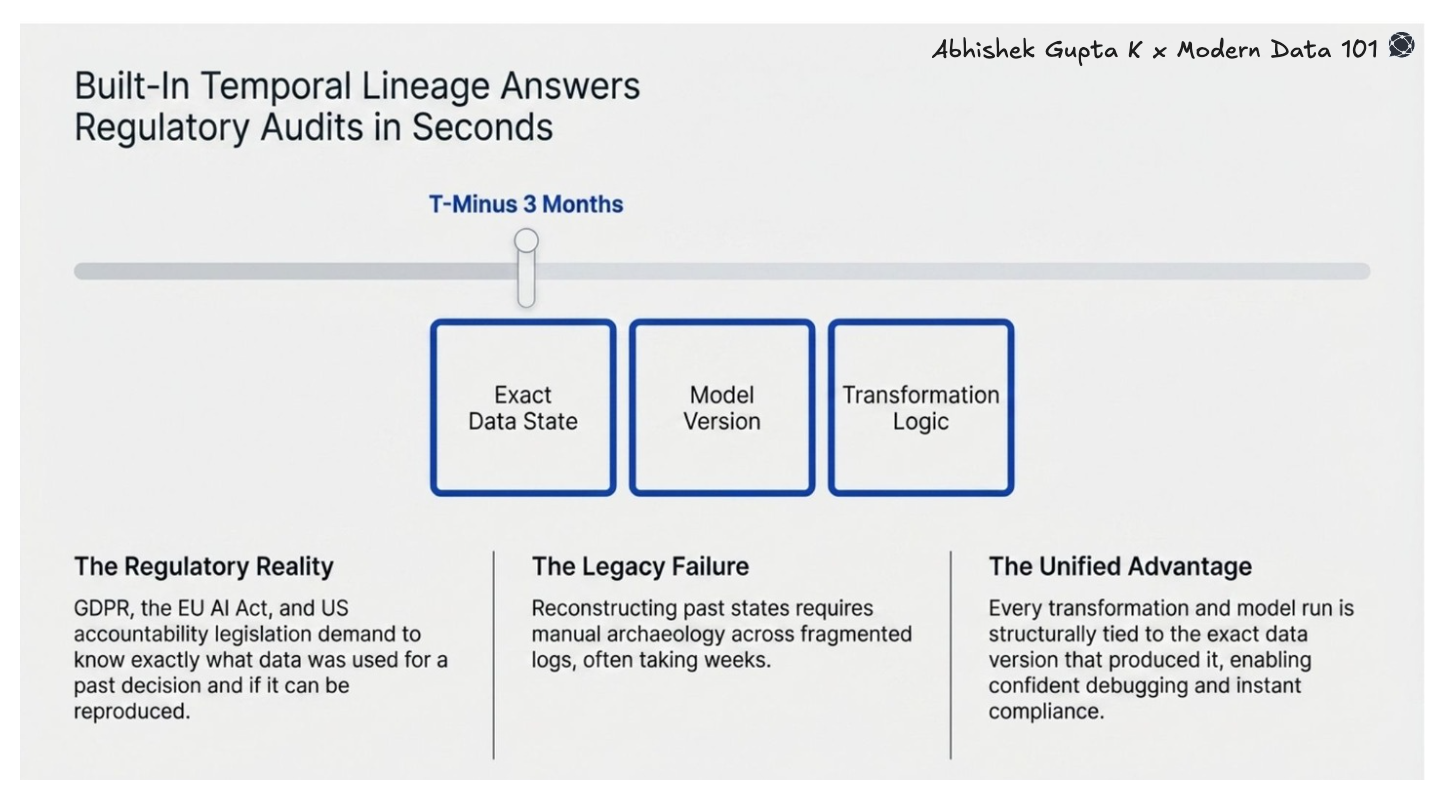
Point-solution stacks are structurally bad at answering these questions. Logs exist, but they are fragmented across systems. Reconstructing the exact data state at a specific timestamp often requires manual archaeology that takes weeks, and compliance timelines rarely allow for that.
