



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...




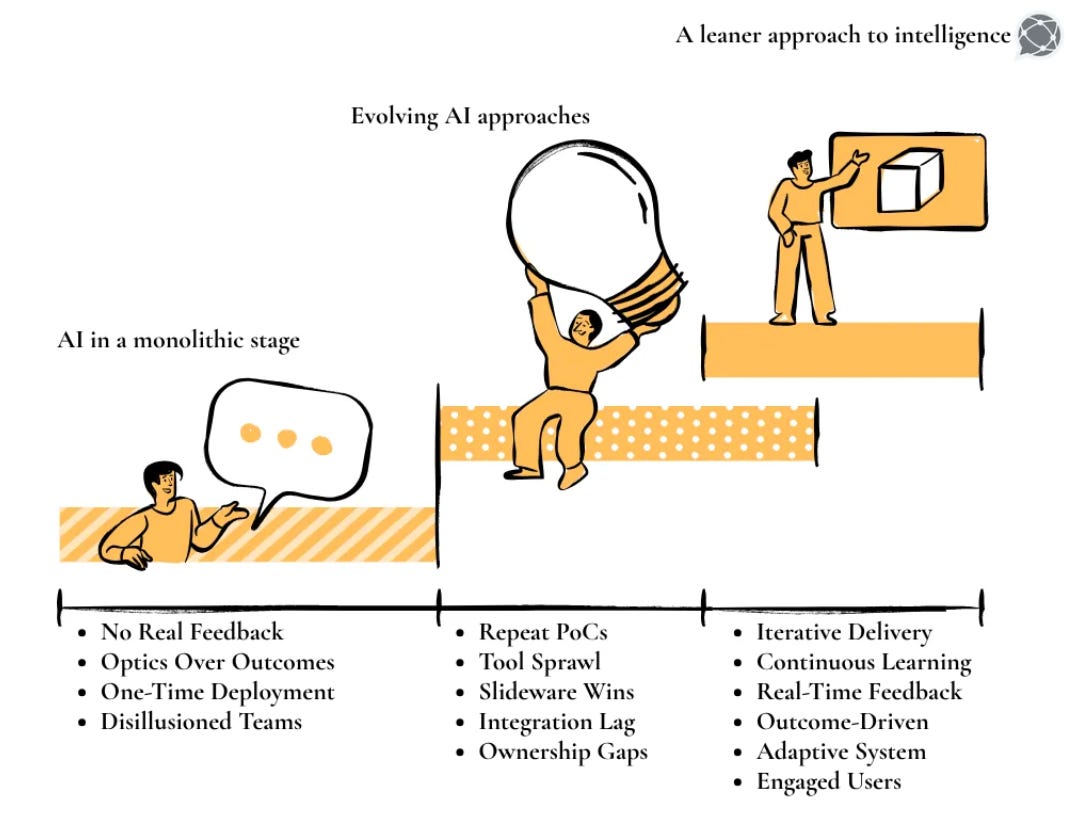

TABLE OF CONTENT


.png)

Mature organisations run data warehouses, lakes, streaming pipelines, and feature stores in parallel, with significant investment in data quality, cataloguing, and observability. On paper, they are data-ready.
According to McKinsey, only about one-third of organisations have scaled AI from pilot to production, highlighting a clear gap: strong data foundations are not translating into reliable AI outcomes.

The reason is structural. Data infrastructure ensures accuracy, consistency, and freshness, but AI introduces decision-making, which traditional data quality frameworks are not designed to validate.
This gap exists because:
[related-1]
AI observability is the ability to monitor, understand, and explain how AI systems behave in production.
While data observability focuses on the health of pipelines, including freshness, schema, and completeness, AI observability focuses on outcomes. It tracks how models perform, how inputs are interpreted, and how decisions evolve.
This includes signals such as model performance and drift, input and feature distribution changes, output quality, bias, and anomalies and real-world feedback loops.
Therefore, enterprises need AI observability to address the gap between data quality and decisions, or precisely the capability of turning data into decisions with AI models.
[playbook]
Data observability validates whether the data is correct, and not whether decisions made from it are correct. A perfectly healthy pipeline can feed a drifting, biased, or misaligned model, and traditional monitoring won't catch it.
