



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)

.png)
TABLE OF CONTENT




In the high-stakes environment of modern enterprise competition, your strategic relevance as a technology leader is increasingly measured by the financial discipline and production impact of your AI initiatives. Organisations are expanding budgets at an unprecedented pace to accommodate intelligent systems, yet the real-world impact of these deployments remains far more limited than expected.

This disconnect is structural, beginning with a foundational rot that most organisations leave unaddressed: they do not actually know if the data feeding their systems refers to the same real-world entity across disparate sources.
This problem is known as the identity gap. To resolve it, leadership must adopt a first-principles approach to entity resolution, which is the process of associating multiple disparate records into a single logical entity, ensuring that records are detected, matched, and assigned a unique identifier. Without this, your AI strategy is built on a foundation you have not verified, leading to silent decision debt that erodes institutional confidence.
This is a common misconception among leadership teams, and it costs organisations more than they realise. Deduplication is only a basic, one-time step within a larger, relationship-aware process. While it removes exact copies, Entity Resolution goes further by creating golden records for consistency and identity graphs that map complex relationships across systems.
.png)
If your fraud detection model and customer experience platform rely on the same unresolved records, it’s not just a cleanup; it’s structural risk. To address this, organisations must treat data as data products. A true data product is a curated, reliable, reusable asset designed for ongoing decision-making, ensuring your business intelligence is built on a stable, verified foundation rather than fragmented data.
According to the IBM Institute for Business Value (2025), 43% of COOs cite data quality as their top priority, and over a quarter of organisations report losing more than USD 5 million annually due to poor data quality, much of it tied to unresolved data.
[related-1]
This myth is costly because it treats the problem as a one-time cleanup. In reality, enterprise data is fragmented and constantly changing as systems, customer behaviour, and entities evolve.
.png)
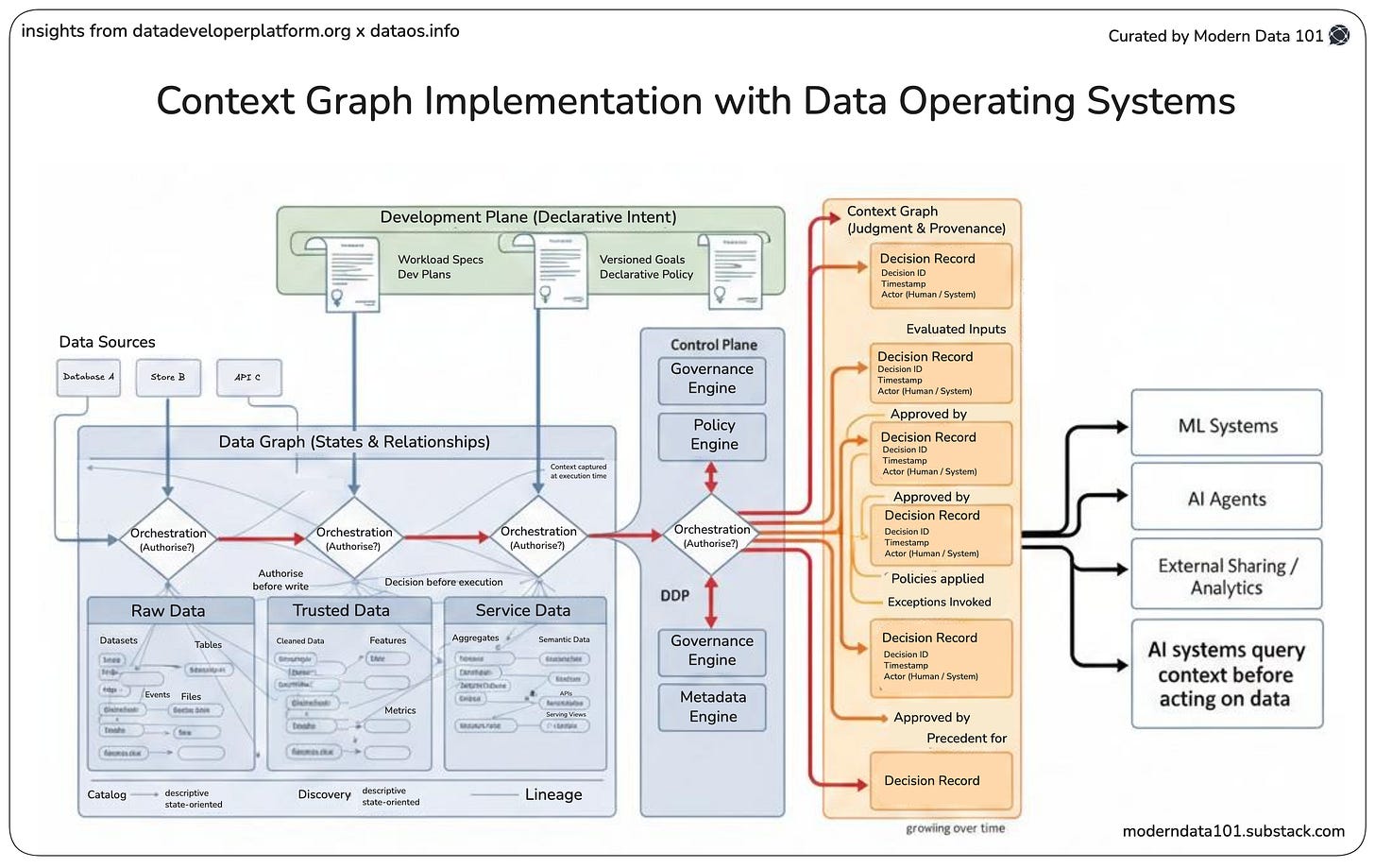
Modern Entity Resolution must be treated as infrastructure rather than a project. It must operate in real time and be embedded directly into automated data pipelines. This alignment is critical when building data platforms for AI, which require unified architectures capable of supporting real-time, context-aware systems. If you treat resolution as a completed task, you fall into the same trap as early data governance efforts, leading to model drift and compliance failures.
By treating Entity Resolution as a living capability, you ensure that AI agents making autonomous decisions about risk or customer experience work with current, accurate data. This reduces the need to constantly move and reinterpret data, which is a core objective of any unified data platform.
[related-2]
Complexity, not just volume, drives the need for Entity Resolution. Even mid-market organisations face risks when the same customer appears differently across systems, especially in AI-driven or regulated environments.
This is where the philosophy of Lean AI becomes essential. Lean AI is an operating philosophy that prioritises efficiency and measurable business value over the pursuit of larger, more complex systems. It focuses on building AI architectures that remain sustainable as adoption grows. For smaller firms, resolving entities at the point of entry is a "Lean" move that reduces operational waste and infrastructure costs.
A striking example of this impact comes from Children's Medical Centre Dallas, which was not a technology failure unique to a large hospital system. They were an entity resolution failure: the same patient appearing as multiple distinct records across systems, with no mechanism to identify, match, and unify them. That is precisely the problem mid-market organisations face every day, just with customer profiles, accounts, and transactions rather than patient charts.
