


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


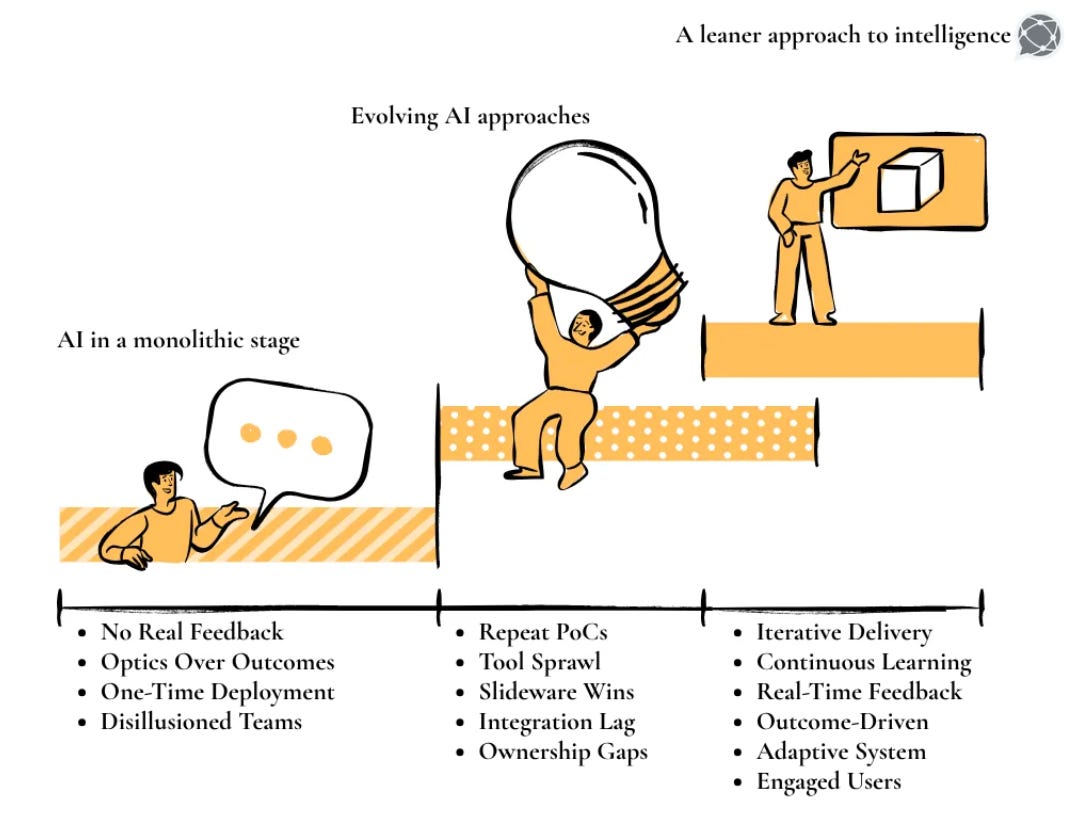


%20(1).png)
TABLE OF CONTENT



This is Part 1 of a Series on FAANG data infrastructures. In this series, we’ll be breaking down the state-of-the-art designs, processes, and cultures that FAANGs or similar technology-first organisations have developed over decades. And in doing so, we’ll uncover why enterprises desire such infrastructures, whether these are feasible desires, and what the routes are through which we can map state-of-the-art outcomes without the decades invested or the millions spent in experimentation. This is an introductory piece, touching on the fundamental questions, and in the upcoming pieces, we’ll pick one FAANG at a time and break down the infrastructure to project common patterns and design principles, and illustrate replicable maps to the outcomes.
Subscribe to be the first to be notified when the next part drops!
The Myth of the FAANG Data Platform
FAANG Infrastructure Was a Historical Accident
The Challenge for “Un-fanged” Organisations
Pivot: To Be or Not to Be FAANG, that is Not the Question
The Mindset Shift: From “Data Pipelines” to “Data Products.”
