


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)




TABLE OF CONTENT



This is Part 2.1 of a Series on FAANG data infrastructures. In this series, we’ll be breaking down state-of-the-art designs, processes, and cultures that FAANG or similar technology-first organisations have developed over decades. And in doing so, we’ll uncover why enterprises desire such infrastructures, whether such aspirations are feasible, and identify state-of-the-art business outcomes that may or may not need decades of infrastructure mastery.
Subscribe to be the first to be notified when the next part drops!
Optional: Read Part 1 first 👇🏻
Why You’ll Never Have a FAANG Data Infrastructure and That’s the Point | Part 1
TRAVIS THOMPSON
Part 2.1
To be continued in Part 2.2
Design Philosophy: Obsessive Organising
The foundational idea and the superpower of Facebook engineering is the obsessive organising undertaken by their data stack at scale. If most enterprises run data kitchens that are functional but messy, Meta runs one that’s “MONICA CLEAN.” Meta’s primary business IS data, and it understands its entire data ecosystem of billions of users and infinite transactions so well by the simple act of scaling largely simple organising tactics.
Meta doesn’t just collect, process, and store data like most enterprises do. It categorises, annotates, and controls from the first point of entry. Every byte that enters the system is tagged, labelled with a purpose, and attached to a lineage flow. Every ingredient is stored, labelled, and cross-referenced. Privacy, compliance, and governance are emergent properties of this organisational mindset.

The obsession is operational, where no raw field flows unlabelled, no dataset exists without a schema, and no request moves without purpose. It’s a system-level habit of hygiene instead of a one-time cleanup. But how does such an extensive data system achieve this goal?
Understanding is about context, meaning, semantics. Meta ensures these are injected from the first touchpoint, and the context keeps building up as data passes through subsequent marks and feedback loops.
The insight is simple but hardly practised by non-data-first orgs: clarity compounds. The earlier you name, structure, and annotate information, the cheaper it becomes to manage, govern, and understand it downstream.
Facebook’s position as a data overlord depends on ordinary discipline performed at an extraordinary scale.
As we stressed in the first part of this series,
FAANG’s advantage wasn’t tools, but design philosophies. FAANG designed better systems of abstraction instead of better tools.
The stress was never on how to perfect a data architecture, but how to imbibe the organisation’s chosen design philosophy to the last atom: from how data flowed between teams and how it bridged Revenue goals to how data cultures evolved and how employees shared notes.
FAANGs are extremely fast-moving bodies and systems. To the point they do not wait for technology to catch up to their design principles, and go on to literally invent technology and systems that establish their vision.
Therefore, comparing your enterprise architectures to the Meta-state is a pointless and rather expensive errand. For their state keeps changing to align their philosophy with the dynamic state of data and people.
We embarked on the journey of understanding data across Meta a decade ago with millions of assets in scope ranging from structured and unstructured, processed by millions of flows across many of the Meta App offerings. Over the past 10 years, Meta has cataloged millions of data assets and is classifying them daily, supporting numerous privacy initiatives across our product groups. ~ Facebook Engineering
So first, we’ll talk about their design choices or patterns and then look at architectural components that currently establish them.
Organising type: Immediate labelling. Everything has a place and name in their world.
Pattern: annotate assets as early as possible (API, schema, ingestion point) so purpose is explicit at source. Early annotations make later flow checks cheap and reliable. This is explicitly called out as a design priority by Meta's engineering blog.
📝 Related Read:
The currency of purpose in the age of AI
Organising type: Continuous checks on alignment
Pattern: instead of scattered “point checks” in code, they use an IFC model (Policy Zones) that tracks annotations and evaluates flows continuously. This reduces brittleness and maintenance overhead.
Organising type: Iterative Validation and Checks
Identify assets → Discover flows (lineage) → Remediate (annotate/block/reclassify) → Monitor & iterate → Enforce (flip logging→enforcement).