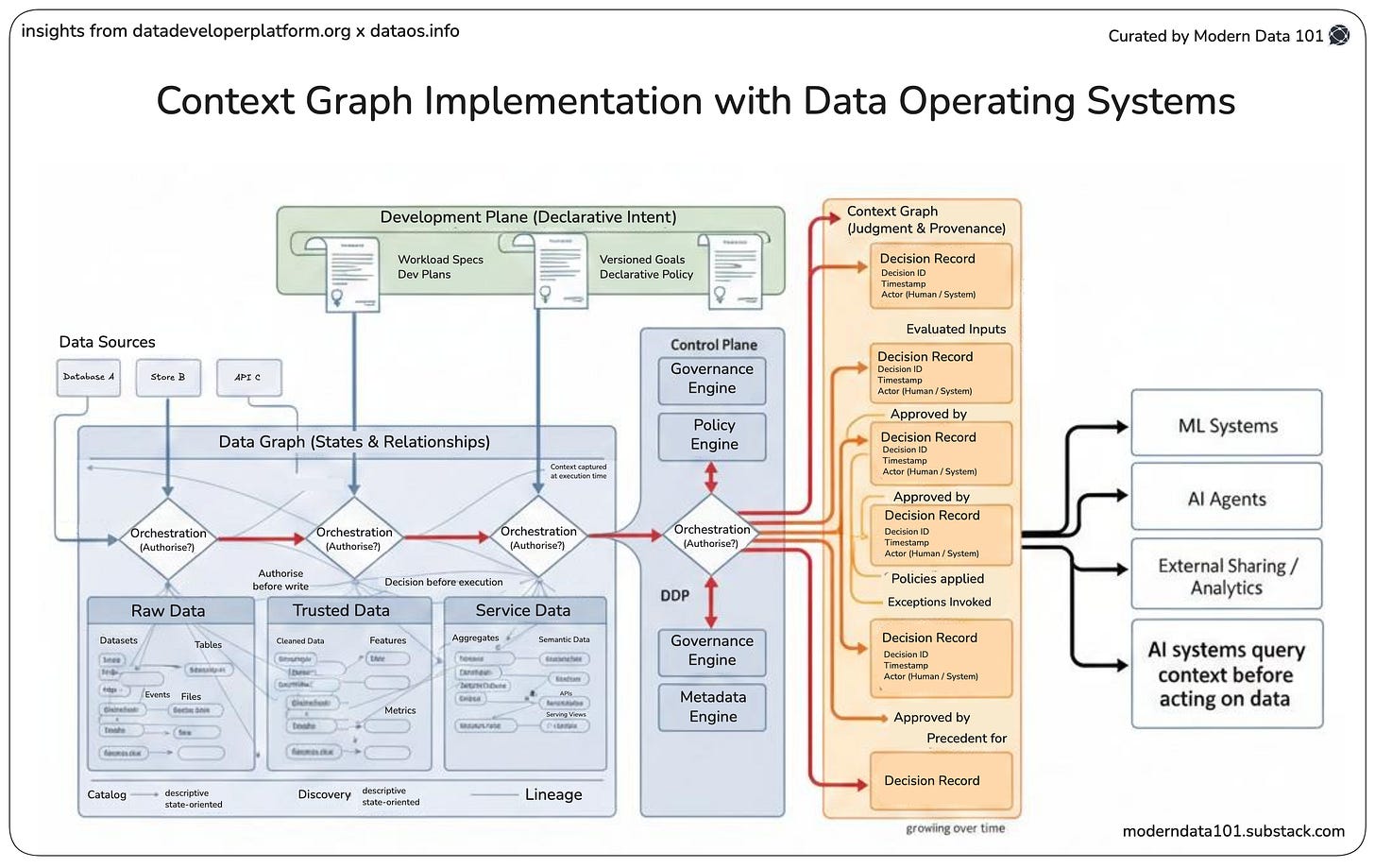
Unified data platforms built with temporal lineage as a core primitive can answer these questions in seconds. Every transformation, every model run, every report is tied to the exact data version that produced it. This also enables confident debugging, faster incident resolution, and governance that is built in rather than bolted on.
