


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)

.png)
TABLE OF CONTENT



Edge AI is often framed as a breakthrough in hardware acceleration or model optimisation. However, research and real-world deployments tell a different story. 25% of edge AI projects fail at the PoC stage. Across industries, Edge AI initiatives are stalling because data infrastructure remains centralised, manually operated, and hostile to autonomy.
As organisations race to deploy AI at the edge, a critical challenge emerges: how do we democratise access to the data and infrastructure needed to power these intelligent systems?
The answer lies in rethinking our data infrastructure through a product lens, building self-serve platforms that treat edge AI workloads as first-class citizens rather than afterthoughts.
Artificial intelligence at the edge scales when the data infrastructure itself becomes a self-serve product. This article explores why that is, and what it means for modern data teams building platforms for the edge.
[playbook]
Edge AI refers to the deployment of artificial intelligence algorithms and models directly on local devices, like sensors, IoT endpoints, and edge servers, enabling real-time data processing and analysis without constant reliance on cloud infrastructure. Unlike traditional cloud-based AI, where data travels to centralised data centres for processing, edge AI brings intelligence to where data originates.
The distinction between edge AI, distributed AI, and traditional AI architectures reveals itself most clearly in where computation happens and how models are deployed.
When we think of artificial intelligence at the edge, a lot of our focus goes into thinking about the hardware aspect, sometimes as we do for core data structures, like a data centre. Hardware matters, but it’s only one part of the story.
Edge AI = AI models running close to where data is produced (on devices)
Those devices need hardware, yes. But the real game-changer is the software, data pipelines, and tooling that make it usable at scale.
Hence, the limitations of edge AI are not limited to issues like configuration challenges, complex hardware implementation, limited compute power, heat management and overall fragmentation of hardware.
Edge devices like cameras, sensors, gateways, robots, smartphones, etc., provide only the execution environment. The software capabilities, specifically data architecture and platforms these Edge AI applications rely on, are crucial for making them deployable and scalable.
[related-1]
The following are the challenges of Edge AI faced by enterprises:
Unlike the standardised, mature environment of cloud computing, edge AI lacks common frameworks for hardware, software, and communication protocols. Industry fragmentation leads to competing device-specific software and techniques, causing compatibility issues and requiring custom workarounds.
Edge AI deployments need to be self-dependent, from infrastructure resources like compute, storage, and governance to consumer-facing data outputs. Every edge location might need isolated resources, yet these isolations should be manageable from a central platform.
Traditional data platforms weren’t designed for this distributed tenancy model. They assume centralised control and struggle when autonomy meets governance across hundreds or thousands of edge devices.
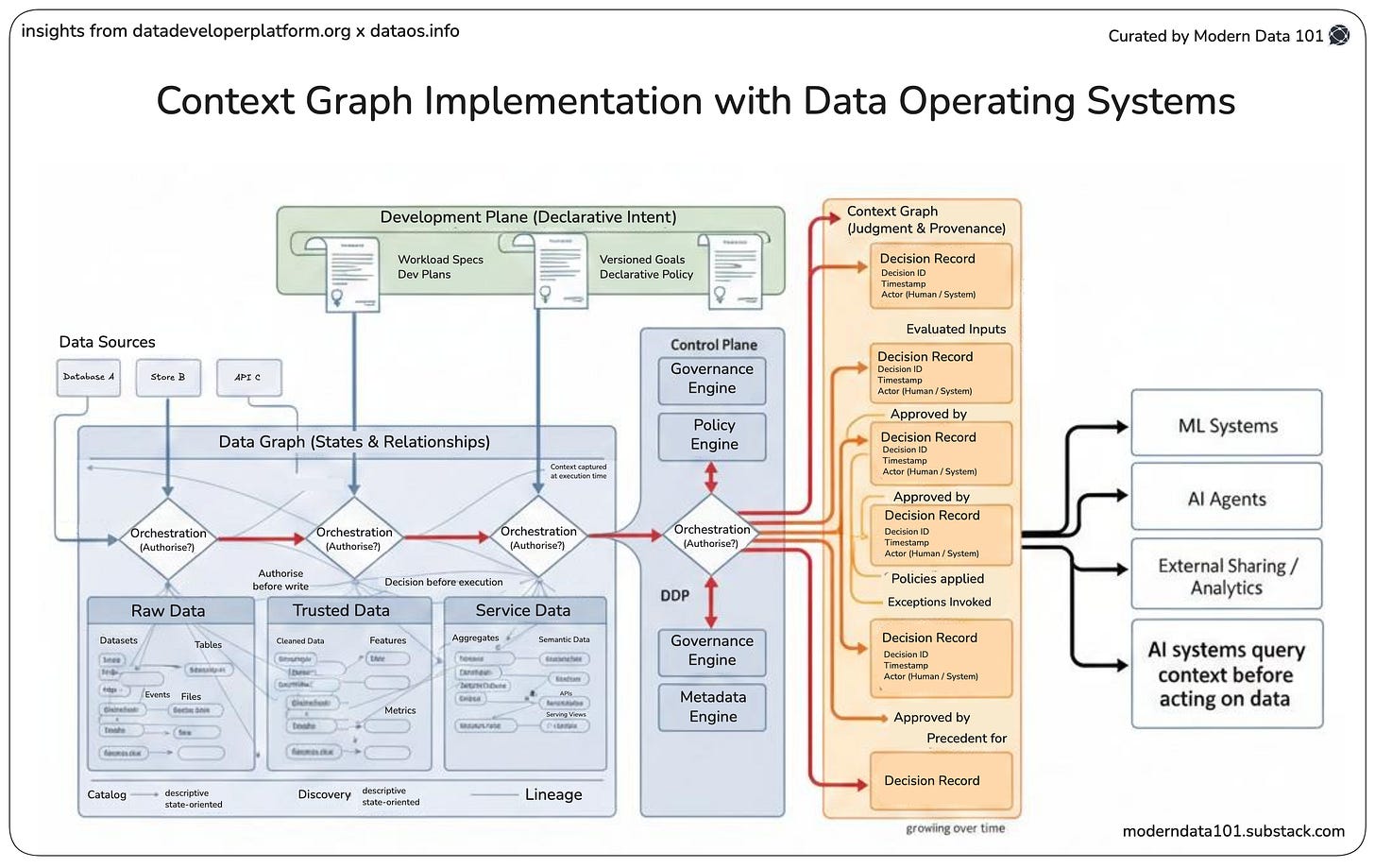
