



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)


TABLE OF CONTENT



This piece is an overview of a Modern Data Masterclass:
Data Modelling for Data Products by Mahdi Karabiben.

Mahdi has been working in the data space for more than eight years and is presently the Senior Product Manager at Sifflet, which builds data observability. Formerly, he was a Staff Data Engineer at Zendesk, working on the company’s Data Platform. Mahdi has dabbled in multiple industries and organisations, working with different types of data, all in the context of building petabyte-scale data platforms. The constant across these experiences was the scale of data and building competent platforms and tools that managed that scale.
Below is a detailed overview of Mahdi’s session, which should give you a taste of the concepts he touches on, his drive and emphasis on why fundamentals of data modelling suffice the innovation that data products bring to the modern data infrastructure, essentially eliminating the need to reinvent the wheel.
Data modelling, at its core, is the act of giving data shape and constraints so that it becomes reliable reasoning material. It defines how concepts relate, how meaning propagates, and how systems preserve truth across change.
A data product, in contrast, is not a table or a dashboard; it is a reusable and measurable asset engineered with the discipline of product thinking: versioned, owned, and designed for a specific outcome.
We are once again at an inflexion point. In the 1990s, centralised data warehouses and dimensional models gave organisations consistency and trust. The Hadoop era traded that trust for scale: data was everywhere, but meaning was nowhere. The modern data stack made infrastructure effortless, but encouraged ad hoc pipelines that decayed faster than they created value. Now, the pendulum is swinging back toward decentralisation, where domains own their data, models are built around value streams, and governance must be designed instead of imposed.
This shift raises four questions that define the future of data modelling.
The organisations that answer these questions will stop managing data and will start composing business with it.