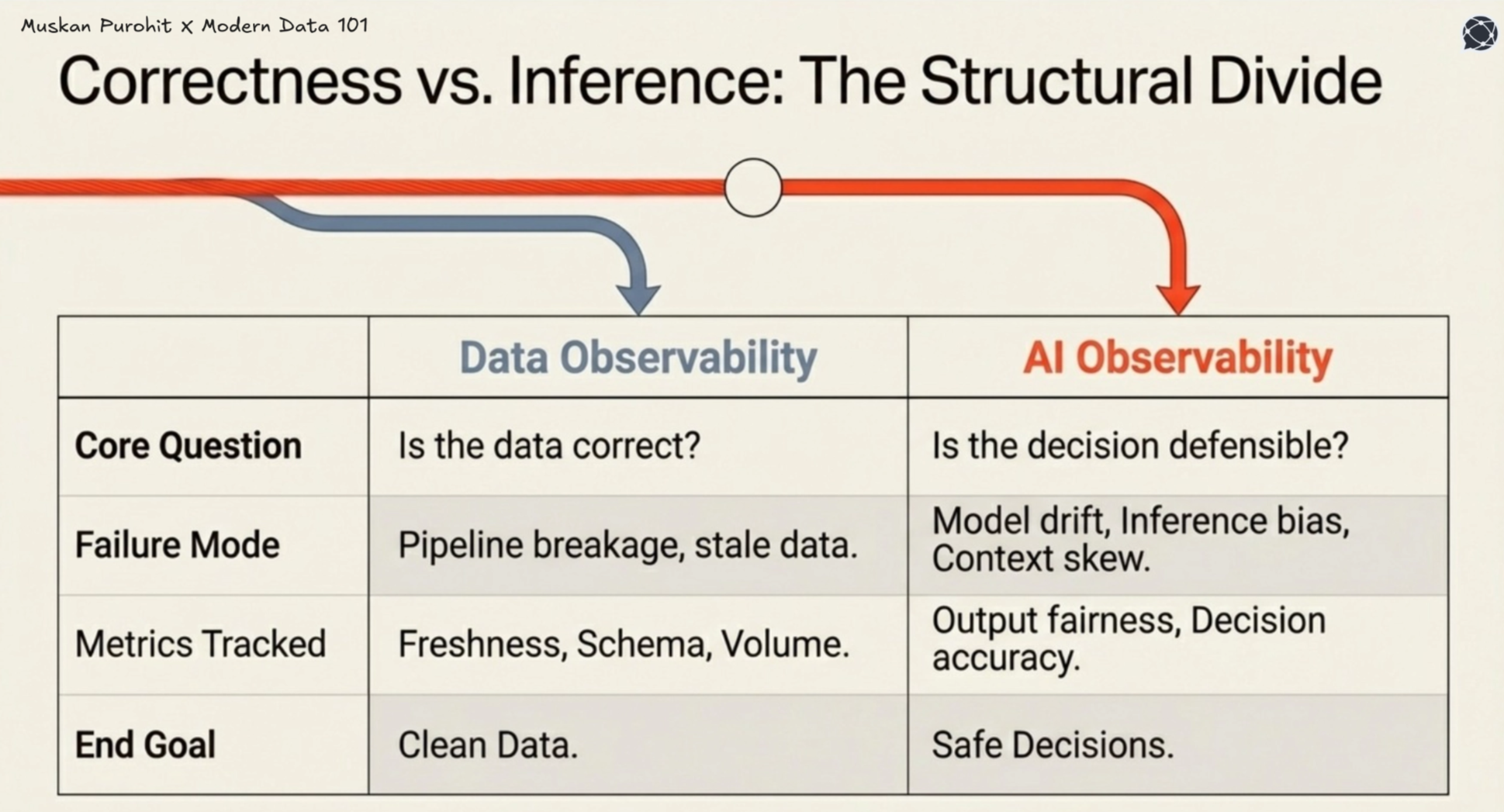
The assumption that this same layer can guarantee AI reliability is where the problem begins.