[playbook]
Legacy data architectures were designed around the assumption that you do not know when you will need data, so you keep everything running all the time. The result is substantial infrastructure spend on idle compute.

However, modern unified data platforms support intelligent scheduling tied to actual demand signals: downstream dependencies, business calendars, and real access patterns. Rather than running everything on a fixed cadence, compute scales up when needed and down when it is not.
In parallel, organisations that consolidate fragmented data and infrastructure layers into unified platforms often report significant cost savings, frequently in the range of [30–40%], driven by reduced duplication, shared infrastructure, and more efficient resource utilisation.
This way, the savings are real, the environmental impact is lower, and resource allocation becomes legible. You can see exactly what is being consumed, by whom, and why.
The enterprise AI stack in 2026 is rarely a single model. Most mature organisations are running a portfolio: forecasting models, recommendation engines, NLP pipelines, LLM-assisted workflows, sometimes dozens of models in production simultaneously, often drawing from the same underlying data.
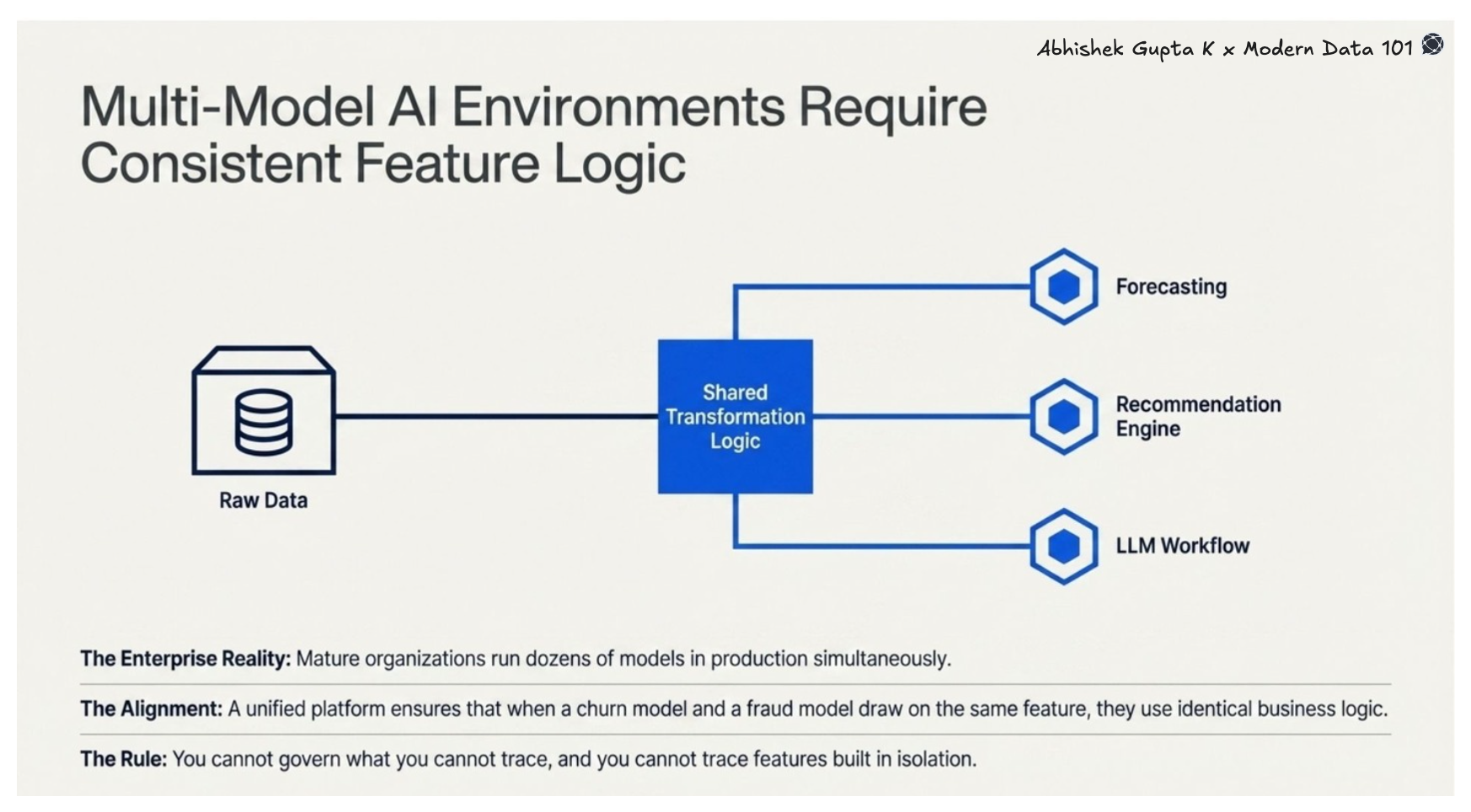
Without a unified data platform, the same raw data produces different features across teams- not because the business logic differs, but because each pipeline encodes its own assumptions, often without visibility or alignment.
A unified data platform enforces shared transformation logic across all models. When the churn model and the fraud model both draw on the same feature, they draw on the same version, with identical business logic applied consistently. This is the foundation of model governance: you cannot govern what you cannot trace, and you cannot trace features that were built in isolation across a fragmented data stack.
[related-3]
Traditional data monitoring tells you when a pipeline fails,, or a schema changes, but not whether those failures actually mattered or whether leadership dashboards are quietly showing stale or misleading data. Now, this gap is critical: as AI-driven insights shape decisions, silent data quality failures, issues that don’t trigger alerts but produce wrong outputs carry real risk.
