


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

%20(1).png)
.png)

.png)
TABLE OF CONTENT




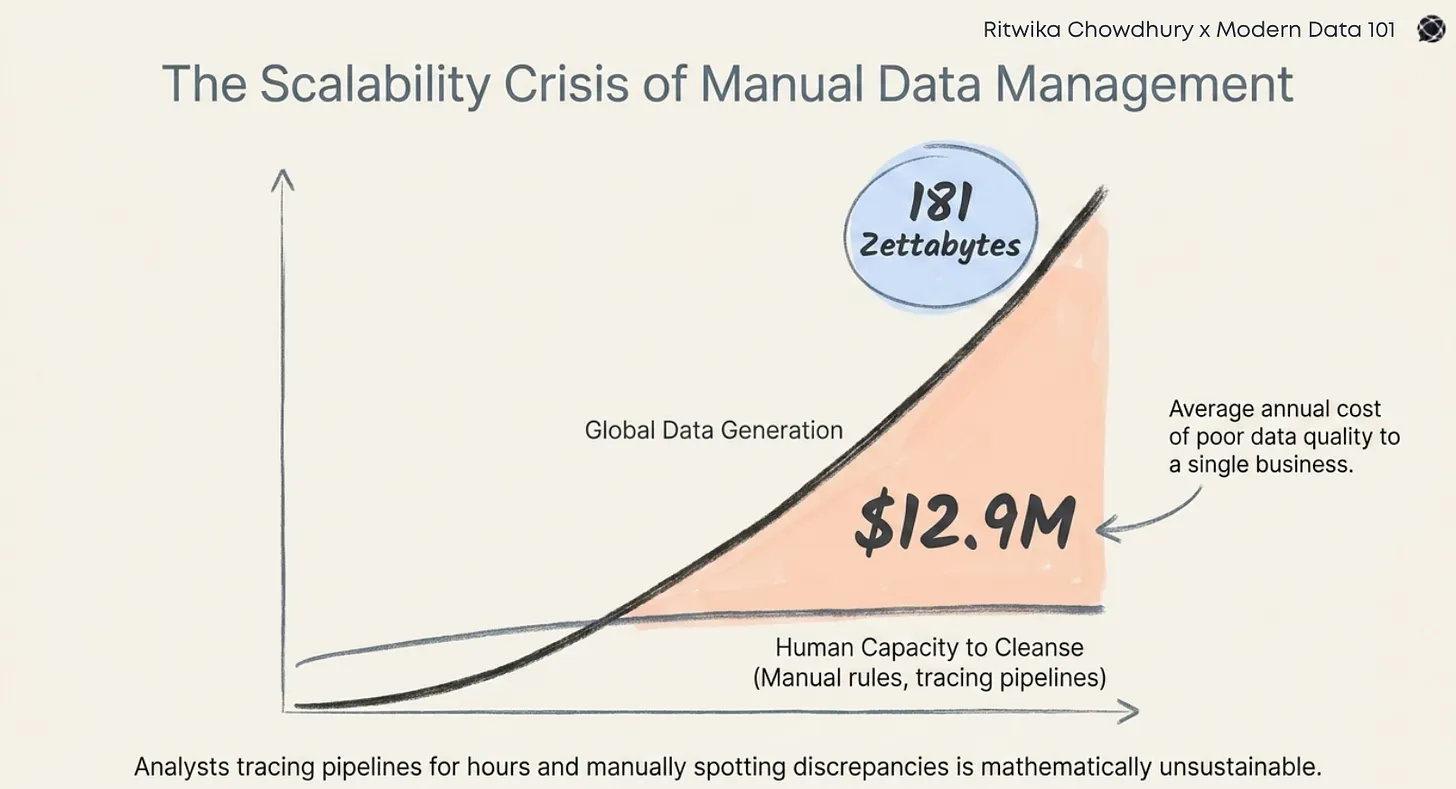
Let’s visualise data like water coursing through the pipes of a skyscraper. At first glance, it flows predictably: up from the source, out through the taps. But buildings evolve. Fixtures change. Floors are repurposed. And over time, leaks emerge in the most unexpected corners.
Water water everywhere, but not a drop to drink.
Now, consider how the taps are no longer just simple fixtures. They're espresso machines on the 15th floor café, fire sprinklers in the car parking, climate-controlled showers in the penthouse. These are your data products: specialised, context-aware outputs designed for very specific use cases. Sales forecast dashboards, Customer segmentation models, Risk scoring APIs. Each one built to serve a user, a workflow, a decision.
