


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT




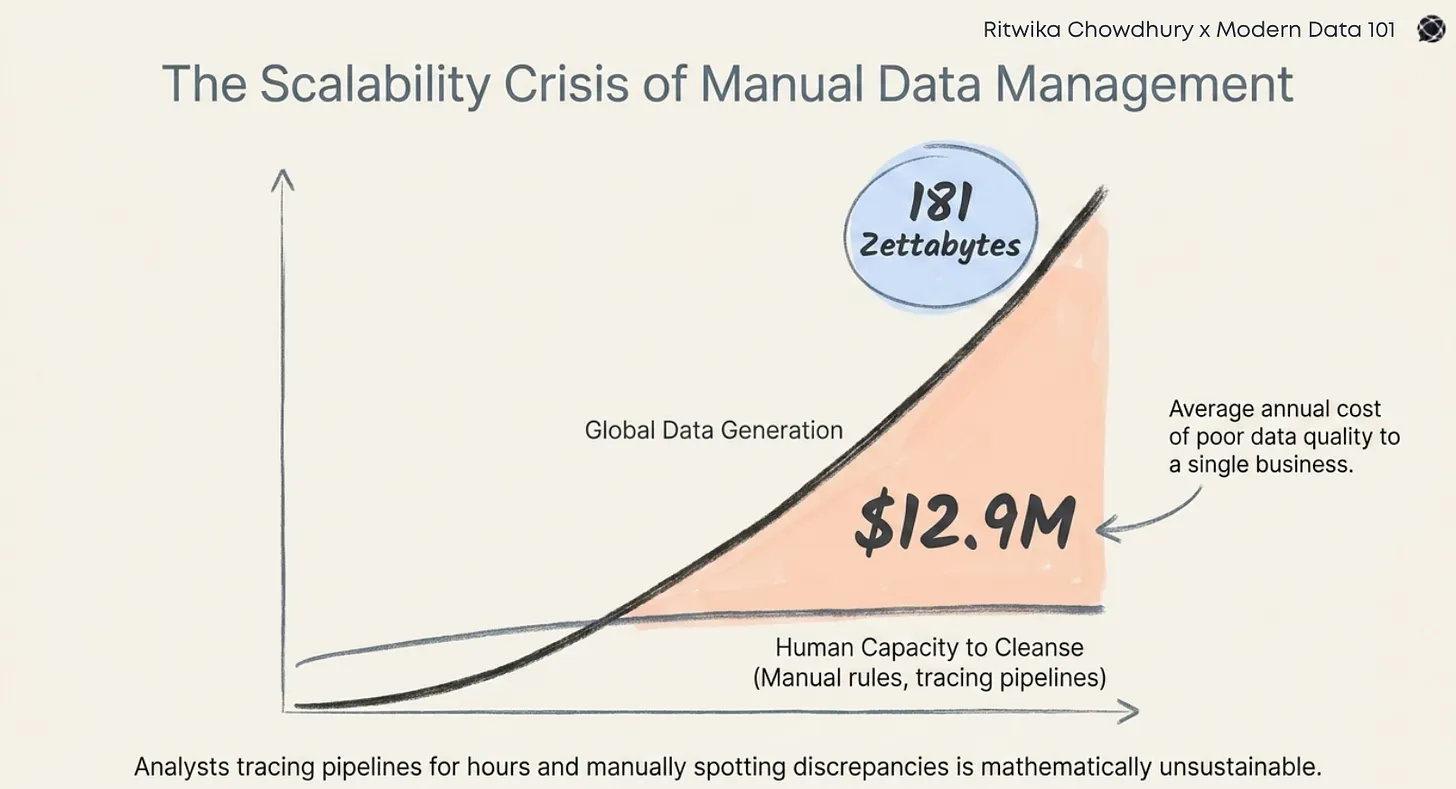
Data, in today's enterprise landscape, resides across various fragmented systems, such as SaaS tools, cloud warehouses, and other legacy ecosystems, making seamless collaboration a distant dream for organisations.
🎢 It is estimated that approximately 402.74 million terabytes of data are created each day.
Despite this complex arrangement, the value of efficient data sharing is hidden from no one. Organisations are actively looking to power their AI initiatives, bolster partnerships, and also meet evolving regulatory requirements, elevating the overall premise of data sharing value. It no longer means just copying datasets from one team to another, but has become a key driver to ensure a trusted and governed foundation for data to be safely understood, reused, and discovered at scale.
A data sharing platform makes this possible by transforming pipelines into dynamic ecosystems in their own right, so that organisations don't just share data, but also the meaning and context across different business and technology departments.
[report-2025]
Data sharing refers to the process of ensuring the secure availability of data resources to multiple consumers. They can include teams, individuals, applications, or other partner organisations, all of them operating within a well-governed and policy-driven framework.
Data sharing is the process of making an organization’s data resources available to multiple applications, users and other organizations. Effective data sharing involves a combination of technologies, practices, legal frameworks and organizational efforts to facilitate secure access for multiple entities without compromising data integrity. -IBM
Data sharing is the process of making the same data resources available to multiple applications, users, or organizations. It includes technologies, practices, legal frameworks, and cultural elements that facilitate secure data access for multiple entities without compromising data integrity.- AWS
There are different types of data sharing.
Amidst all the hype around data sharing today, it's crucial to understand that there is much more in play than just ad-hoc file transfers or data dumping.
The right kind of data share, therefore, works effectively through platforms rich in metadata and standardised models to ensure that data not just moves from one place to another but is meaningfully exchanged, activated, and reused across the entire enterprise.
[related-1]
[related-2]
Today, data sharing has become a key strategic driver for modern enterprises that are working around a hyper-connected, AI-dominated business landscape. When silos are eliminated, it allows organisations to go about things with better agility, trust, and insight. This transforms information into a shared asset from a resource that always seemed to be locked when required.
Here are some important benefits:
1. Elevated Innovation
Shared access to high-quality, governed data means that teams can collaborate better on analytics, AI models, and product development. When engineering, product, and business teams get to tap into shared datasets safely, it becomes possible to gain deeper insights, reduce innovation cycles, and conduct continuous experimentation rather than keeping it as a one-off activity.
2. Better Operational Efficiency
A properly-structured data sharing framework helps in eliminating redundant pipelines, manual file transfers, and point-to-point integrations. In turn, governed data products can be reused across multiple use cases to reduce complexity in infrastructure so that teams are enabled to focus more on high-value analysis and not just reconciliation and maintenance.
3. Increased Regulatory Confidence
Data sharing underlined by governance frameworks ensures that each dataset adheres to compliance with the required regulations, such as HIPAA and GDPR. Built-in data contracts, lineage tracking, and access control help in creating a clearly visible audit trail that reduces risk and enables secure collaboration with regulators and partners.
4. Better Decision-making
With a unified access to contextualised and trusted data, key decision-makers can operate from a single source of truth. There is real-time visibility into customer behaviour, operations, and other market signals to facilitate accurate and quicker decision-making. This is critical in an environment where the overall competitive advantage relies on data literacy and pace.
As far as strategic drivers go from the enterprise perspective, here are a few of them that highlight the data sharing impact:
[playbook]
Despite the promises, there are a few areas where data sharing is accompanied by its share of challenges.
Here are a few of them:
A lot of organisations have a tough time finding and understanding the existing datasets. Without metadata, lineage, and context, teams are unable to evaluate the purpose and reliability of a dataset. This leads to effort duplication and insight inconsistency.
Data resides in different sources such as lakes, warehouses, business apps, and SaaS apps. Each of these has its own permission and access model, making it challenging to set up a secure, unified, and consistent sharing layer.
A lot of sharing processes depend on custom integrations and scripts. These steps cut down the pace of delivery, increase the risk of errors, and also make data sharing inaccessible for non-technical users.
Inconsistent naming conventions, schemas, and data contracts lead to version drift, confusion, and disjointed integrations. Without standardisation, shared data loses its meaning and integrity.
Data producers and consumers tend to operate in silos. While at one end producers lack the incentives to maintain documentation and quality, consumers hesitate to reuse data that they don't fully trust. This undermines the overall accountability and collaboration.