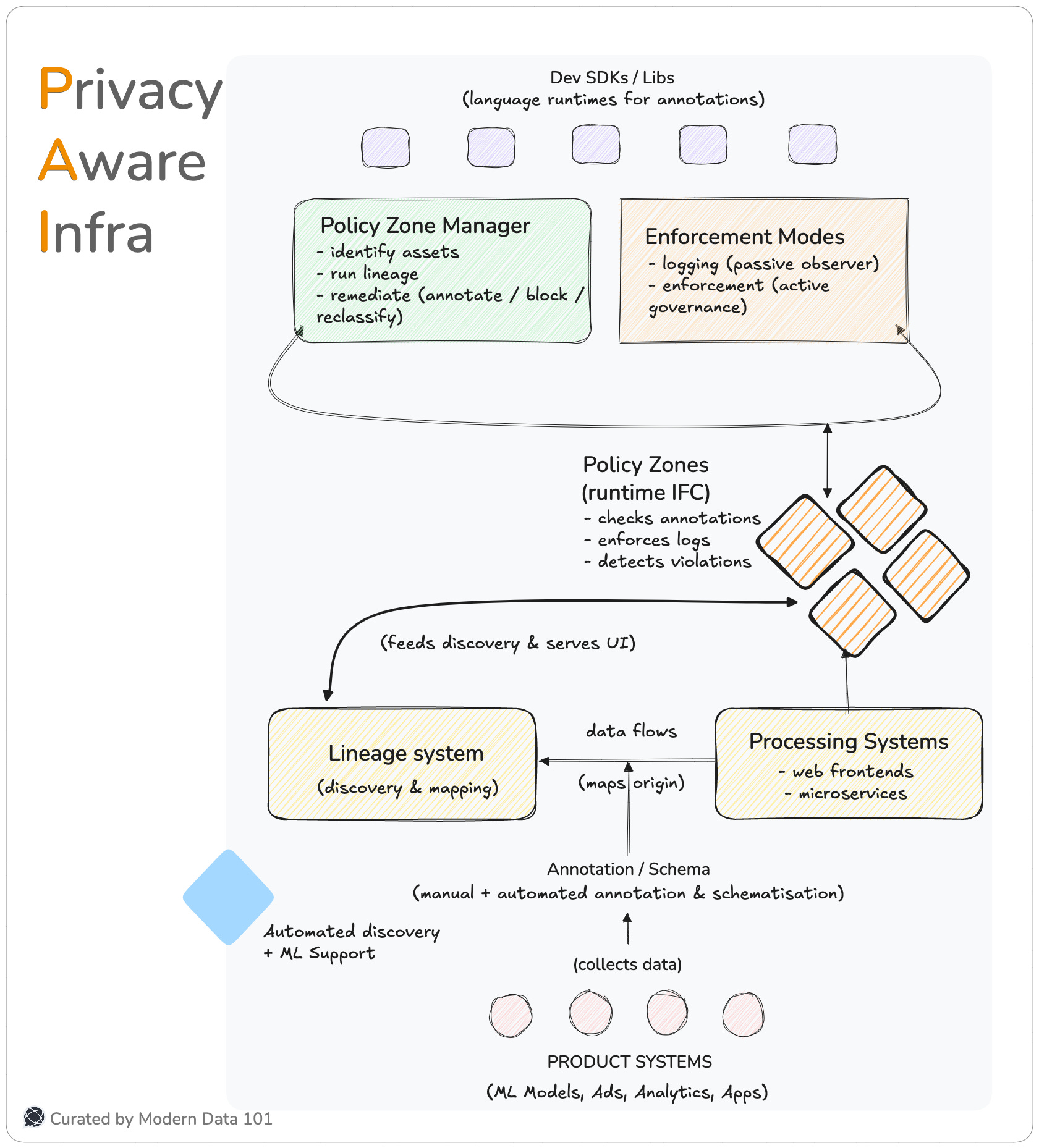
Meta’s Privacy Aware Infrastructure is the architectural superset that embeds privacy primitives directly into the platform. PAI is the platform-level set of primitives that enable privacy-first product development. At its core, PAI operationalises a belief that most enterprises only articulate aspirationally:
We believe that privacy drives product innovation.
In other words, governance isn’t a brake, but the steering system. PAI reframes privacy from a constraint into a creative enabler because when data is annotated, structured, and bounded by purpose, engineers innovate faster with fewer downstream risks. It turns the act of “doing the right thing” into a built-in function call.
Essentially, what Meta is saying is that governance is the foundational technology, and everything else is born from a governance-first infrastructure. While in most legacy or enterprise infrastructures, governance is infuriatingly treated as a good-to-have. Perhaps not officially, but the way these systems function and countless reviews of their data citizens demonstrate that governance is an add-on or after-the-fact strategy that only plays catch-up.