[related-3]
While machine learning-based resolution has advanced significantly, utilising fuzzy matching to identify entities across different formats, algorithms do not solve the governance problem. An algorithm can identify a match, but it cannot decide which version of a record becomes the "Golden Record" or how consistent definitions are enforced across the feature store and reporting layer.
Successful strategies utilise a semantic layer to translate technical schemas into business-friendly representations. This ensures that match results are governed by organisational clarity rather than just algorithmic precision. Organisations should follow the 1:10:100 rule of data quality, which states that resolving entities at the point of entry is far more cost-effective than dealing with the consequences of unresolved data later. The 1:10:100 rule demonstrates that it is 100 times cheaper to resolve a data identity gap at the point of entry than to pay for the catastrophic fallout of a flawed AI decision later.
Without governance and data contracts, systems risk training-serving skew, where production data no longer matches training data. Governance makes Entity Resolution a core requirement, not an afterthought.
[related-4]
This is the most damaging myth because it dictates resource allocation. When Entity Resolution is scoped as a technical task, it is often underfunded and deprioritised in engineering backlogs. The business consequence is severe: poor data quality costs the average enterprise $12.9 million annually, according to Gartner.
[state-of-data-products]
Furthermore, research from MIT Sloan indicates that organisations lose between 15% and 25% of their revenue due to poor data quality. A meaningful share of this loss is attributable to unresolved entity data feeding flawed analytics and degraded AI models. Leadership must recognise that the entity resolution problem is the data strategy problem.
Only 26% of CDOs are confident their organisation can use data in a way that actually delivers business value. Only by resolving the identity gap can you transition from "vanity deployments" to a data developer platform mindset that delivers scalable, auditable, and trustworthy business outcomes.
If your current strategy does not treat entity resolution as a foundational, ongoing capability, every model you deploy is built on unverified ground. The cost of unresolved data compounds quietly through silent decision debt, where choices are made based on drifting models and degrading inputs.
.png)
To protect your strategic relevance, you must shift from a "project" mindset to an "infrastructure" mindset. This involves implementing data products with clear ownership, explicit service expectations, and embedded quality controls. Only by resolving the fundamental "identity gap" can you hope to achieve the level of efficiency, reliability, and value delivery that modern enterprise leadership demands.
It associates multiple disparate records into a single logical entity by ensuring they are detected, matched, and assigned a unique identifier. This resolves the "identity gap," providing a verified foundation for AI and preventing "silent decision debt".
Deduplication is a primitive, one-time step that merely removes exact copies. Entity resolution is a relationship-aware process that creates "golden records" for consistency and identity graphs to capture complex relationships across varied systems.
No, it must be treated as infrastructure embedded in real-time pipelines. Because data constantly evolves with new systems and changing behaviours, treating it as a one-time task leads to model drift and compliance failures.
Yes. Organisations of all sizes benefit from a modern stack to reduce operational inefficiencies and gain a 360-degree view of customers. Complexity, not just volume, drives this need, as even mid-market firms suffer from fragmented entity data.
Human review is vital for high-stakes decisions, such as in healthcare or fintech, where erroneous links carry compliance risks. Modern tools use active learning to identify "borderline" cases for human review, improving the model without manual oversight of every record.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



