




Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT



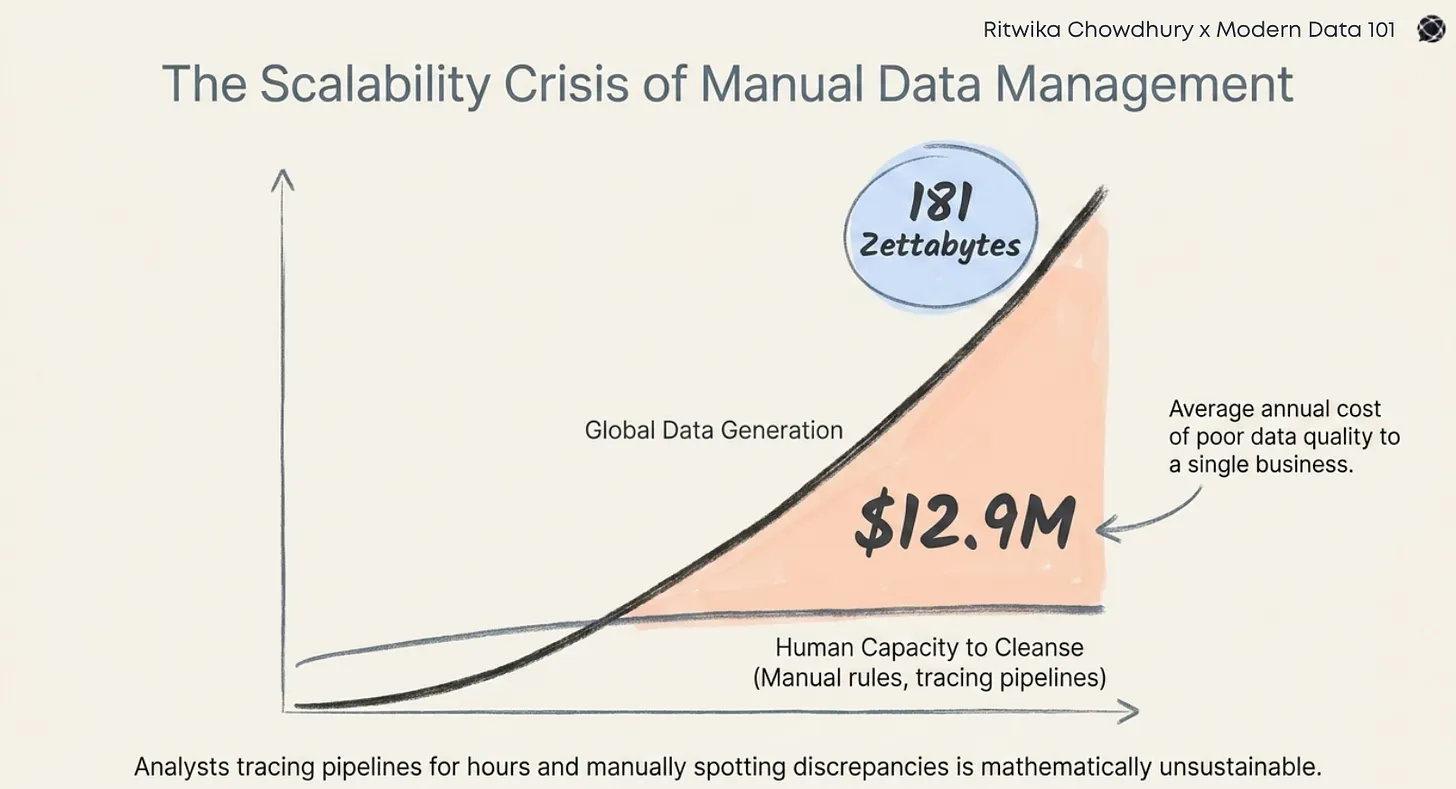
Have you ever felt like your organisation is caught up in the swirl of an AI arms race? All around, teams are piloting powerful AI projects, from sophisticated recommendation engines to predictive analytics, promising to revolutionise operations.
But while the initial excitement is real, taking AI from clever experiments to robust, large-scale deployment is a whole different game. You might find yourself tripping over data issues time and again, as that first flush of AI sparkle starts to fade.
This is where we talk about data modelling, the unsung hero in these circumstances.
The DataOps platform market is expected to expand to $36.29 billion by 2034, at a CAGR of 18.9%.
It isn’t just a niche concern tucked away in the IT department. Today, it is the core blueprint upon which intelligent, scalable AI gets built. In the age of Machine Learning, Data Modelling means more than drawing up schemas. Building scalable data models is now a critical requirement for organisations looking to move AI initiatives from experimentation to production. As AI adoption grows, data models must support flexibility, governance, and long-term reuse across teams and use cases. It’s about understanding what your data actually means, how it flows, and ensuring it’s positioned for powerful, flexible use by models not just for the day, but as your use cases grow in the future.
[state-of-data-products]
Think of your data as the critical infrastructure of the business. It is the roads and bridges connecting everything you do. Today's enterprises manage rapidly growing data volumes from diverse data sources, making effective data modelling essential for maintaining performance, consistency, and trust across AI initiatives. For this analogy, data modelling is your Architectural Plan. Once you get that correct, your data flows efficiently, supporting fast, insightful AI. Get it wrong, and your foundations crack under the weight.
Traditional Business Intelligence focused on aggregating information for dashboards and reports. AI and Machine Learning, though, put very different demands on your data: they thrive on highly granular, contextualized inputs, and care about detail and signal more than neat summaries. If your data model doesn’t match what AI needs, you risk making the same transformation, integration, or data-cleaning effort over and over for each new model or project. That’s when “model drift,” unreliable pipelines, and fragile ops become the norm.
Beyond performance, solid data modelling is crucial for explainable, compliant, reusable AI. Teams can trace why a prediction was made, protect sensitive information, and reapply learnings across different products with confidence.
The journey to scaled AI is littered with good intentions gone awry through suboptimal models. The most common traps?
😉Think of it like you are building a fancy AI skyscraper with quicksand as the mortar for its foundation. That's precisely what happens with traditional, ill-suited data models. You might have the latest algorithms, but if your data is a tangled mess, your AI will probably predict ineffectively to add to the mess.
[report-2025]
So how do you move from pitfalls to best-in-class? It’s a shift in both mindset and process.
Model data for AI use cases from the get-go. This AI use case could be an AI Application, an Agent, an ecosystem of AI Agents, or simpler ML models. Data should be purpose-driven and modelled (productised) to the niche case it serves. It may borrow from common heavy data models like Customer 360, but say a data model for marketing campaign acceleration would have specifics of the measures, fields, and SLOs demanded by the specific marketing app or the AI Agent running it.
