


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



Enterprise AI is quickly becoming the new reality, making agents such as copilots, customer service bots, and autonomous workflows essential components of digital operations. These AI agents signify a giant leap forward when it comes to automation, with capabilities to interact, reason, and execute various activities across systems.
An IBM Institute for Business Value report mentioned that 70% of executives feel that agentic AI will be important for their future strategy.
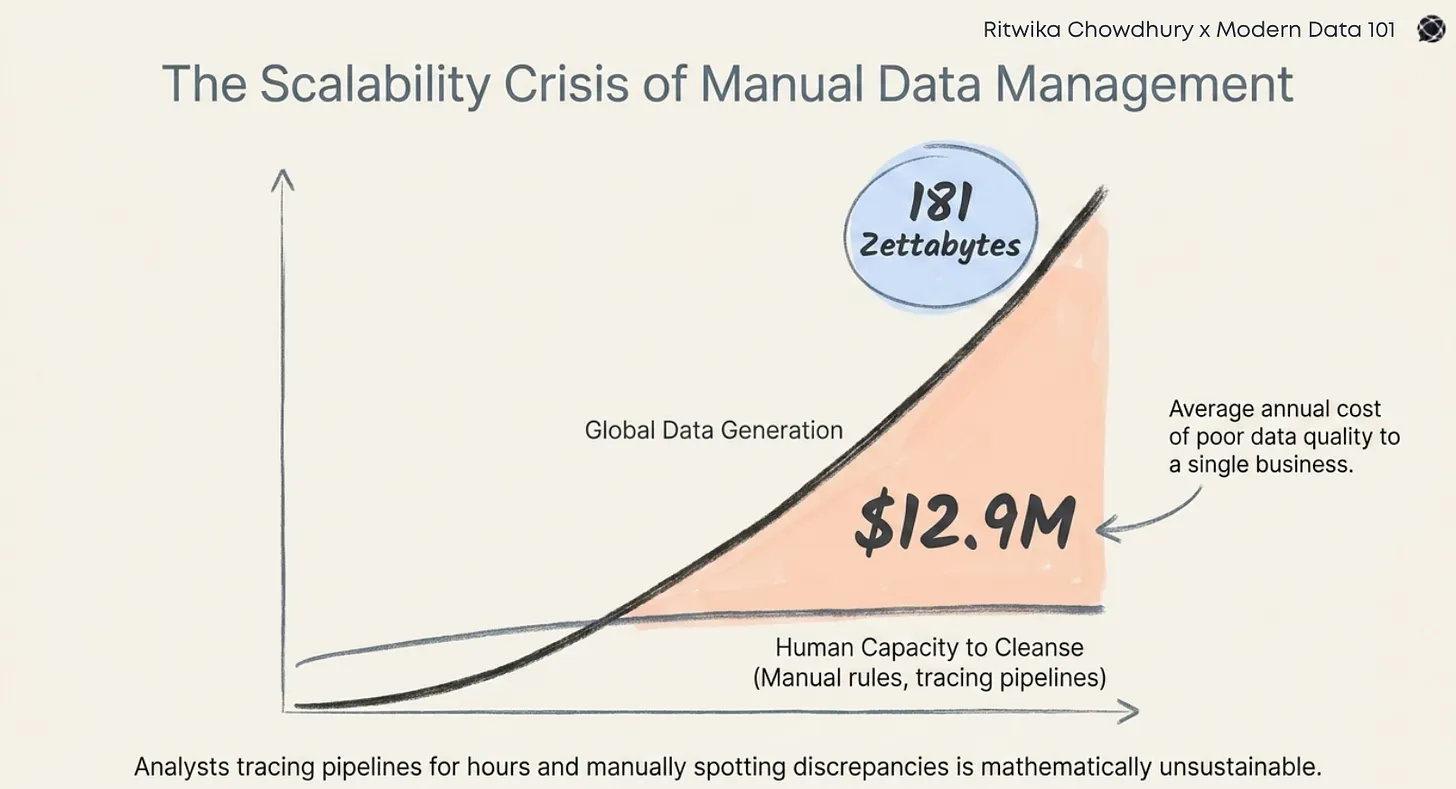
As models continue improving, organisations face the challenge of securing scalable AI agents, but this is possible only when there is more in store than just great models, which is contextual, trustworthy, and discoverable data.
A lot of enterprises have huge volumes of data available for use, but most of that data is fragmented, siloed, or ineffectively documented. Without proper context or lineage, AI agents struggle to understand the data they work on, resulting in hallucinations, disjointed automation, and governance risks.
[report-2025]