When edge AI models make decisions affecting safety or revenue, stakeholders need to understand: What data fed this model? What transformations were applied? What policies govern this data? Which version of the model is running where? Without treating edge AI workloads as data products with embedded metadata, lineage, and contracts, you lose this visibility. Troubleshooting becomes an archaeological excavation. Compliance becomes impossible to prove.
[related-2]
Managing a distributed network of AI models presents complex logistical challenges. Securely updating, versioning, and monitoring model performance across countless deployed devices is difficult but necessary to effectively scale implementation for artificial intelligence at the edge.
Your edge AI workload will likely span multiple tool stacks, such as IoT platforms, edge runtimes, cloud ML services, and existing on-premises systems. Without a unified data platform that can orchestrate across these heterogeneous environments, you pay an “interoperability tax” in the form of custom integrations, brittle connections, and endless maintenance overhead. Data engineers become integration engineers, spending time on plumbing rather than value creation.
If we trace the major challenges of Edge AI, we’d notice that they aren’t separate problems requiring separate solutions. They’re symptoms of a single underlying issue: the absence of a unified data infrastructure designed for the edge AI era.
What is self-serve infrastructure?
Self-serve infrastructure means developers or teams can deploy, test, update, and manage AI systems on their own, without needing long IT processes or manual backend work.
Think of it as: “Click a button and your AI runs on the edge device.”
How does a data infrastructure like this boost Edge AI applications?
Let’s consider the classic use case of a Data Developer Platform, which is an effective example of a self-serve data infra.
A Data Developer Platform (DDP) is a unified infrastructure specification to abstract complex and distributed subsystems and offer a consistent outcome-first experience to non-expert end users. Think of it as an Internal Developer Platform (IDP) specifically designed for data professionals like data engineers, data scientists, ML engineers, working in distributed environments like edge AI deployments.
What makes a DDP truly “self-serve” is not just about providing tools. As the DDP specification articulates, self-service means having resources ready to use based on user requirements. The data scientist declares input/output locations and transformation steps, and the self-serve infrastructure furnishes ready-to-use workflows, services, secrets, connectors, monitors, and other resources to run the transformation.
Apply this to edge AI: the ML engineer specifies the model, target edge locations, and performance requirements. The DDP handles provisioning edge runtimes, configuring data pipelines, deploying models, setting up monitoring, and establishing feedback loops, all declaratively, all automatically.
The Data Developer Platform specification identifies finite sets of unique resources that form the building blocks of data operations.
For artificial intelligence at the edge, these resources compose together to enable the full lifecycle from model development to edge deployment to continuous evolution. Think of them as Lego pieces that can be assembled and reassembled to construct any edge AI use case.
[data-expert]
Instead of manually setting up every edge deployment, teams declare their requirements through resource specs. DDP resources, like workflow, service, policy, monitor, secret, compute, cluster, and contract, make up the language for building edge AI workloads.
