


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT




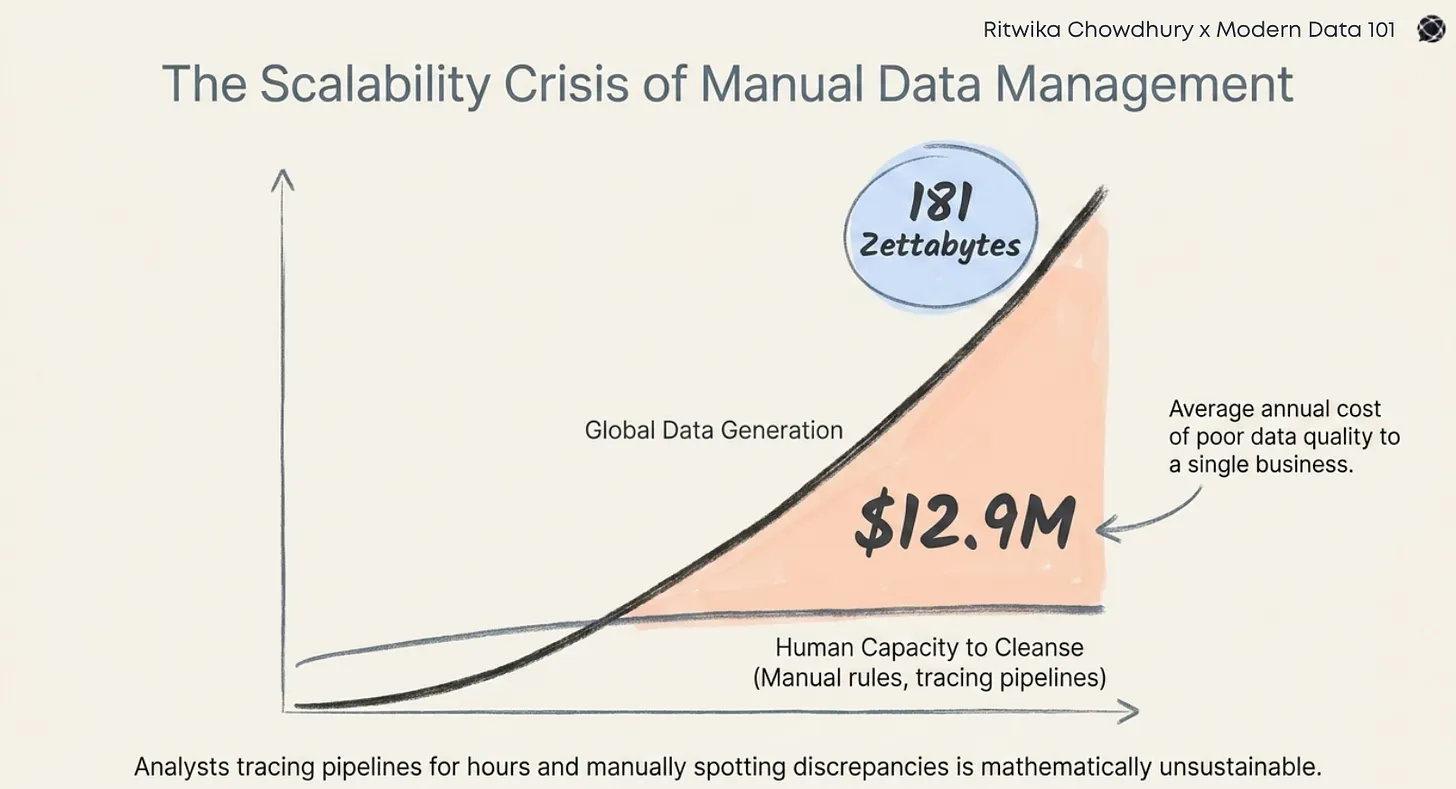
You are neck-deep in building the next generation of AI applications like intelligent chatbots, hyper-personalised recommendation engines, sophisticated RAG systems. You have invested in the LLMs, data pipelines, and the ambition. But if your AI is still struggling to understand context, prone to confidently making things up (we like to call them "hallucinations," but let's be real, they are just wrong answers), or simply feels generic, you are hitting a very common wall. The problem is not always the AI model itself, it's often how your data is being managed and accessed for its meaning, not just its raw form.
A 2025 study revealed that open-source AI models hallucinated fake software packages at 4x the rate of commercial models, posing a big security risk for developers as a result.