As drivers of agentic intelligence, this is where data discovery and catalogs make a strong case for themselves. Enterprise data catalogs enable AI agents to discover the correct data by making assets searchable, visible, and also explainable, so that each decision is backed with confidence.
Leading to increased productivity, data catalogs also help in ensuring scalability for enterprise AI, where multiple agents can work across domains autonomously while also staying true to the foundations of data.
Agentic systems, also known as AI agents, refer to intelligent entities designed in a way to perceive, act, and behave as users or systems to achieve specific objectives. What sets these agents apart is their adaptability, context awareness, and inclination towards the final goal. This is the complete opposite when compared to single-use chatbots that work along predefined scripts.
There have been a lot of definitions for AI agents, and as we defined them, some of the accurate ones are provided below:
“An Artificial Intelligence (AI) agent is a system that autonomously performs tasks by designing workflows with available tools.” - IBM
“An Artificial Intelligence (AI) agent is a software program that can interact with its environment, collect data, and use the data to perform self-determined tasks to meet predetermined goals. Humans set goals, but an AI agent independently chooses the best actions it needs to perform to achieve those goals.” - Amazon
In the complex business dynamic, AI agents are proving to be mission-critical with a dual approach:
As enterprises scale, AI agents are not just transforming how work is done, but what, or who, is actually doing that work.
Gartner estimates 40% of projects involving AI agents will get cancelled by 2027 due to a lack of clarity on business value and increasing costs. There’s nothing wrong with the models, but the reason will be poor access to AI-ready data.
Interpreting the information correctly is a challenge for most organisations as the data is scattered across multiple departments, domains, and tools. When clean, trustworthy, and well-documented data is unavailable, AI agents throw themselves into the dark.
The result?
Compliance risks, hallucinations, and broken workflows simply because there is no lineage, quality, and context.
Adding to these woes is the fact that enterprise teams constantly work in silos, doubling down on narrow Proof of Concepts (PoCs) that may work in isolation, but are not reflective of collective success.
As far as missing out on unlocking ROI is concerned, it has nothing to do with model performance, but the absence of a unified data platform, robust with governance and discovery layers. These layers are foundational, and in their absence, it becomes difficult for agents to have reliable interactions with data ecosystems.
Moving from PoC to production and unlocking real value, there is a need to invest in a data product platform that makes data contextual, discoverable, and trustworthy.
[related-2]
If AI agents are to work effectively in complex enterprise environments, they would need something more than API access. The data they interact with needs to have clarity, context, and control, and this is where data discovery and catalogs become fundamental to success.
The multi-domain ecosystems where AI copilots interact usually don’t guarantee visibility into details such as where the data comes from, its context, its expected users, as well as how it should be handled. These agents, in such situations, face the risk of poor decision-making and hallucinated outputs, both of which are significant concerns in regulated industries.
This is where data catalogs come in, acting as a connective bridge by ensuring stability to data chaos through a metadata-focused view of the overall data landscape.
[playbook]
A few crucial things that modern data catalogs offer are:
Once an organisation starts experimenting with AI agents, this question is unavoidable. Scaling isn’t just a matter of upgrading tools or adding more compute; it’s about creating a repeatable, trusted, and governed environment where AI agents can operate with confidence.
A data product platform delivers that environment by embedding context, discovery, and governance directly into the AI ecosystem. Context ensures that agents work with data that is accurate, meaningful, and understood in both business and technical terms. Discovery gives agents the ability to locate the right datasets, features, and models without navigating silos. Governance enforces secure, role-appropriate access and compliance without slowing delivery.
The difference lies in the productised foundation. By treating data as governed, composable products, the platform enables safe reuse across agent workflows and domains. A semantic layer standardises business definitions so that every AI agent, no matter its function, interprets concepts the same way. This ensures consistent reasoning and decision-making across the enterprise.
For LLM-powered agents, this is critical. A centralised, unified repository allows models to access a single source of truth, removing ambiguity and ensuring they interpret enterprise data correctly. No more re-defining terms for each project or agent, context is embedded once, then reused everywhere.
Operational control is built-in. Role-based access ensures agents only see what they’re authorised to use. Observability tools monitor usage patterns, data quality, and potential bias, giving teams confidence in scaling AI agents responsibly.
When context, discovery, and governance come together in a single, scalable platform, the jump from pilot agents to enterprise-wide deployment becomes a controlled, predictable process. AI agents evolve from isolated experiments to impactful contributors to business value, accelerating decisions, streamlining operations, and creating measurable outcomes.
[related-1]
Putting data discovery measures in place for AI agents is not just a technical activity, but a move to secure scalable, trustworthy AI systems.
Here are some of the best practices to keep in mind:
Involve multiple teams like data, security, engineering, and business for defining and maintaining data context collaboratively. When applied in AI initiatives, cross-functional AI teams ensure that model development, deployment, and governance benefit from diverse expertise and shared accountability.
Metadata management is identified as a top priority for good data practices. Data cataloging should not be an optional approach, but should be fundamental for enabling trusted AI agent behaviour.
Make sure that data catalogs support traceability, auditability, as well as other regulatory requirements for AI-based systems.
Structure data products in a manner that they can be reused across different agentic systems and workflows.
Keep a track on how AI agents use data products, while also monitoring quality signals, usage patterns, and feedback loops for constant improvement.
Many agentic systems get stuck at the Proof of Concept (PoC) stage and never move further. This doesn’t happen because the potential is lacking, but because the data product approach is missing. To open up real value, AI agents need to be treated as products, built for scale, measurable impact, and usability.
It should begin with a set of clearly defined KPIs, such as a reduction in response times, ensuring better decision accuracy, or even increasing process automation. AI agents, with such metrics, become key drivers of ROI.
Embedding feedback loops with observability layers and data catalogs is the next genuine step. When monitoring is conducted about what data agents are using, it becomes easy to identify the areas where breakdowns occur. The results are reliable and consistent iterations in dynamic environments.
A great example will be all enterprises that began with one high-impact use case and then scaled it with a product mindset and shared data foundation. In other words, their success was repeatable by design.
Data discovery is the ultimate multiplier to scale agents. Data catalogs, when embedded in a data product platform, create an essential foundation for agentic AI, where each bit of data is governed, contextual, and reusable.
That should be the ideal AI adoption strategy, where data is truly discoverable, usable, and trustworthy.
Data catalogs offer lineage, observability, and metadata, essential attributes to help agents discover, understand, and trust data for their decisions.
This happens because AI agents don’t have access to contextual, trusted, and AI-ready data.
A data product platform drives a robust AI adoption strategy by enabling governed, reusable, and semantic data products so that agents are able to scale seamlessly across multiple domains and use cases.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




