


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



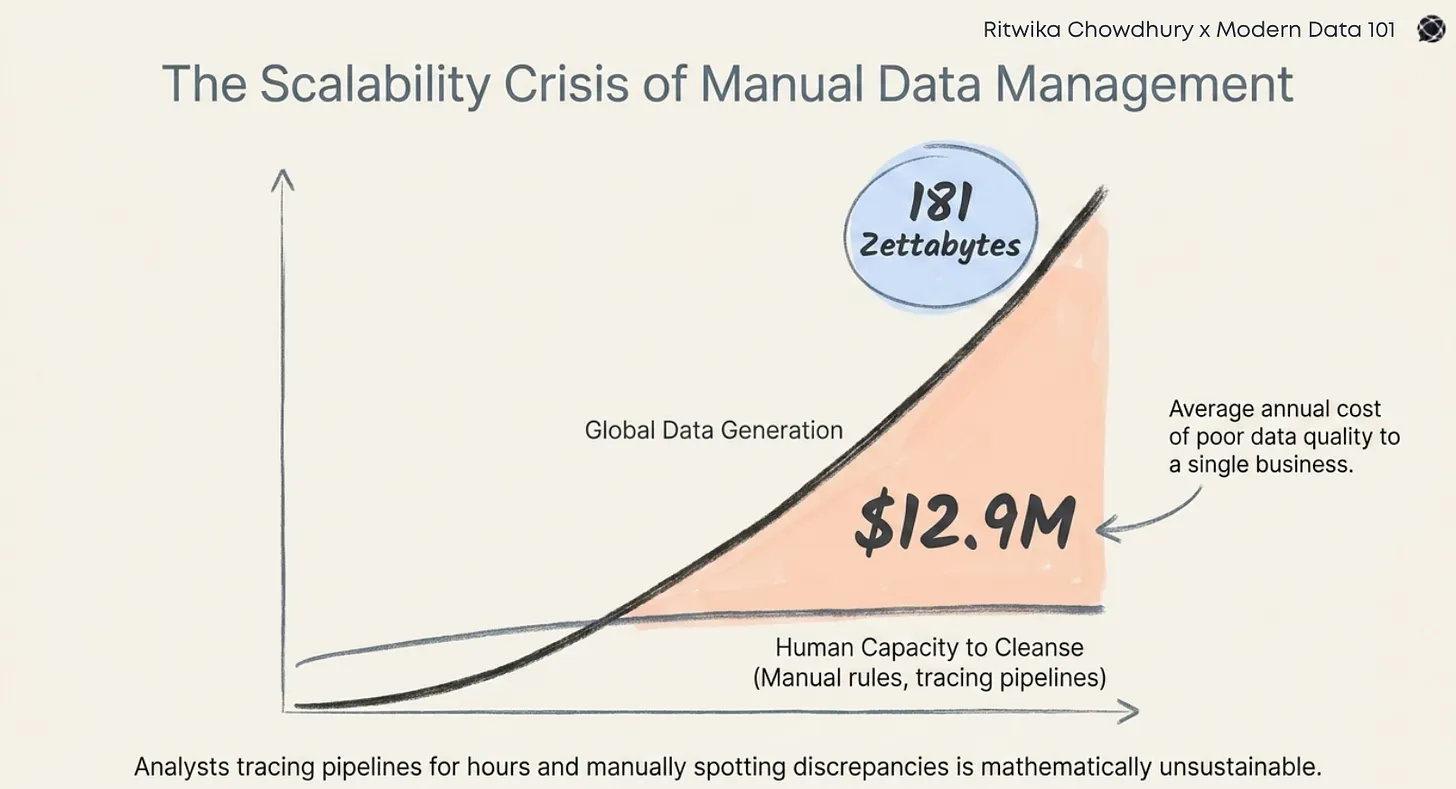
The value of a data product is never contained within its boundaries. It emerges from the number, quality, and friction of its connections, and the signals from its produce. Connectivity is the architecture that turns isolated signals into coordinated intelligence. The mistake most teams make is assuming insight comes from accumulation, when in reality it comes from interaction.
The system becomes “intelligent” when the surface area of interaction between components expands.
It’s not from the sophistication of isolated components. Intelligence is an emergent property of the feedback loops between producers, consumers, and the decisions that reshape the system in return.