Yes, these challenges are significant, but a data product platform can play a crucial role in doing away with them.
Data product platforms, or DPP, fundamentally reimagine how data is shared across an enterprise, or even beyond it. Instead of depending on manual transfers and ad-hoc integrations, a data product platform treats datasets as products that are discoverable, governed, and reusable by design.
📕 If you’re looking to understand why your team needs a Data Product Platform in detail, click here!
For mature enterprise teams, the Data Developer Platform (DDP) offers a lot of detail that takes everything into account, from access control to configuration management.
Such a platform-driven, productised approach transforms data sharing from a technical challenge to a scalable capability in itself.
Here’s how a Data Product Platform ensures improved sharing of data:
The Data Product Platform specification ensures that every data product is discoverable, understandable, and addressable. By treating shared datasets as first-class data products, consumers get a transparent and standardised contract that defines what data is and how it is used. This also removes any ambiguity about accessibility, ownership, and context, so that sharing becomes reliable and transparent.
Each data product also has built-in metadata, quality indicators, and lineage. When this data is shared across the platform, consumers get automatic visibility into how the data was created, its freshness, and how trustworthy it is, which ensures confidence and accelerates adoption rates.
A data platform like this acts as a unified infra spec that prioritises a consistent, outcome-first experience. With consistent connectors, APIs, and access controls, data sharing across domains or partner ecosystems becomes seamless and secure. It also eliminates the complexity that comes with too many and inconsistent sharing mechanisms.
The self-service capabilities of a Data Product Platform allow data producers to publish data products independently. It will enable consumers to easily discover, request, and integrate without any heavy operational bottlenecks, democratising sharing and scaling across different teams and domains.
DPP helps in setting a balance between consistency and decentralisation, allowing domain teams to keep their local ownership while also ensuring global governance, discoverability, and interoperability. The structure is supportive of large-scale, cross-organisational sharing.
DPP comes with built-in deployment, configuration, and change management, making lifecycle tracking, versioning, and change management a very sorted process. Shared data products also remain auditable, updated, and reliable as they grow with time.
A Data Product Platform elevates governance further by embedding security and access control directly into the sharing process. Capabilities such as Attribute-Based Access Control (ABAC), deployment and environment management, as well as infrastructure orchestration, make sure that governance is never an afterthought but is built within.
📕 Read here about some of the best practices you can implement for AI-powered governance for your enterprise.
When data products are shared, their associated permissions, audit trails, and compliance policies move with them. It translates to the fact that sharing isn’t just about the enablement of technical access but about ensuring traceability, accountability, and security by design.
A DPP enables governed, secure, and scalable data sharing by treating datasets as reusable data products. It offers a unified infrastructure, self-service tools, and metadata management to simplify access control, discovery, and lineage tracking. This ensures trusted data exchange across cloud environments and teams.
Governance in DDP ensures trust, accountability, and compliance at the time of data sharing. By embedding access control and governance into the platform through automated monitoring, policies, and data quality checks, organisations can easily scale governed data sharing while also maintaining consistency and security across all distributed domains.
Modern data platforms come with in-built features like data lineage tracking, Attribute-Based Access Control (ABAC), and environment management to ensure that each dataset has its own audit logs, access rules, as well as compliance metadata. This makes data sharing secure and auditable across partner ecosystems.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