But the more tailored the endpoint, the more sensitive it becomes to what flows into it. A subtle change upstream, such as renaming a column, dropping a field, or delaying a sync, can wreak havoc downstream. The espresso now tastes off. The sprinkler doesn't trigger at a critical hour. The shower is cold. And no one knows why.
This is where lineage steps in. Not just to track water pipelines and flow, but to make sense of consequences. It’s the architectural blueprint that lets you trace every pipe, every valve, every transformation. When a leak forms (or worse, a product breaks), lineage doesn’t just help you find the fault; it helps you restore trust.
Alongside observability, you need accountability. And modern data lineage gives you both.
Ask any data leader what keeps them up at night, and the answers will sound familiar: trust in data, quality issues, constant firefighting, broken dashboards somehow right before board meetings, delayed insights, and teams not speaking the same language.
But peel the layers a little deeper, and you’ll find a common thread running beneath it all. Lack of visibility into how data actually flows, evolves, and impacts the business.
That’s lineage.
Not the tool. Not the pretty graphs. But the underlying capability to understand the lifecycle of data as a living, breathing asset: an ally of the data strategy.
Ironically, for something so foundational, lineage is often treated like an afterthought. A checkbox on a platform slide or a footnote under metadata features. It's hardly ever called out in strategy decks or roadmap reviews.
But big picture, lineage is not a nice-to-have. Not anymore at least. It is a strategic enabler. Without lineage,
Lineage sits at the intersection of trust, governance, collaboration, and speed. It is the nervous system of your data organisation. And like any nervous system, it doesn’t get much attention until something goes numb or starts to hurt.
We are not waiting for symptoms anymore. Enter Proactive Lineage. But to understand proactive lineage strategy, let’s address the gap in traditional lineage.
At some point in your data journey, you’ve likely opened a lineage graph and felt more confused than enlightened. And that’s not your or any user’s fault.
That’s the unfortunate truth of lineage in most traditional architectures. It shows you what changed, but not why. It reveals transformation after transformation but hides intent. You see the flow of data, not the story behind it.
Historically, lineage was treated as a technical trace, like a byproduct of pipelines and jobs running in production. And in simpler times, maybe that was enough. When pipelines were fewer, teams were smaller, and one BI dashboard answered most of your business questions. Pipeline-first lineage just made sense.
But the data world has rapidly changed.
Today, the modern data landscape is a dynamic, multi-team, multi-tool ecosystem where changes are constant and stakeholders span from backend engineers to boardroom execs. Static lineage snapshots, often generated during CI runs or scraped from metadata catalogs, fail to keep up. They may capture the movement of data across layers, but they rarely carry the context to explain why those movements exist in the first place.
Worse, the ownership of these flows is fragmented. One team builds ingestion, another manages transformation, a third owns reporting, and somewhere in the middle, someone changes a model definition without alerting downstream users.
Lineage, therefore, looks like data chaos disguised as order.
Lineage exists, yes. But it’s blind. It doesn't understand meaning. It doesn’t surface intent. It doesn't tell you who to call when things break.
But we are moving quickly towards AI-native systems, rapid experimentation, and composable data architectures. What data lineage strategy plays out in this environment?
Data Products introduce a fundamental pivot.
In the traditional centralised setup, lineage is an artefact of pipelines: side effects of DAGs, scripts, and ETL jobs stitched together with implicit logic. It’s often buried in version control or reconstructed post-facto by tracing broken reports upstream.
But when you start organising your data as products. Intentional, modular, accountable units — lineage stops being accidental. It becomes designed. Each product becomes a boundary. Each boundary defines a contract.
Suddenly, lineage isn't a chase across a warehouse but a series of well-lit, connected rooms.