Think of it this way: traditional databases were designed for neatly organised, structured facts, like a meticulously alphabetised library where you find books by their exact title, author, or ISBN. Perfectly logical for reporting! But AI, and especially GenAI is a different ballgame. It needs to find books by what they are about, understanding interconnected themes, even if the keywords don't match exactly.
[playbook]
It needs to understand the entire library's interconnected knowledge to provide smart, contextual answers. This shift is profound: from finding data directly by labels to looking for it by its meaning is powerful and is the reason why vector databases are not just a trendy new tool, they are quickly becoming "the fundamental backbone" for serious AI applications.
And that brings us to our core argument: vector databases are not just an add-on, but an inherent feature when building a data platform.
A vector database stores, manages and indexes high-dimensional vector data. Data points are stored as arrays of numbers called “vectors,” which are clustered based on similarity. This design enables low-latency queries, making it ideal for AI applications.- IBM
[related-1]
Now, that we have laid the foundation, let’s understand the five key reasons that make a vector database a non-negotiable for your AI development:
Remember how you interacted with data in the days gone by? SQL queries, dashboard clicks, and finally filtering based on exact matches. That's how it used to work for precise, structured queries.
But AI operates differently. It thrives on semantic search, natural language interfaces, and contextual recommendations. All of this fundamentally rely on vector embeddings. These are mathematical fingerprints that capture the essence of text, images, audio, and more.
Without a robust vector database, your AI-native applications can’t "think" in embeddings, which is now the native language of AI.
To put this into perspective, it is exactly like trying to have a deep conversation that is in a foreign language without a translator. You might pick up a few keywords, but all the subtle meanings and true context will fly right over your head.
If structured tables were the reliable workhorses powering your dashboards and traditional reports, then vector indexes are the sophisticated, context-aware brains behind Large Language Models (LLMs) and other AI systems, enabling them to understand what you mean, not just what you typed. It’s a seismic shift from keyword matching to meaning/context matching, and your data infrastructure needs to keep up.
Let's face it: LLMs are brilliant, but they can sometimes "hallucinate." Confidently making up facts that are not fact. (We have all had that employee who sounds super confident but is just guessing. LLMs can be like that, but on a grander scale!)
This is, understandably, not ideal when you are trying to make critical business decisions or provide accurate customer support. Enter Retrieval-Augmented Generation (RAG), which is rapidly becoming the go-to pattern for grounding LLMs in your own proprietary, up-to-date data. It's like giving your brilliant but occasionally imaginative AI assistant a comprehensive, fact-checked reference library that you control.
Here’s how RAG pulls off this magic: when you ask an LLM a question, RAG first performs a super-efficient semantic search against your internal knowledge base (think company documents, internal databases, even past customer interactions) to find relevant context. That context is then fed to the LLM, enabling it to generate a far more informed, accurate, and trustworthy answer.
This critical "retrieval" step absolutely hinges on efficient Vector similarity search.
Without robust vector stores, your LLMs remain generic and, frankly, untrustworthy for domain-specific applications. Imagine asking your internal company LLM about Q3 sales figures, and it confidently “invents” insights. Poof, there goes your accurate quarterly report!
Simply put: No vector store, no RAG. No RAG, no reliable, context-aware answers. It's the crucial difference between a general-purpose chatbot that might occasionally guess right, and a highly specialised, always-updated internal expert that speaks your company's truth with confidence.
Today, users don't just want personalised experiences; they simply expect it. Anything short of that is dismissed as a high-friction UX. They crave applications that adapt to them, remember past interactions, and anticipate their real-time needs. They are used to it.
Think of a chatbot remembering the nuances of your previous multi-turn conversation, or a streaming service offering truly user-specific recommendations that evolve with your tastes. Vector search is the secret sauce that enables this dynamic, real-time personalisation at scale.
Instead of relying on static rules or tags, vector databases store user preferences, interaction histories, and content signals as high-dimensional embeddings generated by machine learning models, allowing applications to retrieve semantically relevant results based on real-time user context.
When a user interacts with an application, their current context is also converted into an embedding, and the vector database instantly finds the most semantically similar items or past interactions.
This isn't just a "nice-to-have" anymore; it's fundamental to modern AI-native User Experience (UX) design. So if you want your app to feel less like a one-size-fits-all product and more like a mind reader, vectors are your ticket.
For a long, long time, our data models were built like rigid, meticulously organised filing cabinets: schemas, taxonomies, keywords. You would search for exact matches or navigate pre-defined categories.