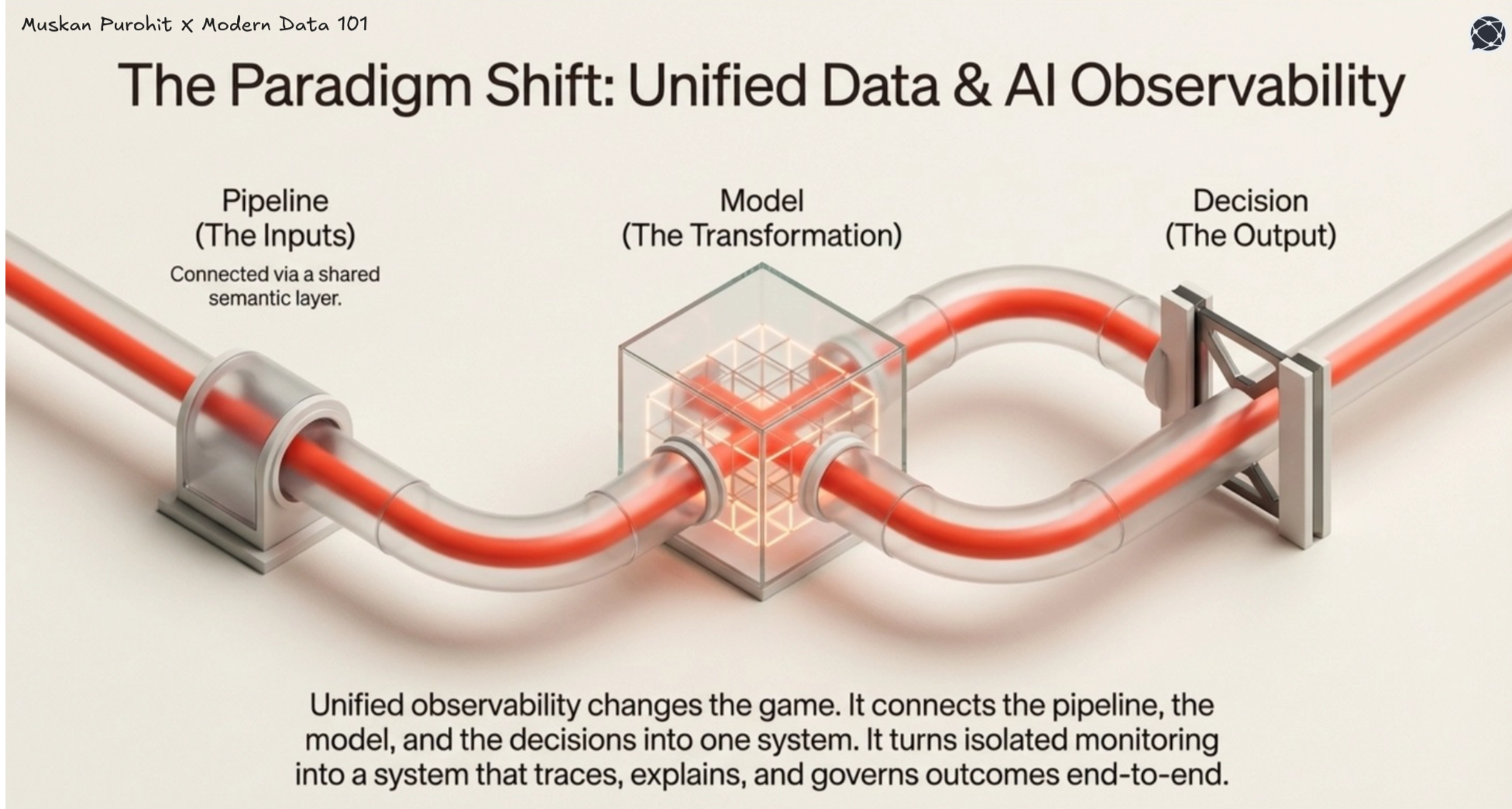
AI observability detects that a model is failing, but without upstream data context, it can't explain why. Unified data and AI observability closes this gap by connecting data, models, and decisions through shared lineage, turning isolated monitoring into a system that can trace, explain, and govern outcomes end to end.
[related-2]
AI observability often doesn’t scale on a single capability but needs a set of coordinated strategies to ensure decisions remain reliable, explainable, and controllable in production.