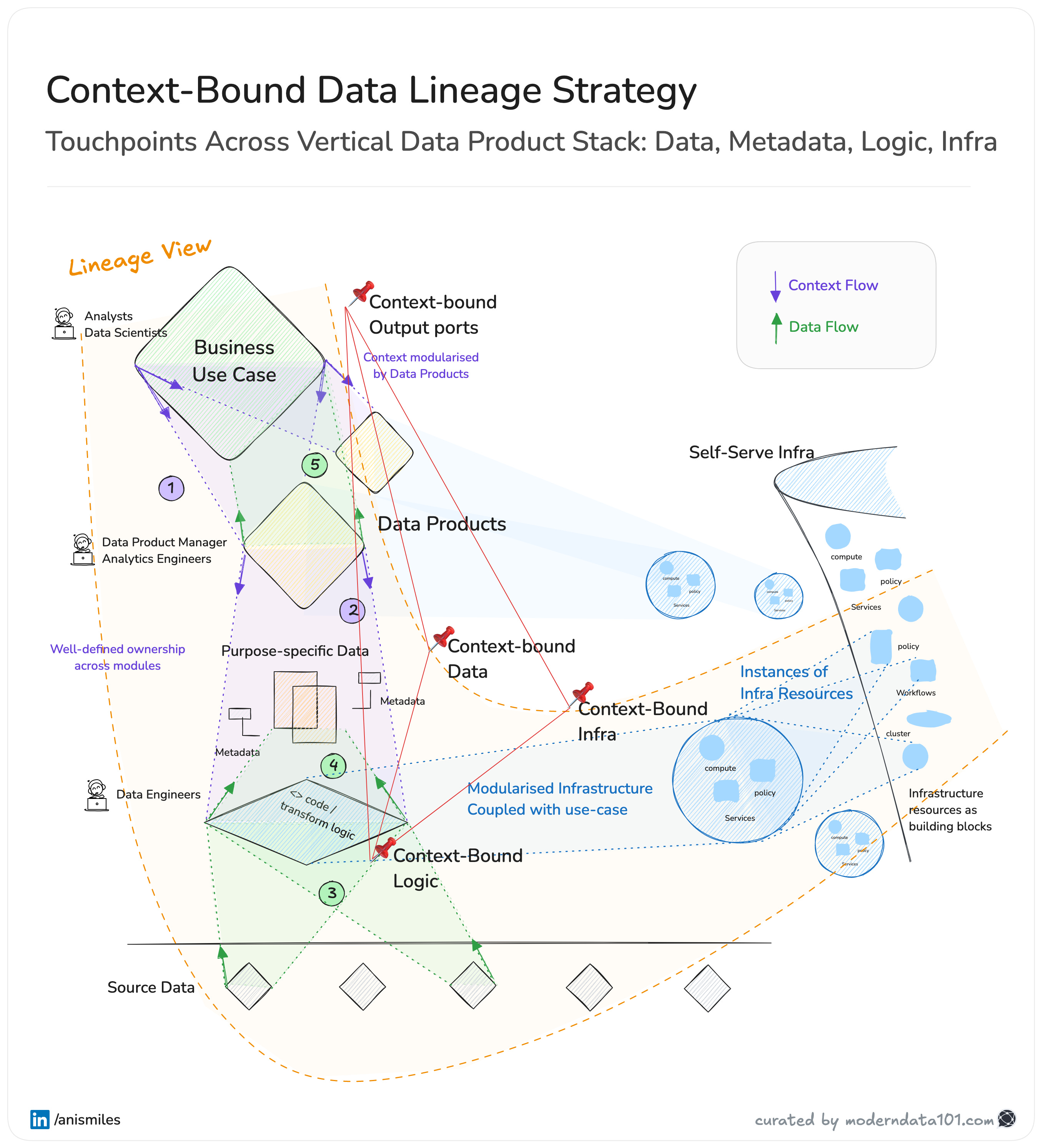
Let’s understand how Data Lineage becomes more actionable and proactive through vertical coupling across use-case-specific data products.
Before Data Products
The lineage view is often a mess. Pipelines sprawling like spaghetti, maintained by no one, owned by everyone, and understood by few. When something breaks, your best hope is tribal knowledge and Slack archaeology. There’s no clear boundary between domains, no contract, and certainly no accountability.
This isn’t just a technical debt problem. It’s a visibility problem. And a trust problem.
With Data Products
Each unit of the data stack is reimagined as a modular data product with explicit input/output interfaces and a clear owner. It’s not just "tables feeding tables." It’s:
Observe the lineage view in the diagram: You’re no longer tracing from a broken dashboard back to a random SQL job.
You're tracing from a business use case → through a data product → to well-scoped logic, data, and infra modules, with each step carrying context and custodianship.
This clarity turns lineage from a debugging tool into an operational asset for compliance, for scaling teams, and for building trust in data across the org.
Before Data Products
Lineage tools could show you where data came from but not why it mattered. Sure, you could trace table_x back to job_y.sql, but you’d be left guessing What’s this for? Who owns it? What happens if I change it? Is it still in use?
Metadata lived in silos (or worse, in someone’s head). Business meaning was detached from pipeline mechanics. This made audits brittle, onboarding slow, and context expensive.
With Data Products
Now zoom into the diagram: every data product is embedded with context-bound metadata, flowing alongside data and logic, not as an afterthought, but as a first-class citizen.