Perfectly logical for ensuring data integrity and structured reporting. But AI apps are different. They demand a more fluid, context-rich understanding of data, where relevance isn't about an ID number or a specific tag, but about meaning.
Vector databases act as a sort of "semantic memory layer" for your data. They allow you to represent the meaning of data points as vectors, enabling more intuitive queries.
Instead of needing to know the exact phrase, you can ask "find documents about renewable energy" rather than just "find documents with the keyword 'solar panel'." This is a huge leap from simple joins on primary keys to retrieving information by semantic similarity. This enables building truly intelligent applications that can infer complex relationships and context, even when not explicitly defined.
Modern data developer platforms are evolving to be the nerve centre for the entire data lifecycle, from messy ingestion to clean transformation, and finally to intelligent serving and analysis. They’re increasingly designed to handle both structured and unstructured data. In this integrated ecosystem, Vector stores are the crucial layer that seamlessly bridges LLMs, APIs, and leading data products. Which isn’t the case for traditional data platforms: the AI foundation.
[related-2]
The current state is high context fragmentation across data and AI applications. In the existing landscape, many applications create their own isolated vector databases to meet specific goals. While this approach works in the short term, it builds up high inefficiencies and context debt over time.
A centralised, platform-wide vector database directly tackles the context fragmentation issues, ensuring cohesion between data/AI applications, customer interactions, operational systems, and both structured and unstructured insights.
Imagine one shared, ever-learning brain for all your apps. A shared repository ensures every app accesses and contributes to your business's collective knowledge. If your customer support app learns a new solution to a common problem, that learning can immediately inform your sales app's next interaction, compounding shared context across the entire enterprise. No more "didn't you tell me that already?" moments, which, let's be honest, can be quite frustrating to a customer.
Apps effortlessly integrate through a standard API, dramatically reducing friction when developing and deploying new context-dependent features and interfaces. This is a massive superpower for cross-domain applications to the likes of sales, business operations, and marketing, all inherently linked and now sharing a unified, consistent understanding.
Consolidating vector databases eliminates redundant infrastructure and workflows, significantly reducing resource usage and operational costs. Why run five separate databases, each costing time and money, when one robust, shared platform feature can serve them all? It's like switching from individual power generators for every light bulb to a single, efficient power grid. The wallet feels heavy.
Developers can easily extend and build upon the shared vector database for specific use cases, like hyper-personalised recommendations, sophisticated multi-turn conversations, or highly specialised RAG workflows, all while leveraging the powerful, centralised context. It empowers your teams to innovate without reinventing the wheel every single time.
From the moment data is ingested to its retrieval and subsequent inference by AI, vector databases are becoming the runtime context store for AI applications. They are not a feature you bolt on if you have extra budget; they are a core system primitive.
[data-expert]
This paradigm shift towards AI-native applications aim to fundamentally change how we manage and interact with data. Vector databases are no longer a niche, "bleeding edge" technology, they are rapidly becoming table stakes for any organisation serious about leveraging AI to drive innovation and gain a competitive edge.
By enabling semantic understanding, powering robust RAG architectures, facilitating dynamic personalisation, transforming traditional data modeling, and seamlessly integrating into modern data platforms, Vector databases are the foundational layer for the next generation of truly intelligent applications.
Embracing a centralised, platform-wide Vector database approach allows your teams to accelerate experiments with GenAI and RAG, deliver increasingly context-driven results, and foster unparalleled cross-application collaboration and contextual understanding. The future of AI is conversational, contextual, and deeply personalised.
Because AI doesn’t “look up”, it “understands.” Traditional databases operate on exact matches. But AI-native apps rely on semantic similarity, powered by embeddings. Vector databases are built to store and retrieve those high-dimensional embeddings at speed and scale. Without them, your AI is blind to nuance and context.
You can, but it’s like putting rocket fuel in a go-kart. Traditional databases weren’t designed to handle vector math, high-dimensional search, or fuzzy contextual reasoning. Vector databases offer native support for ANN (Approximate Nearest Neighbour) search, optimised memory layouts, and real-time ranking, all critical for applications like RAG, chatbots, and personalisation engines.
The kind users now expect by default. Think: chatbots that remember what you said three interactions ago. Product recommendations that “just know.” Semantic search that feels like conversation. Vector databases turn user signals, preferences, and content into embeddings, making every interaction adaptive, contextual, and real-time.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