The most effective strategies share a common shift from monitoring components to understanding decisions as system outcomes. How should the strategies look for AI observability?
These structural challenges present the best case for data platforms to eliminate fragmented observability where signals cannot be unified into decision-level intelligence.
Most unified data platform strategies focus on workload consolidation: bringing analytics, data engineering, and ML onto a single platform to reduce duplication and simplify operations. While valuable, this is insufficient for AI at scale.
AI introduces requirements that traditional platforms were not designed to meet:
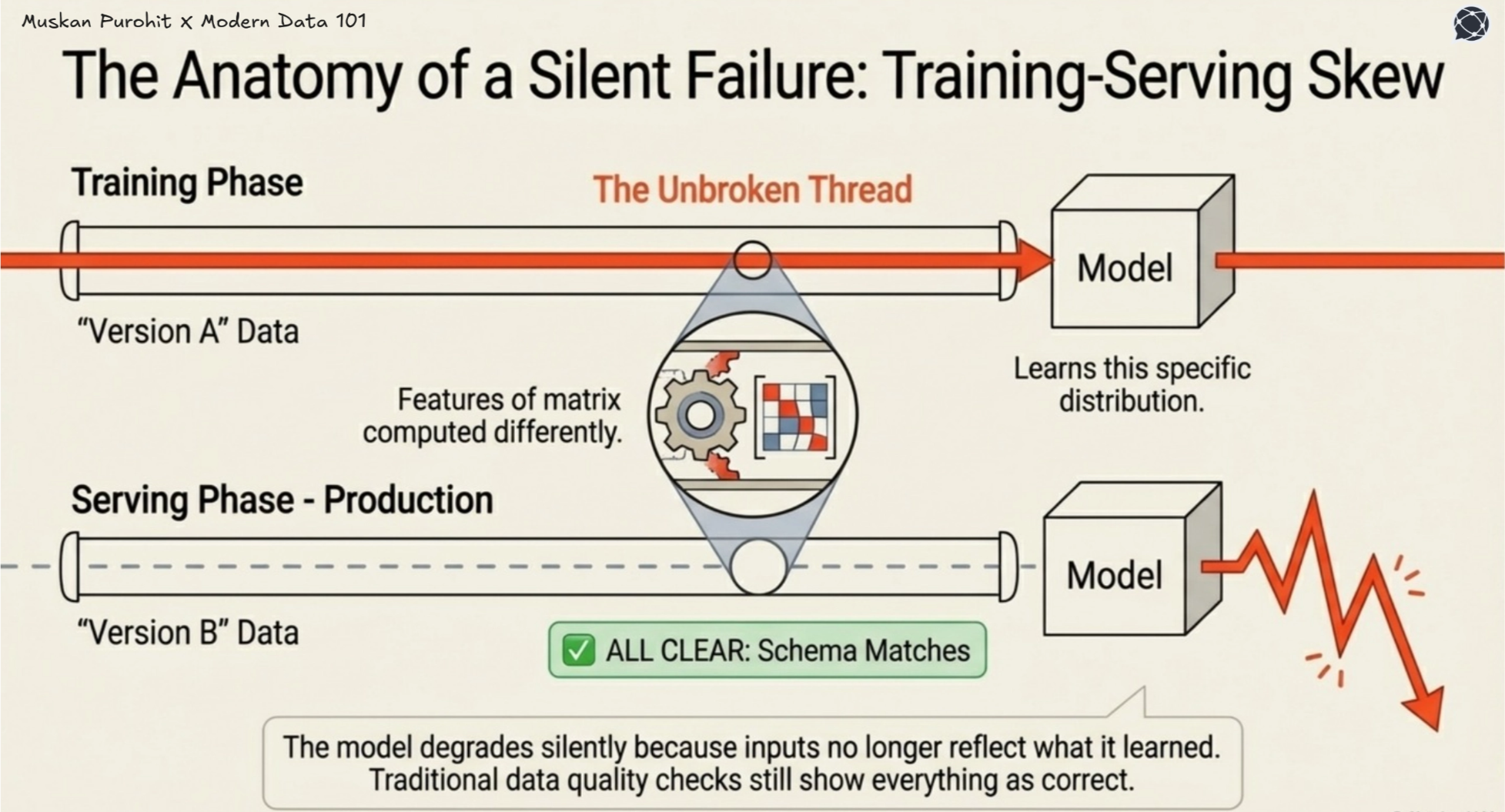
AI models rely on features computed from specific data versions during training. In production, these must match exactly. Even small differences create training-serving skew, where inputs no longer reflect what the model learned, causing silent degradation while data quality checks remain healthy.