Each data product is:
This changes lineage from a low-level asset to a business-readable map.
You don’t just see "data flows from A to B." You see: “Customer Segments (v2.1) enriched with LTV estimates from Customer 360, refreshed hourly, owned by the Growth Analytics team.”
Metadata is no longer just structural, it’s narrative. It tells the story of data in motion: why it exists, who it serves, and what depends on it.
This is the shift: from column-level lineage to context-level lineage. A system that’s legible to humans, auditable by design, and deeply integrated with how teams build, monitor, and trust their data.
📝 Related Read(s)
Semantics and Data Product Enablement - A Practitioner's Secret | Frances O'Rafferty
Before Data Products
A change in one pipeline often broke five others. Logic, data, infra all jumbled and leaking across pipelines, bound together in duct-taped SQL scripts.
Lineage tools could map these webs, but what you got was noise:
With Data Products
Enter modularity, driven by purpose. In the diagram, you’ll notice how the architecture is layered:
This enables a composable lineage map where each unit is meaningful and reusable.
Instead of “job_x writes to table_y,” you now trace: “Marketing Funnel” product → “Ad Spend Attribution” → “Campaign ROI Report”
For context on possibilities, with modularity in place, you can significantly advance the granularity of ROI calculations. Each use case would be able to attribute spend across data products and pipelines as well as deep-set infrastructure resources.
Modularity also enables reuse. The same “Customer Segments” logic can serve both CRM optimisation and campaign targeting. Each product has defined boundaries.
📝 Related Read(s)
The Power Combo of AI Agents and the Modular Data Stack: AI that Reasons
Before Data Products
Adjust LTV logic? You brace for Slack alerts from four different teams. Lineage tools gave technical traces, but they stopped at SQL steps or dbt models. You could see what might break, but not what matters. No clear way to ask:
“If I redefine Customer Segments, which metrics and dashboards are at risk?”
With Data Products
Now the unit of change is the data product, not just a table or model. Each product is modular, well-scoped, and most importantly, contextual.
In the image:
So now, when we ask: “If we tweak how Lifetime Value is computed…”, you get a lineage view that shows not just technical dependencies but business impact. Downstream products like “Customer 360” and “Segment Health Report” are flagged. Dashboards and stakeholders relying on those outputs are visible. You can run impact analysis as a conversation.
No more guesswork when editing dbt models. Impact is scoped at the product level, with metadata, owners, and SLAs baked in. That’s the power of product-oriented lineage:
Alongside data flow, you understand the business chain reaction.
Before Data Products
Lineage lived in silos. Analytics Engineers had their dbt docs. Data Engineers had Airflow graphs. Business teams? A Notion doc and hope.
And then there were tussles between domains. Teams within consulting didn’t understand marketing semantics that brought in prospects (opportunity lost: delivery-expectation match), marketing didn’t understand how sales interacted with their data (opportunity lost: reduction in conversion TAT).
Each team spoke its own dialect of lineage. When something broke or needed to be reused, nobody had the full map. Lineage didn’t travel across domains but stopped at team boundaries.
With Data Products
Enter context-bound lineage. Team-agnostic by design, visible by default. As in the illustration:
This is how you break the silo loop:
Instead of “my pipeline” and “your dashboard,” it’s “our product.”
With shared ownership, shared metadata, and shared lineage context.
So now when Marketing needs “Customer Segments,” and Finance wants to reuse “LTV definitions,” and Engineering needs to scale infra to support both, they all see the same product lineage, enriched with business context. That’s what makes this data lineage strategy not just cross-functional, but context-aligned.
AI-native refers to organisations, systems, or architectures that are built with AI as a foundational capability, not as an afterthought. In an AI-native company, machine learning models, LLMs, and intelligent agents are deeply embedded into core workflows, products, and decision-making.
In such an organisation, data is no longer consumed in raw form. AI models ingest refined signals, business-defined metrics, and compound features from dozens of sources. A model predicting churn isn’t reading “user_id”; it’s parsing layers of meaning like “active engagement score,” “last touch attribution,” or “risk tier.”
This makes the lineage problem exponentially more critical and more complex.
When a pipeline changes the definition of “active user” without clear lineage, the cost is now more than technical debt. It’s poor model performance, unexplainable decisions, compliance risk, and lost trust. Lineage here serves strategic purposes:
In an AI-native stack, lineage is the system of record for how intelligence is created, shared, and trusted. ML is as good as the data you feed. AI is as good as the intelligence you feed it.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡

The Modern Data Survey Report is dropping soon; join the waitlist here.

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