Suppose you want to roll out a predictive maintenance model across fifty factory lines. You create it once as a collection of resources, specify the target workspaces (edge locations), and let the data platform handle provisioning and orchestration. So, no more repetitive setup.
This declarative approach enables Infrastructure as Code (IaC) for edge AI. Developers create config files for edge AI workloads and declaratively provision, deploy, and manage them. Everything becomes version-controlled, code-reviewed, and reproducible. Configuration drift, a persistent problem in distributed edge environments, is eliminated through standard base configurations.
Edge AI deployments require isolation. Each factory line, each retail store, each autonomous vehicle fleet needs its own isolated set of resources while still being manageable from a central platform. The DDP concept of workspaces, logical isolations/namespaces on common capabilities, enables this distributed tenancy model. Teams have the option to choose to isolate resources at domain levels (all manufacturing), at use-case levels (predictive maintenance), or at specific edge device levels, depending on their operational needs.
The orchestrator in the DDP control plane acts as the heart of edge AI operations, ensuring resources execute in the right order, validate access and masking policies on data before every operation, and generate comprehensive metadata that gets logged for full lineage tracking.
For artificial intelligence at the edge, this means: models deploy to the right edge locations in the right sequence, data flows respect privacy policies even at the edge, and you maintain complete visibility into what’s running where and how it’s performing.
A little bit about Data Products as Atomic Units of self-serve platforms
At the heart of self-serve infrastructure is the data product construct. A data product is a fundamental architectural unit that bundles data with its metadata, lineage, transformation logic, quality contracts, and governance policies.
This bundling makes data products inherently portable and self-describing, exactly what you need when deploying to hundreds of distributed edge locations. The data product carries its requirements with it: what compute resources it needs, what policies apply, what quality thresholds must be maintained, and how it should be monitored.
Well-designed data products become templates. The predictive maintenance model a team develops for one manufacturing line, packaged as a data product with all its resources, policies, and SLOs, can be deployed to fifty other lines with minimal modification. The customer sentiment analysis running in one retail location can scale to hundreds of stores. The key is that you’re not copying infrastructure or code; you’re instantiating a data product template with location-specific parameters.
One of the most important capabilities for ensuring the success of Edge AI is the ability to connect technical metrics to business outcomes. Data platforms & architectures like a data developer platform and its assets, data products enable organisations to leverage transparent metric trees that connect low-level technical metrics (model accuracy, latency, throughput) to high-level business KPIs (revenue, customer satisfaction, operational efficiency).
Let’s think of an example:
Consider a manufacturing use case where edge AI predicts equipment failures:
A well-implemented DDP surfaces these metric trees, making it transparent how edge AI investments drive business value. Decision-makers can roll out informed decisions across solutions and operational tracks without needing to understand every technical detail. They see the factors that move the metrics they care about.
This transparency proves essential for securing ongoing investment in edge AI initiatives. When business leaders can directly see how edge AI deployments contribute to strategic objectives, funding future projects becomes straightforward.
We’re moving toward a future where the line between cloud and edge data disappears. Data will flow to wherever processing creates the most value: models train in the cloud, adapt at the edge, and generate insights locally while still contributing to global intelligence.
This shift requires rethinking core assumptions. Data gravity flips; processing increasingly moves to the data, reshaping how platforms handle quality, governance, and design. Real-time becomes the default, with batch used only for cases like model retraining.
Architectures turn distributed-first, built for eventual consistency, graceful handling of network gaps, and local autonomy even when disconnected. And we move toward hybrid intelligence, where the cloud handles heavy training, the edge handles millisecond inference, and the system continuously learns through their interaction.
Self-service AI lets non-experts discover, create, and use AI assets without having to involve data science teams. It offers prebuilt models, automated pipelines, governed datasets, and low/no-code interfaces so teams can independently push out insights or automate tasks. The aim is decentralised use of AI while maintaining standards for quality, governance, and security.
Edge computing involves running compute, storage, and AI workloads near where data is produced. The infrastructure comprises edge devices (sensors, cameras, industrial machinery), edge gateways (local aggregation and pre-processing), as well as micro data centres or ruggedised servers and connectivity layers (5G, Wi-Fi, and mesh networks). It uses containerised runtimes, lightweight orchestrations, remote management, and security focused on distributed, low-latency applications.
Cloud AI executes the heavy-lifting, like compute tasks, training large models, managing datasets, and running scalable analytics. The focus is on power, flexibility, and keeping everything under central control.
Edge AI is a different story. It works right where the data comes in, so it can react in milliseconds, even if there’s no internet. Everything happens locally, which means more privacy and way less bandwidth. Edge AI is all about speed, real-time decisions, and staying efficient.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