As AI scales, the same data feeds multiple models across domains. Without versioned contracts, identical raw data produces inconsistent features, leading to conflicting decisions with no clear way to detect or resolve them.
[related-3]
Enabling end-to-end lineage
Unified platforms turn lineage into a real-time, queryable system, extending from raw data to transformations, features, models, and decisions. This ensures every decision is traceable to the data, logic, and model version behind it, enabling explainability, root cause analysis, and auditability at scale.
[data-expert]
Every AI decision must be tied to the exact data, form, and time it was generated. This goes beyond debugging and is increasingly a regulatory requirement. Lineage must be real-time and linked to each inference to ensure decisions are explainable and auditable.
Unified platforms standardise ownership while keeping data with domain teams. Shared definitions, contracts, and lineage ensure data remains consistent, traceable, and usable across models. This is critical as multi-domain inconsistencies can silently impact decisions.
These requirements cannot be solved by adding more monitoring to a fragmented stack. They require the data platform to be redesigned with AI as the primary consumer, not analytics.
[related-4]
Implementing unified observability requires a shift from fragmented monitoring to system-level design. As a result, enterprises need to redefine the scope of the data platform by optimising the data-to-decision lifecycle.
This requires unifying data through not mere consolidation of everything into one store, but creating a consistent layer of context across systems, where data definitions are standardised, transformations are traceable, and the same inputs mean the same thing across models.
[related-5]
Achieving unified observability thus needs end-to-end AI observability and data observability plus unification, in order to deliver reliable AI results.
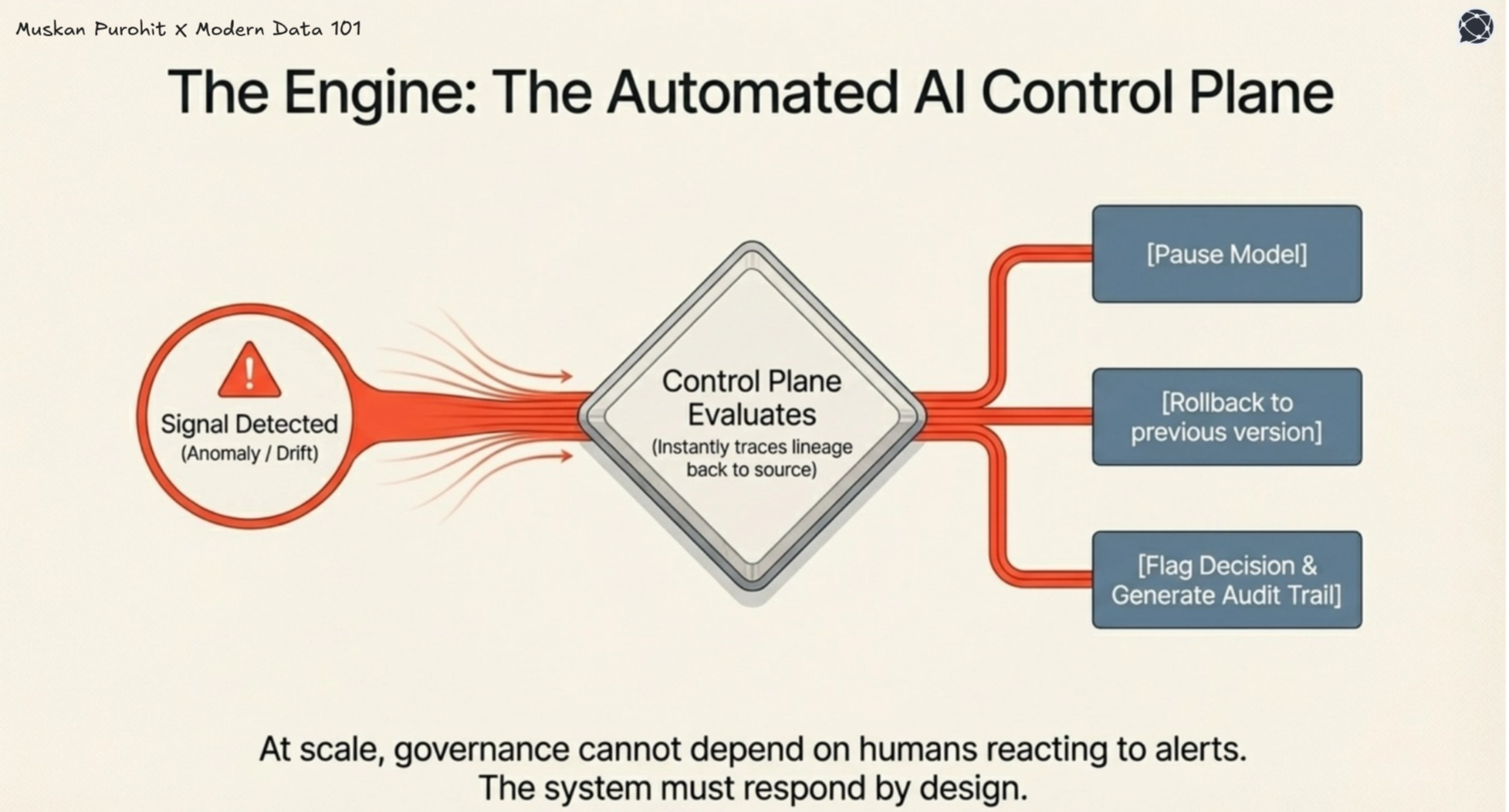
The cost builds quietly as silent decision debt, where decisions are made on drifting data and degrading models, with no system to validate outcomes. Rather than surfacing as alerts, failures crop up later as business anomalies, customer impact, or regulatory risk, making them slow and expensive to trace.
Reports suggest that by 2027, 60% of organisations are expected to fail to realise expected AI value due to weak governance and data issues, highlighting that the problem is not experimentation but the inability to operate AI reliably at scale.
Most organisations underestimate this. The real issue is the inability to operate AI reliably at scale. In regulated environments, the risk is sharper. Without unified observability, there is no end-to-end trace from data to decision, only fragmented logs and manual reconstruction.
The real cost: AI systems that accumulate risk faster than the organisation can detect or control it.
Before investing in unified data and AI observability infrastructure, leadership teams need an honest diagnosis of where current capability actually sits. The following four-stage maturity model maps the most common organisational patterns across enterprises deploying AI on unified data platforms today.