Every good model begins with intent. The question is never how to model, but why this data deserves to be modelled at all. The foundational shift in modern data modelling is moving from data structure to business structure; from tables to purpose. Data should mirror how the business creates value, not how engineers prefer to store it.
The process begins with relentless inquiry. Why does this data matter? Which part of it truly changes decisions or outcomes? The answers rarely live in documentation but in the experiences of users: the Slack threads where analysts debate metrics, Zoom calls where product managers reason through growth levers, interviews where operators describe the bottlenecks no dashboard shows. Modelling starts when you start listening.
Once the noise is collected, patterns emerge. Natural boundaries of ownership and purpose. These become data domains: marketing, sales, finance, operations. Each domain is not a silo, but a context: a space where data holds meaning because it supports a shared objective. Within every domain, alignment must be explicit:
The goal is to translate the organisation into a formula, one that connects inputs to outputs, and causes to effects. Only when this map of value is visible does modelling begin to make sense.
A good data model doesn’t emerge fully formed. It’s refined through layers of abstraction. Each layer translates intent into precision: from language to logic to implementation. Modelling in layers ensures that business meaning is never lost in technical translation. It creates a shared rhythm between domain experts and engineers, between what the company does and how data represents it.
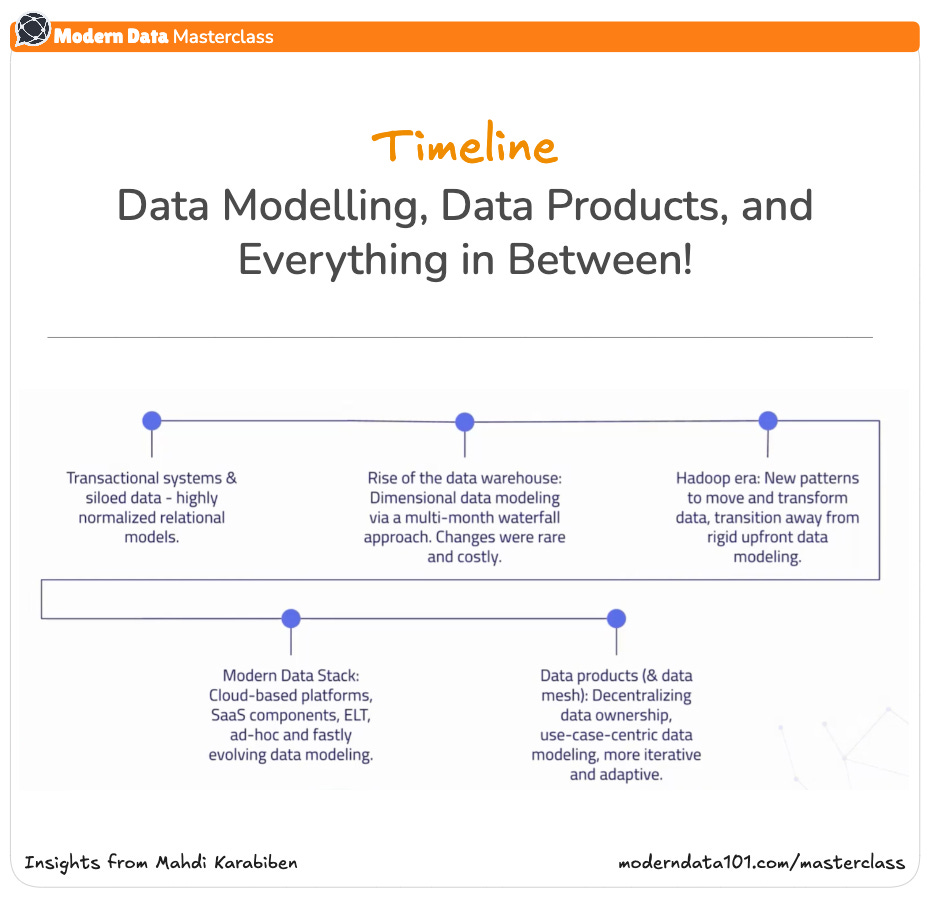
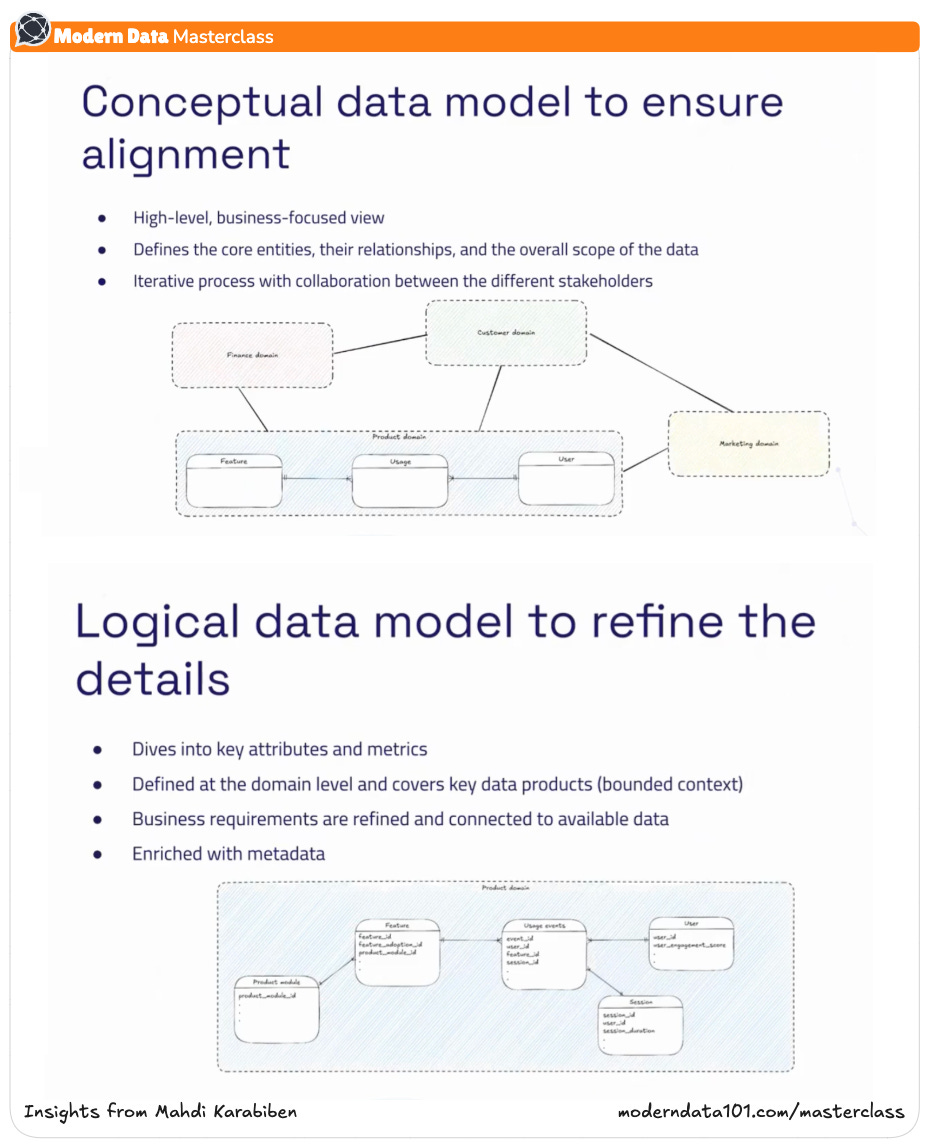
The conceptual model is the first sketch: a language for shared understanding. It captures how the business sees itself: customers, products, transactions, campaigns, relationships. At this stage, precision matters less than alignment. The goal is to describe the world as it is understood by humans, not yet as it will be computed by systems.