Without the network effect built into the earliest stages of strategy, organisations trap themselves in linear architectures that can never produce nonlinear outcomes. They add more resources but get diminishing returns because the underlying system doesn’t compound.
And this is where the Data Network Flywheel truly begins. When every data product learns from every other, when every interaction strengthens the next, the system stops being a cost centre and is a self-accelerating engine of value.
The Amplification Matrix isn’t a maturity model, but one that helps us understand how a system evolves as its internal connections deepen. Each quadrant represents a distinct state of system behaviour: how information flows, how meaning accumulates, and how value compounds. The movement across quadrants traces a shift in system dynamics, from isolated components to a coherent, self-reinforcing network.
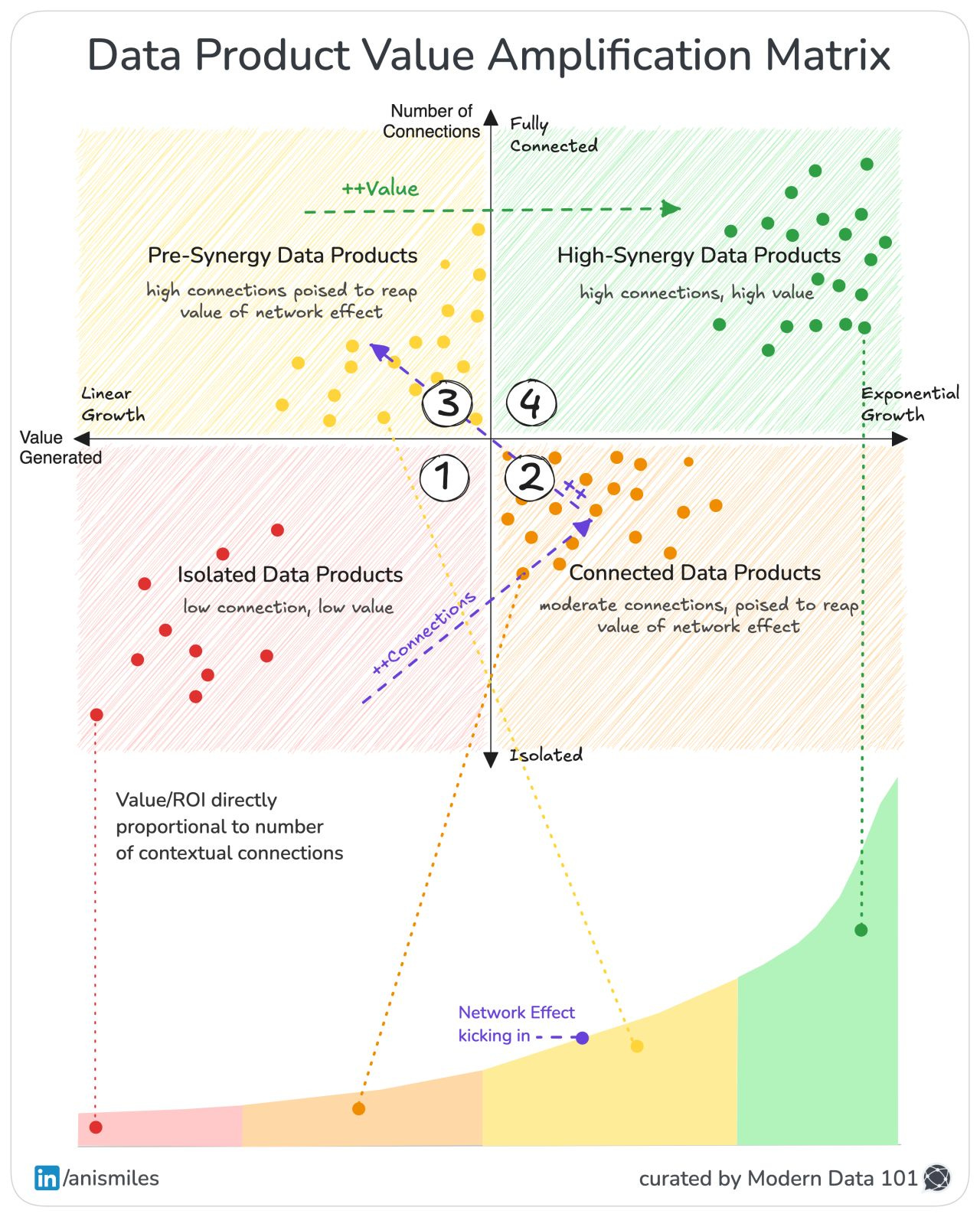
(Low Connection, Low Value)
These are Data products that operate in silos. For example, narrowly scoped models or single-case dashboards. While these Data Products address specific business needs, their value is limited because they are disconnected from the broader ecosystem.