It’s introduced reactively, after products exist and data has already sprawled. It’s managed through policies, consultants, and control layers instead of primitives, schemas, and SDKs. The result is an architecture that governs by inspection, not by design, constantly trying to retrofit order into entropy.
PAI solves this by flipping the sequence: governance is not an overlay on data; it is the material from which data infrastructure is constructed. That shift from afterthought to atomic property is what gives Meta its structural advantage. Every privacy zone, every annotation, every access control inherits this foundational principle.
A runtime information-flow control (IFC) mechanism that enforces purpose limitationby attaching intent/purpose annotations and creating enforcement “zones” around code/data flows. It replaces brittle point-checks with continuous flow enforcement.
If you’ve been a Modern Data 101 reader, you would easily relate this to the Data Products construct, which are purpose-specific boundaries built with a purpose-first mindset, embedded with governance and contracts from the product design stage all the way to product evolution.
If you really think about it, data products are essentially a superset of data governance, tackling similar problems (discoverability, addressability, understandability, accessibility, trustworthiness, & security) with the additional product counterpart of purpose-driven data, value, interoperability, and reproducibility. This makes data governance one of the key pieces for establishing any redeemable effort in the data product arena. ~ Animesh Kumar

[related-1]
[related-2]
At Meta, every piece of data is born with a story, a clear purpose, a label, and a boundary. Every data unit plays a role in the “larger scheme of things.” This is how Meta has mastered social networks, AI, advertisements, and data productisation. The act of data annotation or schematisation is how that story is written. It’s the process of tagging assets with metadata labels that encode their intended purpose.
This is the foundation on which Policy Zones operate: the runtime enforcement system that continuously evaluates how data is used, ensuring every flow aligns with its declared intent.
The annotation itself becomes the unit of truth; Policy Zones simply read and act upon it.
Instead of scattering “if-else” privacy checks across millions of code paths, Meta’s engineers annotate once and enforce everywhere.
By codifying purpose early or labelling a part of it, Meta eliminates ambiguity later. Downstream systems no longer need to guess what a field means or whether it can be used in a particular model or feature, the schema itself carries that intelligence forward.
Data annotation is the grammar of Meta’s governance language. Every label forms a semantic bridge which allows Policy Zones to act as interpreters, ensuring that every operation, from data ingestion to model training, happens within clearly defined purpose boundaries. Meta’s approach is proof that annotation is a design rather than simply documentation.
[related-3]
In a traditional enterprise, lineage is often a sidecar project: an afterthought built through manual mapping or BI tool integrations. At Meta, it is a first-class citizen in the data ecosystem. Lineage isn’t discovered once, but continuously and obsessively inferred, updated, and verified through automated analysis.
This is what enables Policy Zones and the Privacy Aware Infrastructure (PAI) to function intelligently. When annotations (purpose labels) are paired with lineage (flow visibility), Meta gains a real-time understanding of whether data is flowing in accordance with its declared intent. Lineage transforms annotation from a static declaration into an enforceable dynamic rule.
Consequently, the system can automatically detect violations. For example, when a piece of data flows into an application or model that is not intended to use it, prompt remediation kicks in before any policy breach occurs.
Lineage also fuels Meta’s feedback loop of remediation and refinement. When violations are detected, requirement owners can trace them back to the exact point of deviation, apply one of three actions (annotate, block, reclassify), and instantly see how the fix propagates downstream. This makes governance iterative.
It’s how the organisation answers one of the hardest questions in data systems: “Where exactly does this go?” Once you can answer that, you can trust what comes out.
[related-4]
At scale, purpose enforcement cannot exist in code alone. It needs a governance layer where policy owners, privacy engineers, and data stewards can see, understand, and acton what’s happening across millions of data interactions. That’s what the PZM provides: a unified UX and tooling environment that operationalises Policy Zones into real-world workflows.
Through the PZM, requirement owners can:
It effectively bundles the human lifecycle around Policy Zones: discovery, validation, remediation, and activation.
[related-5]
In a way, PZM is a governance orchestration layer. It brings together engineering, compliance, and product teams into one workflow, turning static rules into adaptive, observable controls.