The Technology Formula (if we must be concrete)
When we think of the data platforms of the tech elite, say, Amazon, Google, Meta, Netflix; what we often imagine is a vast, custom-built infrastructure of streaming, batch, feature stores, ML pipelines, and near-infinite scale. And that imagination isn’t wrong.
But when we look behind the curtain, the data practitioner community in r/dataengineering validates something critical: the circumstances under which those state-of-the-art data architectures exist are wildly different from the typical enterprise environment.
An enterprise may have vast scale and manpower, but they probably have specialisations in categories like retail, banking, or manufacturing. With large resources focused on these core aspects, they may not have the bandwidth or the strategic prowess to invest in becoming a “tech-elite” with vast spends on manpower behind the data and AI-specific stacks.
One user states:
Speaking from Amazon experience… The company is so big… Engineering hours saved for the price of a product isn’t really a concept they pay attention to culturally… outside of FAANG, most businesses… don’t have thousands of platform & data engineers, or hundreds of millions $ to piss away on this stuff.
However, the desire to reflect the outcomes of the likes of Uber and Netflix is consistent due to the quality of technology that is consistently pro-business. The FAANGs of the industry spent decades mastering their tech stack and have a technology-first approach. While many other organisations, even though vastly successful, did not have a technology-first strategy to begin with.
But technology has caught up with us, and businesses that play by the rules of vast data are projected to be the pioneering brands of the next few decades. However, it’s impractical to even believe that it’s possible to build “Faanged” data platforms in a year or less.

One user puts it plainly:
FAANG do their own things... Originally, it was just those companies that could do this stuff purely because of the manpower.
Another said:
People shouldn’t ‘look up’ to how FAANG manages data, because 99% of the time, their answer is just ‘throw money at it’. This doesn’t work for anyone else.
These voices speak to a truth that often gets glossed over in industry narratives: the FAANG-style platform is less replicable than we’d like to admit.
The architectures at Netflix, Meta, and Amazon weren’t born of an elegant “plan”. They were built organically over decades of trial and error, almost accidental in nature: changes and unimaginable pivots in business strategy, countless failures, and obstacles. These data stacks are like hot moulded iron, still under the fire and forever resigned to that destiny.
They were outcomes of survival mechanisms in the absence of managed infrastructure. When you process petabytes a day, before cloud elasticity and managed Spark clusters were a thing, you engineer everything yourself.
FAANG’s platform designs, like their in-house schedulers, query engines, lineage tools, and metadata layers, are glorious results of constraint and engineering will. The open-source and SaaS ecosystems that emerged later are, in fact, the commercialised externalities of those internal struggles.
“Throwing money at the problem” worked for them because they had it, being technology-first institutes from the get-go. The rest don’t have this sort of budget specifically for data or tech reforms, given that the majority of the budget is prioritised for the development of their core capabilities in business.
So the question isn’t whether you can build like FAANG. The question is: can you achieve FAANG-like capability without recreating their organisational overhead?
If you are not a FAANG, i.e. if you don’t have tens of thousands of engineers, petabyte-scale budgets, or custom-built kernel-level tools dedicated to data and AI engineering, you still need FAANG-style outcomes:
Yet at the same time, you do not have FAANG resources.
The gap: you need the capabilities, but cannot replicate the scale or the cost model.
Most organisations hit this wall during digital transformation efforts. They adopt “off-the-shelf” tools hoping to move faster, but quickly realise these tools assume an idealised architecture that doesn’t fit their reality. On the other hand,
custom-building a FAANG-like data platform from scratch quickly becomes an engineering black hole, consuming years, budgets, and morale.
Arguably, the defining question of this decade in enterprise data is:
What is the solution to creating FAANG-like data infrastructures without spending the same resources, cost, or time (decades) on it while not compromising the quality and similarity of outputs that are relevant to business?
On face value, the question seems ridiculous. How could experienced organisations, executives, or strategists expect similar value by not investing to the same degree?