This stage is collaborative by design. It demands conversations, not code. You define domains, not boundaries; relationships, not joins. Each domain becomes a unit of ownership and purpose. Validation here isn’t about schema correctness, but coherence matters more. If everyone can see themselves in the model, we’re on the right track.
The logical layer transforms shared language into formal definition. Here, concepts gain attributes, metrics, metadata, and ownership. It is the stage where “customer” becomes a structured entity with clear inputs, outputs, and rules of engagement. The model must begin to reflect operational reality without collapsing into physical constraints.
Look leftward: do the existing data sources support these use cases? Do logs, APIs, or SaaS tools emit the signals your model needs? The logical layer is where expectations meet feasibility. It’s also where business requirements are refined: what can we model today, and what must we evolve toward? Every limitation discovered is a design opportunity.
The physical layer gives the model a home. Tables, views, data products: all are expressions of the logic that preceded them. But this is not a one-way descent into rigidity. The physical layer should remain porous, allowing evolution without breaking trust.
Avoid the temptation to centralise everything into a single, monolithic model.
Let each domain own its portion, as long as the interfaces between them are governed and discoverable. Interoperability is the goal, uniformity is secondary. The physical model succeeds when it can serve the business without distorting it.
📝 Related Read:
Where Exactly Data Becomes Product: Illustrated Guide to Data Products in Action
ANIMESH KUMAR AND TRAVIS THOMPSON
Modern data modelling is an act of coordination across teams, tools, and truths. The challenge is not to centralise control but to create coherence without conformity. Ownership today is distributed by design:
…marketing, finance, product, and operations each hold part of the company’s truth. The role of modelling is to ensure these truths can coexist, connect, and compound into value.
A universal conceptual model should anchor the organisation: a shared vocabulary that defines how the business operates. Beneath that shared layer, each domain maintains its own logical model, shaped by its data, cadence, and decisions. This structure preserves autonomy without breaking alignment.
Successful governance frameworks are often foundational translators, ensuring that independently built models can speak to one another. Two paths exist:
The choice depends on organisational maturity. Uniformity creates consistency; autonomy creates relevance. Both are valid, but neither works in isolation. Tradeoffs.
Avoid one-way-door decisions that trade adaptability for short-term neatness. Preserve granularity; it’s the raw material of future requirements and scale. Optimise models for learning.
Reject the safe bet fallacy: the idea that following established standards guarantees safety.
In practice, it equates to stagnation. Every choice, from schema style to governance model, must earn its justification through context.
Finally, practice decision hygiene. Gather perspectives before committing, revisit assumptions once the system breathes, and pivot early when new truths emerge. Agility is not about moving fast, but staying aligned while evolving deliberately.
📝 Related Read:
Data Modelling Best Practices to Support AI Initiatives at Scale
Data modelling reaches its full potential only when its logic can be expressed, shared, and reused. Frameworks and tools act as the connective tissue between thought and execution, transforming human reasoning into governed systems.
Two constructs define this new era: Metric Trees and the Semantic Model.
Together, they allow organisations to move from fragmented data definitions to a unified model of value.