Business domains often start here, but staying in this quadrant suggests missed opportunities for compounding value. The goal should be to get these isolated products talking to each other.
(Many Connections, Moderate Value)
Here, Data products begin to form connections and interchange data. Products become shared resources across teams with connected interfaces, pipelines, or contracts. The network of formerly isolated data products starts taking shape, enabling cross-functional visibility.
While connected products deliver moderate value, they often lack the coordination and intentionality required to unlock high synergy. This is the launchpad for scalable data ecosystems.
(High Connections poised to reap the value of Network Effect)
Data products are primed for exponential growth in value. They are highly interconnected, and the groundwork for the network effect is laid. At this stage, teams might be experimenting with integrations and aligning metrics, but haven’t yet harnessed the multiplier effect.
(High Connections, High Value)
This is the hotspot of the amplification matrix, where interconnectedness leads to compounding/exponential returns. Data products become the lifeblood of decision-making, driving personalisation and real-time optimisation.
At this stage, data products amplify each other’s value, creating a self-sustaining feedback loop. Achieving this requires robust data platforms, clear product ownership, and a product mindset that views data as a strategic business asset.
Most organisations aim for better dashboards because they assume value emerges at the edge. But the real goal is reaching the top-right quadrant.
A funnel is a mechanism for refining intent, shaping structure, and accelerating action. Most organisations treat data as a one-directional flow, but high-performing systems treat it as a continuous feedback engine.