Despite the seemingly unrealistic nature of the expectations, this is the most ideal ambition to chase in the age of advanced technology that upgrades every three months or completely changes face.
Despite the harsh extent of expectations, this is exactly how to aim high and data leaders, irrespective of how unrealistic it sounds, are stressing on initiatives that get them closer to FAANG-like blueprints of business outcomes, even if not exact replicas of their architectures (which is factually non-feasible given the stark differences in environment).
The short answer is: you replicate FAANG outcomes, not FAANG architectures.
The FAANGs designed better systems of abstraction instead of better tools. They created internal developer platforms for data: self-service environments that abstracted infrastructure complexity, standardised metadata, and enabled composability.
Tech giants like Google, Amazon, Netflix, Spotify, and more built the first Internal Developer Platforms internally to reduce the burden on their Ops teams. By abstracting infrastructure complexity away from their developers, they found remarkable improvement in dev experience and productivity. They also found it an effective mechanism to increase developer autonomy while enabling uniform standards adoption.
~ Source: Independent Article on WayScript
Everyone else tried to mimic the tools (Kafka, Spark, Airflow), but not the principles,which is why the gap widened even as open-source matured. To recreate their outcomes without the FAANG budget, organisations must emulate the design principles.
Think of Data Developer Platforms (or DDPs) as operating systems for data teams:one that abstracts the plumbing, enforces standards, and accelerates business outcomes by design. This is not a full rebuild of FAANG infrastructure but a hybrid adopt or buy + customise or build model, optimised for the businesses that have probably been core-first instead of technology-first in their strategy.
Instead of reinventing every component (ingestion clusters, feature-store, streaming engines, orchestration fabric, data catalog, lineage, BI/ML serving), you adopt modern managed or SaaS infrastructure: scalable data warehouses/lakes, managed streaming/ingestion, orchestration frameworks, data catalogs, monitored pipelines.
On top of that infrastructure, you layer your enterprise-specific design patterns, the business domain models, ingestion-to-model flows (ODS → CDM → ADS), serving models for BI/ML, data-product definitions, governance frameworks, API/consumption patterns, i.e., the things you build because you have domain context, nuance, competitive advantage.
This hybrid aligns well with a community commentary about realistic enterprise constraints and the need to focus engineering effort:
Even if you’re paying a slightly higher unit price for the service… outside of FAANG most businesses find it more cost-effective to adopt modern tooling that takes away all of that pain.
Instead of building a dozen brittle integrations of tools, the foundation IDP/DDP provides:
Unified metadata control plane: One schema, one lineage, one governance layer, automatically propagated (e.g., DataSchema as a metadata management system by Meta, formerly Facebook).
Composable pipelines: Low-code or declarative abstractions that reduce 90% of orchestration effort. (e.g., Netflix’s Metaflow and Spotify’s Flyte, which let data scientists define workflows declaratively, abstracting infrastructure complexity and improving reproducibility.)
Global metrics and models: Shared, versioned, and discoverable, like code libraries, but for data. (e.g., Uber’s Palette and MetricStore, which enforce a single source of truth for business metrics and ML models, ensuring cross-team consistency.)
Auto-governance: Policies baked into the runtime, not bolted on. (e.g., Google’s Data Governance Automation Framework that embeds privacy, access control, and data classification into its processing layer: governance as code rather than post-processing compliance.)
Unified observability: A single truth for data health, quality, and performance, not 10 dashboards. (e.g., LinkedIn’s DataHub + Kafka ecosystem, which provides end-to-end lineage, health monitoring, and anomaly detection across datasets, pipelines, and serving systems.)
This architecture allows smaller teams to operate with FAANG-like leverage, focusing on what to build (business models) rather than how to build (infrastructure).
FAANG-level results emerge when every data artefact (table, model, API, dashboard) is treated as a product: versioned, tested, monitored, and owned.
That mindset is portable. You don’t need a $100M infra budget, but you definitely need the contractual rigour of software engineering applied to data.