Unified data platforms close this gap by linking technical signals to business outcomes. A drop in data freshness is surfaced in terms of affected reports, decisions, and downstream risk, enabling teams to move from reactive firefighting to proactive governance and prioritise fixes based on real business impact.
The conversation around unified data platforms has historically been framed around convenience: fewer tools, less context-switching, simpler vendor relationships. In 2026, the frame has shifted to something more fundamental.
Organisations winning with data are not winning because they have more of it, or faster pipelines, or better models in isolation. They are winning because their enterprise data stack is coherent: shared definitions, traceable lineage, consistent features, observable outcomes, and a unified analytics experience that provides analysts, engineers, and business leaders with a single source of truth.
[related-4]
Breaking down data silos was always the goal. But this year, a unified data platform is the most direct and proven path to getting there, among other things.
A unified data platform integrates five core layers: ingestion for batch or streaming data, storage for scalable processing, and transformation for harmonising assets. It also incorporates metadata for governance and AI workspaces for model management, reducing duplicated work to accelerate AI deployment.
Organisations switch because 85% of AI projects fail on legacy ETL stacks lacking consistency. Modern unified platforms replace this fragmentation with a single governed foundation, allowing human and machine intelligence to function seamlessly at scale instead of stalling in development pilots.
Platforms ensure safety by shifting data classification left, labeling information at collection to embed governance early. They use RBAC and ABAC for consistent access control while applying Zero Trust principles to continuously verify the behaviour of all users and autonomous agents.
An AI-ready foundation requires balancing strategy, technology, talent, and data. Organisations must prioritise high-impact use cases, select modular platforms to reduce technical debt, and upskill their workforce to ensure data is representative and accurate across all AI inputs.
Zero Trust for AI applies security principles across the entire lifecycle, from ingestion to agent behaviour. It focuses on verifying explicitly, applying least privilege to restrict model access, and assuming breach resilience against threats like prompt injection and data poisoning.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