Users aren’t the last step in the chain, but the first constraint that defines what the system must create. Their questions determine the models you need, their decisions determine the data you must surface, and their context determines the interfaces you must design. When users shift from endpoints to first principles, the entire system becomes demand-driven instead of supply-driven.
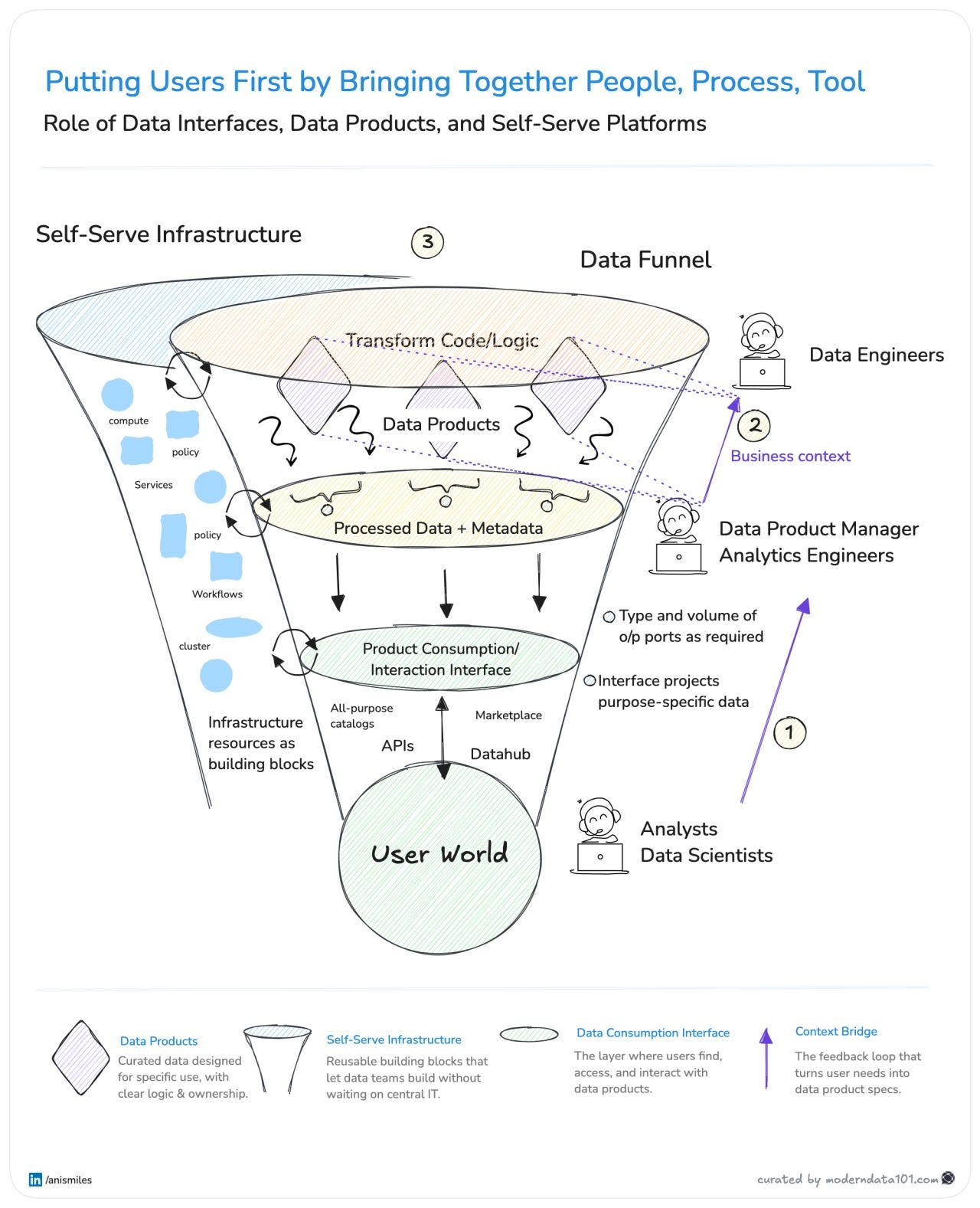
Supplying context across personas, teams, and the data funnel: turning user needs into data product specs.
Converts user needs → product specifications → a lineage of purpose across personas.
This is where intent is manufactured, because clarity about “why” becomes the upstream force that shapes every downstream decision.
Converts raw data to governed, high-quality data products. This is where structure is developed, because meaning requires constraints before it can be trusted or reused.
Supplying resources like workflows, compute, services, policy, etc., to keep context and data flowing. This is where speed kicks in, because teams move fastest when infrastructure becomes composable.
Converts platform capabilities → reusable, frictionless building blocks.
[related-1]
Together, these funnels create three layers of intelligence: intentional intelligence, structural intelligence, and operational intelligence.
Systems compound only when intent, structure, and speed reinforce one another. I’ll call it the echo effect. When intent guides structure, structure reduces friction, and frictionless platforms accelerate iteration, you get a positive feedback loop where every improvement strengthens the entire network.
This alignment reshapes data roles:
This is the exact leverage point where the Data Network Flywheel begins to spin through a system designed to learn from its own interactions.