(*Excerpt from Death to Data Pipelines: The Banana Peel Problem)
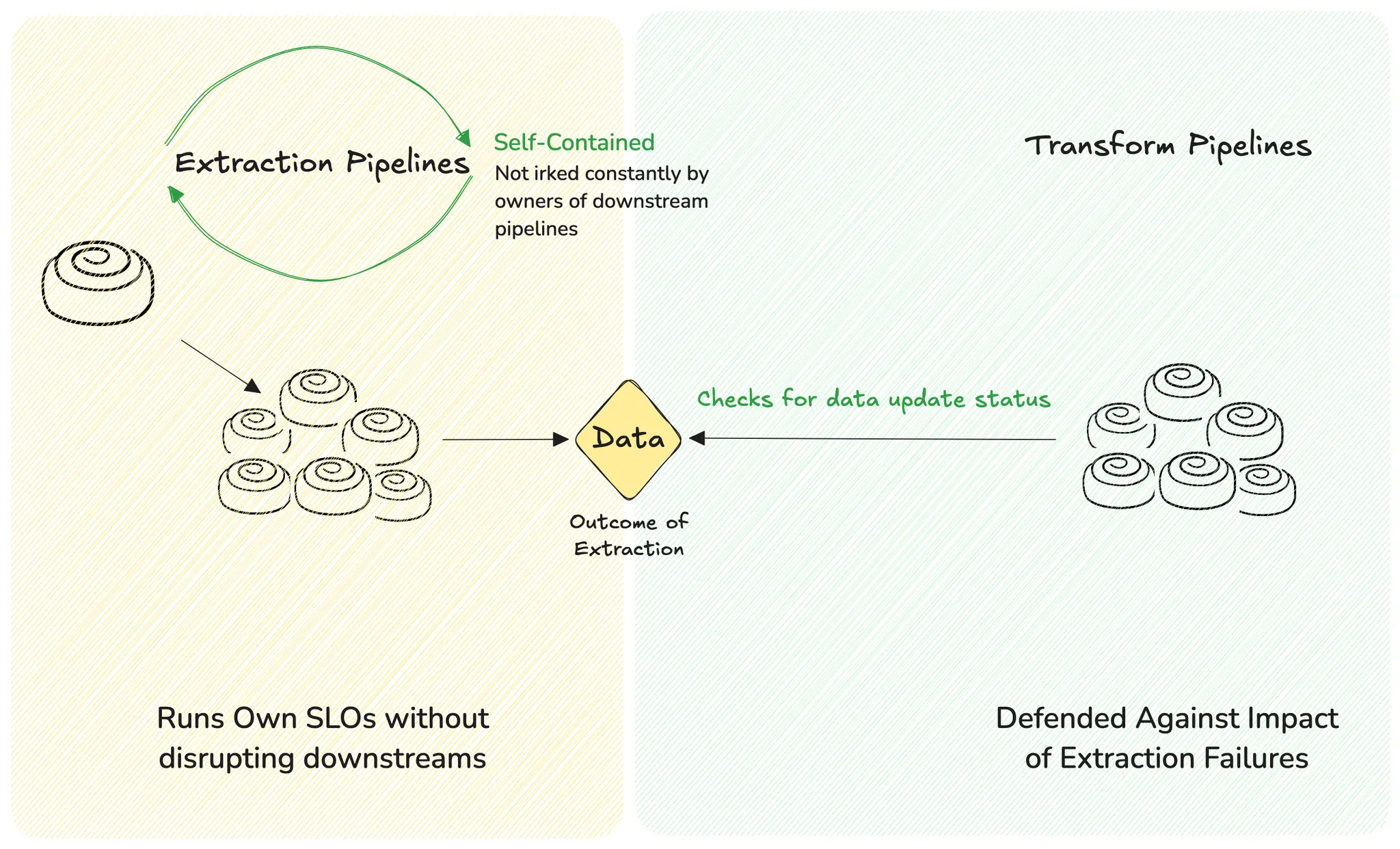
Let’s go back to the conversation of pipeline-first vs. data-first. In pipeline-first, the failure of P1 implies the inevitable failure of P2, P3, P4, and so on…
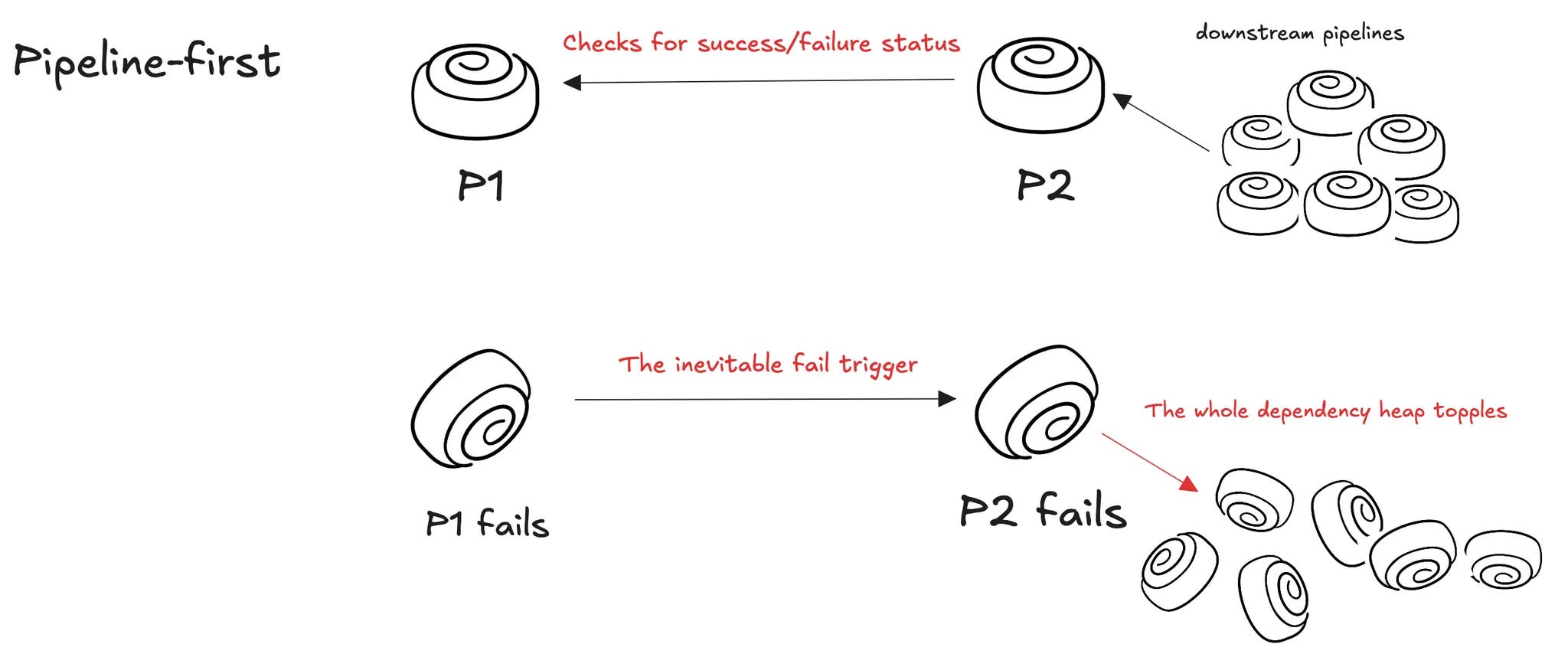
In data first, as we saw earlier, P2 doesn’t fail on the failure of an upstream pipeline, but instead checks the freshness of the output from upstream pipelines.
Case 1: There’s fresh data. P2 carries on.
Case 2: There’s no fresh data. P2 waits. P2 doesn’t fail and trigger a chain of failures in downstream pipelines. It avoids sending a pulse of panic and anxiety across the stakeholder chain.