Data pipelines and AI models are monitored separately, with no shared context. Data quality checks exist, but model issues require manual, cross-team debugging.
Teams share alerts across systems, but only at the surface level. There is awareness of dependencies, but no shared lineage or automated root cause analysis.
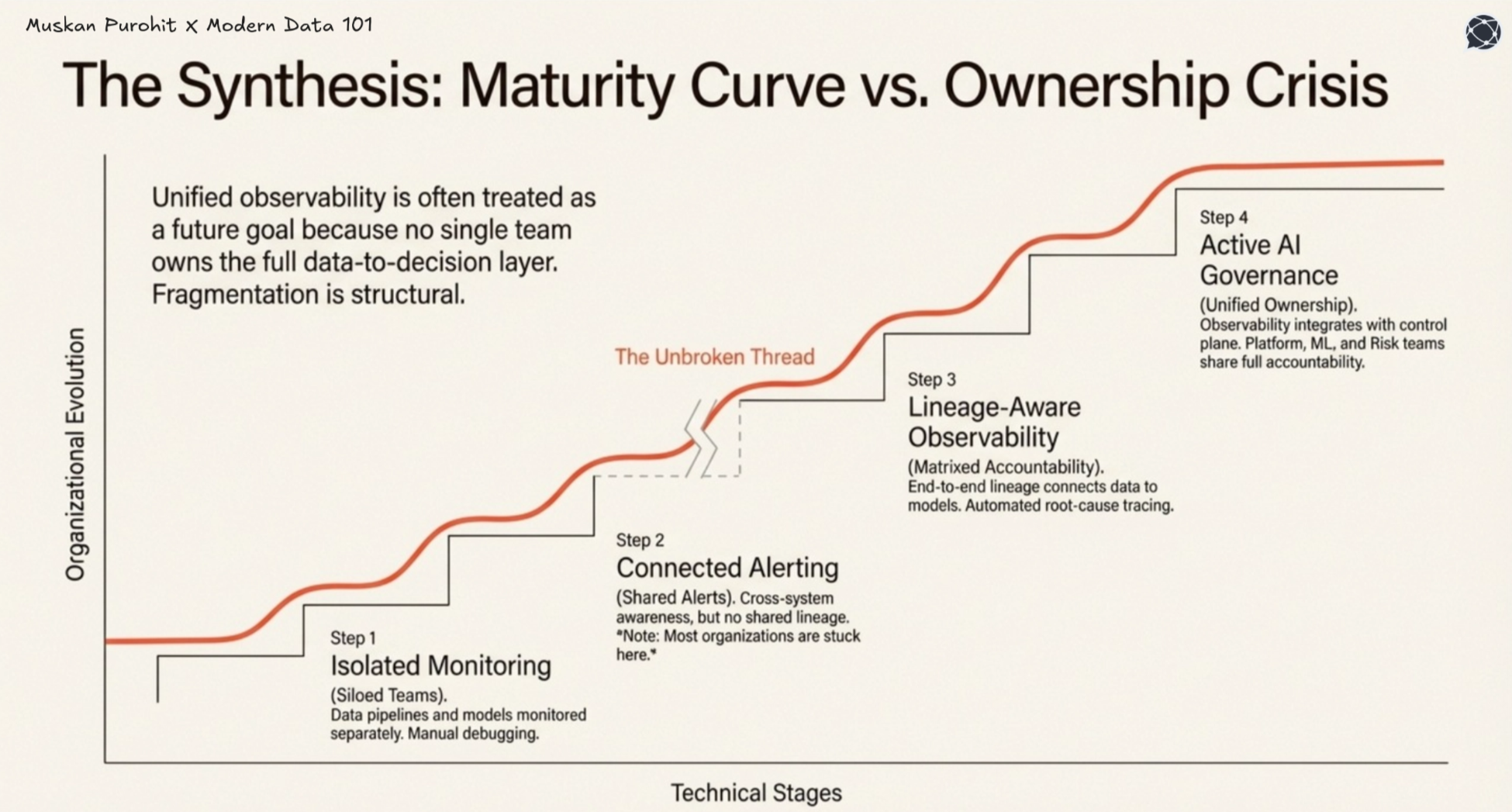
End-to-end lineage connects data to models, enabling automated tracing from model issues back to data causes. This is where decision trust becomes achievable.
Observability integrates with the AI control plane. Issues trigger automated responses such as rollback, containment, and audit logging. Governance becomes built into the system.
Most organisations are stuck between Stage 2 and Stage 3, and closing this gap is what unlocks scalable, trustworthy AI.
In most enterprises, no single team owns unified observability. Data engineers manage pipelines, ML teams monitor models, and risk teams define policy, leaving the data-to-decision layer fragmented. This is structural; AI was introduced incrementally, so ownership remained siloed, and unified observability is often treated as a future goal rather than core infrastructure.
Closing this gap requires a clear ownership shift. Data platform leaders must extend into AI consumption, ML teams must take responsibility for upstream data dependencies, and risk teams need direct access to lineage. Organisations that succeed treat the data-to-decision stack as one system, with shared accountability across teams.