Local quality checks protect the integrity of a single data product, but they do nothing to guarantee the integrity of the system it participates in.
Data product boundaries define where schema, freshness, and validity checks naturally belong, but those checks stop at the edge of the product. Analysts reading dashboards still depend on DP-specific observability, but their insights are only as trustworthy as the weakest upstream domain.
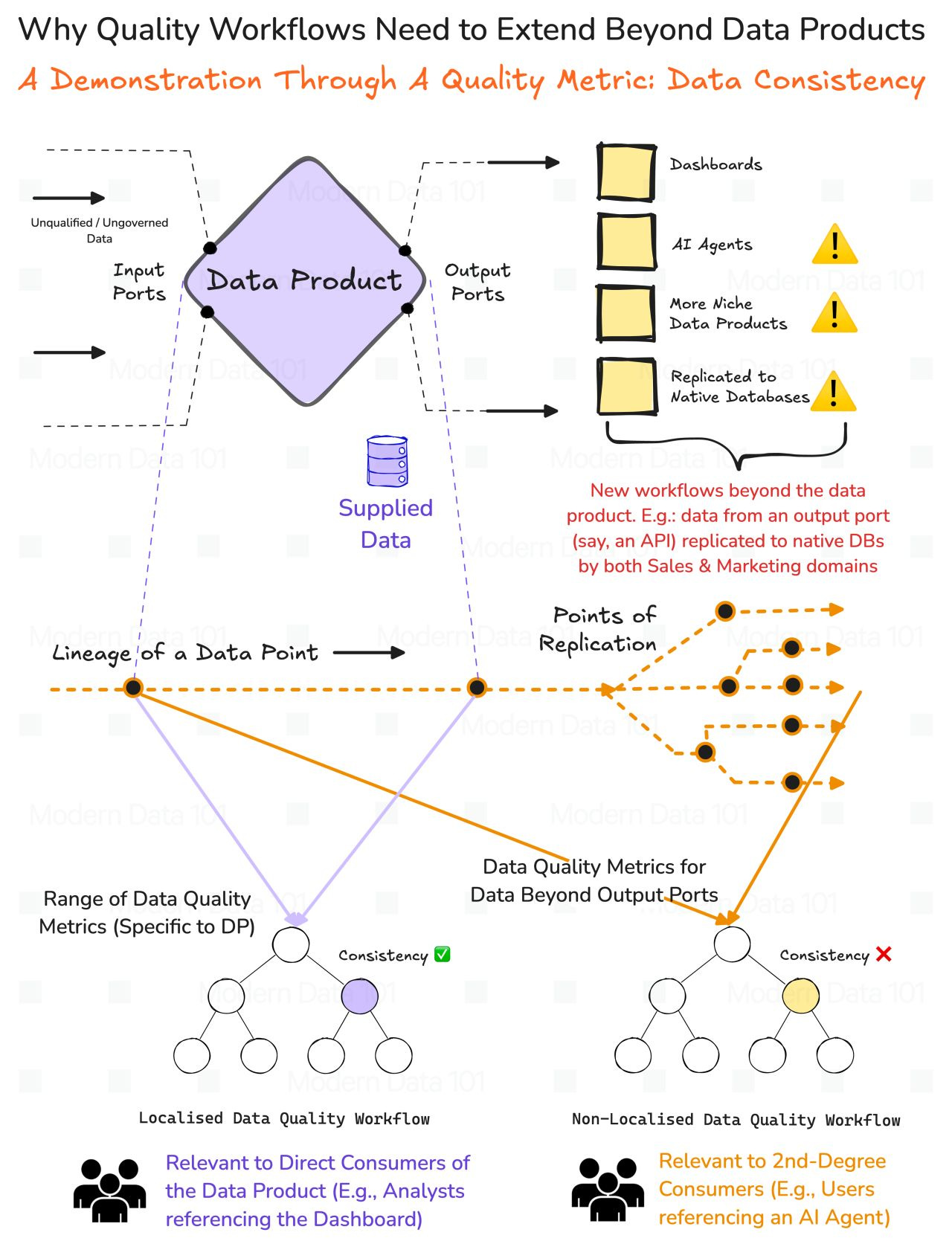
Once an AI agent consumes a data product, the system stops behaving linearly. Agents replicate data, remix it, and distribute it across new decision surfaces, multiplying both value and risk.
A single local anomaly becomes a global inconsistency because agents don’t just read data; they propagate it. This is the moment when quality breaks out of the product boundary and becomes a network-wide obligation.
If data is replicated across agents, stores, and downstream workflows, then quality cannot remain a local contract. A distributed network produces distributed failure modes, and only a distributed quality system can contain them.
Fundamentally, quality must inherit the topology of the data network, or the network collapses under its own interconnections.
Global Quality Workflows elevate quality from a per-dataset check to a system-wide trust protocol. They observe data across products, domains, agents, and replicas, not within isolated silos.
They convert lineage from a static documentation artefact into a dynamic assurance layer that continuously reconciles reality with intent. This enables consistency checks that operate at the system level, catching cross-domain drift long before it becomes an AI-level failure.
These value, speed, and trust enablers overlap their lifecycles, which intensify one another when designed as part of a single data operating system.