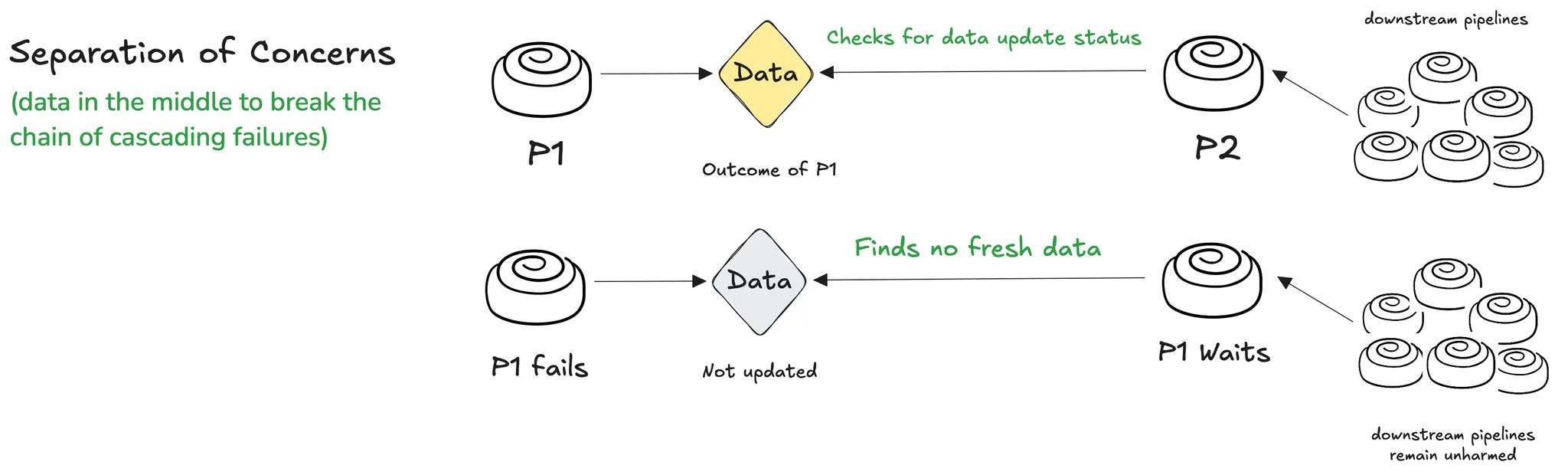
In this defensive platform ecosystem, data is the decoupling layer.
We don’t tie transformation logic to the act of extraction. We don’t let transformation fail just because data didn’t arrive at 3:07 AM. Instead, our transformation pipelines ask a straightforward question: “Is the data ready?”
If yes, they run. If not, they wait. They don’t trigger a failure cascade. They don’t tank SLOs.
FAANG ≈ (Abstractions × Automation × Accountability)
Non-FAANG organisations can get 90% there by:
In the new technology-first business mindset, the value is in scaling context.
When context (lineage, metrics, ownership, purpose) flows automatically through your data ecosystem, small teams can act like big ones, because they have visibility, velocity, and verifiability.
That’s the state-of-the-art infrastructure’s superpower, and it can now be replicated with intentional design instead of infinite spend.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡

Find me on LinkedIn 🤝🏻
Unlock the secrets of the Data and AI Stack: Take Our 10-minute Survey and Gain Exclusive Access to Survey Insights and an expert-certified Enterprise AI Playbook drafted in collaboration with seasoned Data & AI Leaders, Strategists, and Consultants, and by the authors of the recognised Data Product Playbook with over 3000 adopters.
In our 1st edition of The Modern Data Survey, 230+ data leaders and practitioners participated to enable rich insights that have shaped the community in countless ways since. Join the 2nd edition to contribute your ideas to The Modern Data Report, 2025-26!

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



.avif "Brij Mohan Singh")