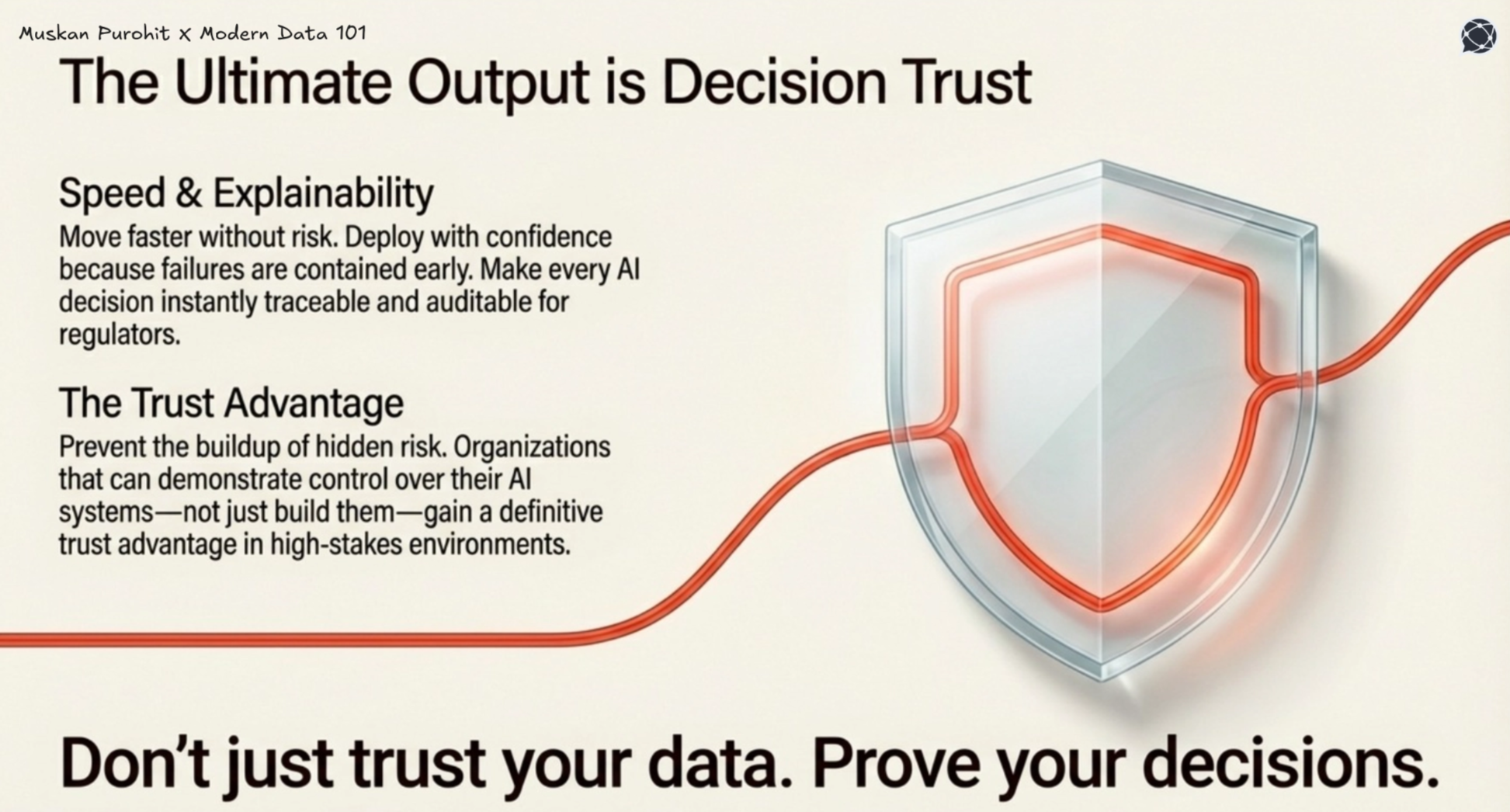
This shift is where unified observability creates real value. With a connected view across data, models, and decisions, teams can deploy faster, detect and contain failures early, and make decisions explainable and auditable by design.
Instead of reacting to business impact, issues are identified earlier, reducing hidden risk and remediation costs. Over time, this builds a trust advantage, where organisations can not only build AI systems, but also operate them reliably at scale.
Data observability ensures pipeline health, but not decision quality. AI observability tracks model behaviour and outcomes to catch drift, bias, and misalignment in production.
Failures often occur at inference due to drift, training-serving skew, or changing inputs. These issues silently degrade decisions without triggering data pipeline alerts.
They need a unified view across data, models, and decisions, not isolated metrics. This connects input changes to model behaviour and business impact in real time.
It creates an end-to-end trace from data to decisions, making outcomes auditable. This enables real-time validation, accountability, and regulatory compliance.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