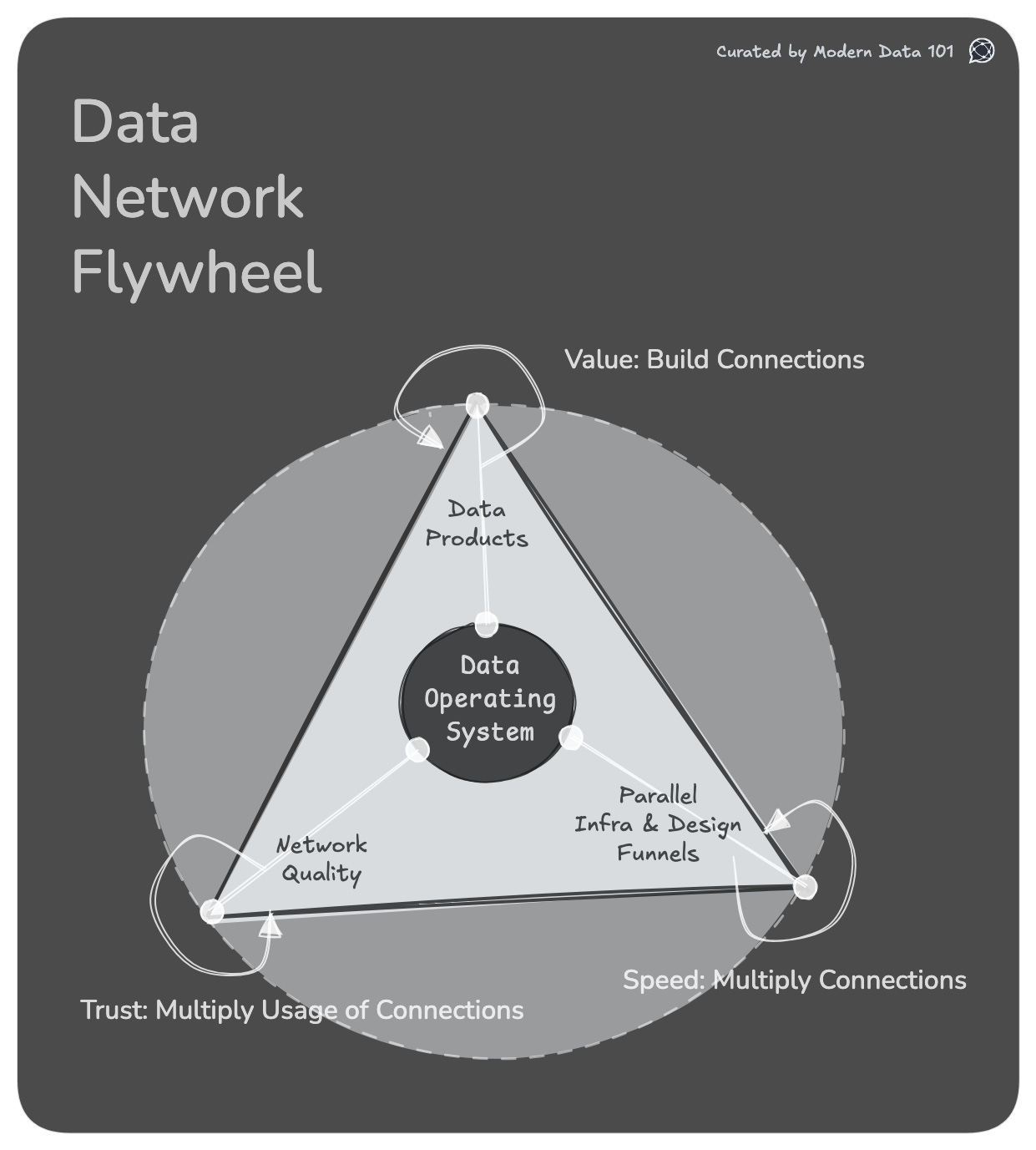
Connections between data products generate new analytical surface area, and each new interaction increases the system’s ability to answer, predict, and automate. A larger network produces more synergy, and more synergy produces exponential lift, but only if the rest of the system can keep pace.
Reusable infrastructure shortens the distance between intent and output. Faster iteration produces more data products, and more products create more nodes for the network to attach itself to. Speed multiplies value because speed multiplies connections.
Cross-domain, cross-agent, cross-replica assurance turns a fragile graph into a reliable network. Trust enables safe reuse, and safe reuse increases consumption, which illuminates system-wide insights that further strengthen trust. Trust multiplies value because trust multiplies usage.
Together, These Loops Form a Single Flywheel
Speed creates products, products create connections, connections create network effects, network effects create consumption, consumption creates quality insight, quality insight creates trust. Trust brings more users, and more users bring more context, better specs, and better products.
More Users → More Context → Better Specs → Better Products → More Connections → Larger Network Effects → More Consumption → More Global Quality Insights → More Trust → More Users
This data system learns itself: accelerating every time a human or an agent touches it.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡

Find me on LinkedIn 🙌🏻
From MD101 team 🧡
With our latest 10,000 subscribers milestone, we opened up The Modern Data Masterclass for all to tune in and find countless insights from top data experts in the field. We are extremely appreciative of the time and effort they’ve dedicatedly shared with us to make this happen for the data community.

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