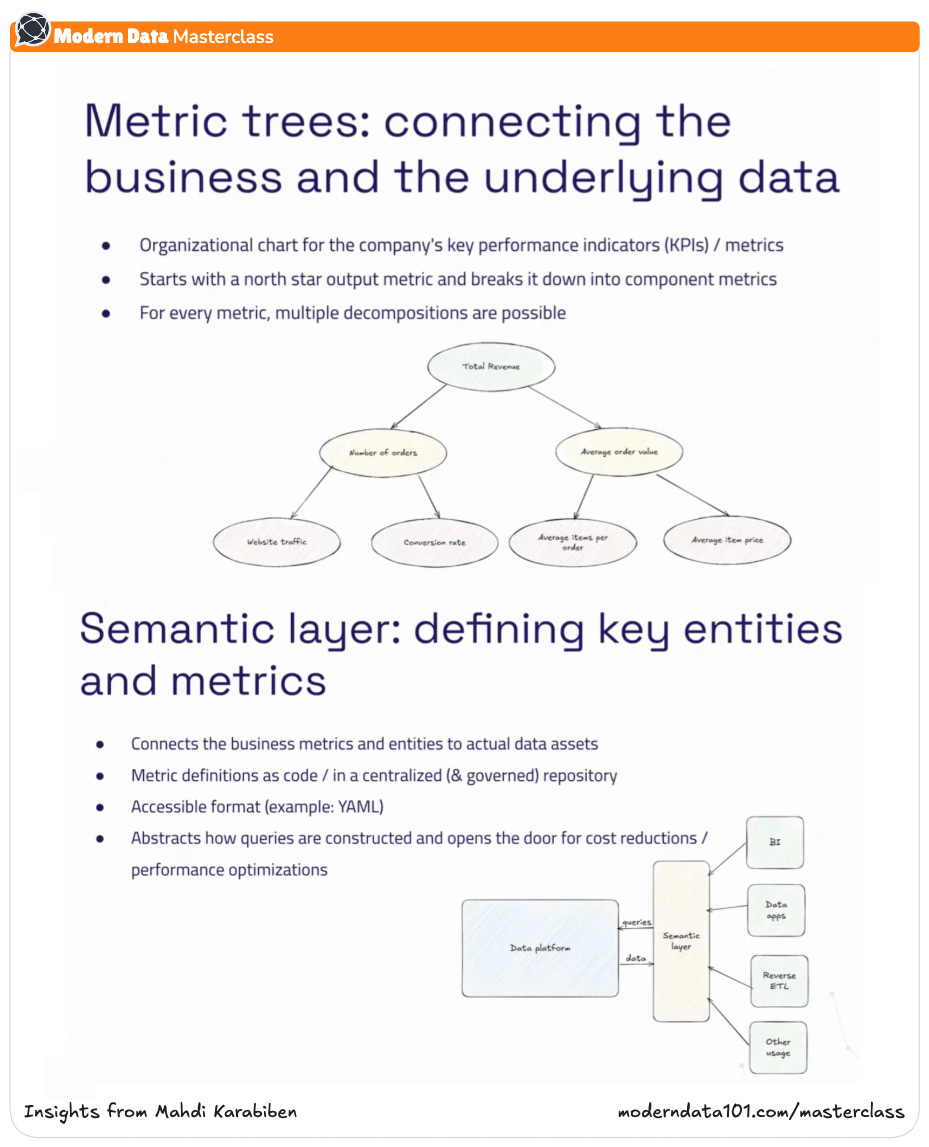
A Metric Tree is not just a hierarchy of numbers; it is an expression of how a business creates value. It starts with a North Star metric (the outcome that defines business success) and decomposes it into its components and controllable levers.
For example:
This structure turns business performance into a navigable system. Analysts stop chasing disconnected KPIs and start reasoning through dependencies. Metric Trees expose causality: where an improvement will actually matter and how interventions cascade through the business. They align teams by connecting operational metrics to financial outcomes, making impact visible and measurable.
📝 Related Read:
Metrics-Focused Data Strategy with Model-First Data Products | Issue #48
ANIMESH KUMAR, SHUBHANSHU JAIN
If Metric Trees describe how value flows, the Semantic Model defines how it is measured. It is the layer where metrics gain formal definitions, lineage, and governance: a source of truth that sits between raw data and every analytical tool.
In practical terms, the Semantic Layer is a version-controlled, queryable catalog of metric definitions and relationships. Business logic defined once, reused everywhere. Dashboards, notebooks, and applications all speak the same analytical language without redefining logic downstream.
Its advantages compound over time:
When implemented well, the Semantic Model ensures that every question asked in the organisation draws from the same foundation of truth.
📝 Related Reads:
Semantics and Data Product Enablement - A Practitioner's Secret
FRANCES O'RAFFERTY
The Semantic Layer Movement: The Rise & Current State
ANIMESH KUMAR
Metric Trees and Semantic Layers serve a single purpose: to make data modeling operationally alive. They connect abstraction to execution, metrics to meaning, and teams to each other. In their absence, models remain theoretical, probably precise but unused. When adopted together, they form the feedback loop between design and impact: how we define value, how we measure it, and how we evolve it over time.
The craft of data modelling has come full circle: returning to structure, but this time infused with agility and product thinking. What once revolved around schemas and storage now centres on value chains: understanding how data moves through the organisation to create measurable outcomes.
The modern modeller begins with why, collaborates across domains to embed context, evolves designs as the business learns, and governs not by control but by coherence. The Masterclass session dives into the nuances of this lifecycle and extends the viewer’s understanding from theoretical ideas to practical forms of implementations with foundational techniques like data modelling.

01: Data Product Managers | 02: Analytics Engineers | 03: Data Engineers
💡 What’s the difference between a data model and a data product?
💡 How do I ensure my data models align with real business needs?
💡 What tools and frameworks are essential for robust data modelling at scale?
and more!
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