Just as Meta’s data annotation acts as the grammar of governance, the PZM acts as its editor’s console where intent is drafted, reviewed, and finally enforced in production.
When a Policy Zone detects that data is flowing in ways misaligned with its declared purpose, the next question becomes: what should happen now?
At Meta’s scale, where billions of data flows occur every second, traditional “stop everything and investigate” responses would paralyse operations. Instead, Meta designed a set of canonical remediation actions: structured responses that balance enforcement with business continuity. These actions allow systems (and humans) to correct or contain violations with precision.
The three foundational remediation options are:
📝 Related Read:
What is Defensive Design & What is the Best Defence?
[related-6]
Together, these three actions form the core grammar of remediation: annotate, block, reclassify. They represent the vocabulary through which Policy Zones and the Policy Zone Manager (PZM) maintain continuous alignment between declared purpose and actual behaviour.
In essence, each action ensures that the story written through data annotations stays consistent as it travels through pipelines, APIs, and models.
Write it in stone: developers are the ones who’d make or break your envisioned data architecture. PAI understands that the most elegant governance model fails if it slows developers down. Meta grasped early that privacy enforcement cannot live as a separate bureaucracy and must be a developer primitive. That’s why they built lightweight language and runtime SDKs: compact, high-performance libraries that make annotation, enforcement, and privacy validation native to everyday engineering.
At Meta’s scale, where millions of lines of code evolve daily, introducing governance through “external” tooling would have been self-defeating.
Instead, Meta chose to meet engineers where they are: in the language, framework, and runtime they already use. These SDKs embed privacy and governance constructs directly into the developer workflow, reducing the friction between writing code and writing compliant code.
The language primitives expose intuitive in-line functions and decorators to annotate data, declare purpose, and define boundary checks. Developers don’t have to think in terms of policies or compliance documents, they simply express intent as code. Meanwhile, the runtime primitives ensure those annotations are efficiently propagated and evaluated without bloating computational cost.
Meta calls this the “lessons from the trenches”: engineering privacy into the system through tools that engineers actually enjoy using. Each SDK is optimised for speed, stability, and minimal boilerplate, proving that governance and developer velocity don’t have to be trade-offs.
At Meta’s scale, manual discovery of data assets is impossible. Billions of records, millions of code commits, and countless microservices make human curation an impractical dream. Meta’s solution is automated discovery powered by machine learning and static analysis.
Instead of waiting for engineers to “declare” where sensitive or purpose-specific data exists, Meta’s systems learn and infer it. These systems parse huge repositories to detect data flows. Meanwhile, ML classifiers identify patterns that hint at privacy-relevant behaviour: function names, parameter types, schema references, or even subtle correlations in code usage that might suggest data of interest.
This automated discovery engine builds a semantic understanding of how that data behaves across the ecosystem. By continuously scanning codebases, it identifies candidate assets and code spots that might require annotation, review, or enforcement. What used to take weeks of manual audit can now happen in minutes and at a scale that only automation can sustain.
📝 Related Read:
The Semantic Spine
The genius of Meta’s approach lies in turning ML inward. “Eating your own dog food.” Not just using it for products, but for governing the data those products depend on. Machine learning acts as a mirror for the organisation’s own complexity, helping the platform see itself in real time.
Meta’s use of automated discovery and ML is the nervous system of its privacy-aware architecture.
.
References (other than those mentioned within the article)
[1] [2] [3] [4] [5] [6] [7] [8] [9] [10]
To be continued in Part 2.2
1. Areas of mismatch: How legacy or enterprise data architectures fall short of Meta’s Privacy Aware Infrastructure
2.Inspiring Meta’s business-aligned outcomes instead of trying to replicate their state-of-the-art data architectures that have been chiselled for decades
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Unlock the secrets of the Data and AI Stack: Take Our 10-minute Survey and Gain Exclusive Access to Survey Insights and an expert-certified Enterprise AI Playbook drafted in collaboration with seasoned Data & AI Leaders, Strategists, and Consultants, and by the authors of the recognised Data Product Playbook with over 3000 adopters.
In our 1st edition of The Modern Data Survey, 230+ data leaders and practitioners participated to enable rich insights that have shaped the community in countless ways since. Join the 2nd edition to contribute your ideas to The Modern Data Report, 2025-26!

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