A model-first strategy helps teams create scalable data models by focusing on business outcomes first and then aligning data structures to support them. This approach makes it easier to handle increasing workloads while designing scalable solutions that remain relevant as AI initiatives grow.
Don’t treat data as an afterthought. Plan for AI consumption from the beginning. Shape your data products with an eye on what models will need, considering granularity, relationships, and semantic clarity before the data even hits your platform. Think deeply about meaning, not just format, and set up consistent versioning so models don’t break when sources evolve. Organisations should also ensure alignment between conceptual, logical, and physical models so business requirements remain consistent throughout implementation and deployment.
This is how a model-first approach for data translates into: Right-to-left data development instead of the traditional left-to-right path where data is extracted from the sources, whatever data is available is then processed, and then we go from there (think medallion).
When you think model-first, you model the use case requirements first and then work on only those requirements and that segment of data processing, which now enables much more focus, finesse, and purpose-driven workflows and resources. This also implies huge cost-effectiveness for AI-focused workloads where resources are self-served and unassigned at scale.
Data without context is just noise. Capture where your data comes from, its business definition, and any key assumptions right inside your models. This makes it possible for data scientists to understand, monitor, and explain results and not just build black boxes.
A strong semantic layer serves as an important data modeling technique for representing real-world business entities, relationships, and metrics in a way that both humans and AI systems can understand. With this, the LLM functions with the pre-defined contextual models and accurately projects data with contextual understanding, and in fact, even manages novel business queries.
Instead of misinterpreted entities or measures, the LLM now knows exactly what table to query and what each field means, along with value-context maps for coded values.

When every pipeline contains its own version of feature engineering logic, teams end up reinventing the wheel in dozens of places. Standardised, modular feature stores let you build features once and share them across teams, streamlining development and bolstering reliability. Many modern tools now support feature-store architectures that improve governance, reduce duplication, and simplify collaboration across data and AI teams. Big tech firms like Netflix or Uber lean heavily on this principle to stay agile.
In pipeline-first, the failure of P1 implies the inevitable failure of P2, P3, P4, and so on…
In data-first, P2 doesn’t fail on the failure of an upstream pipeline, but instead checks the freshness of the output from upstream pipelines.
Don’t fall into the one-dataset-per-model trap. Think in terms of feature “primitives.” Base units that can be recombined for many AI use cases. Build up canonical vocabularies and data models so everyone understands what a “customer” is, or how an “event” is defined, regardless of project or team. That shared language accelerates integration and boosts trust.
This approach is fundamental to building scalable data ecosystems because reusable components allow organisations to create scalable models that can support multiple business functions without unnecessary duplication.

How reusability is driven at scale:
Most data platforms fragment as they scale. Every new use case creates more drift, not more alignment.
Data Developer Platform (DDP) inverts that pattern. Every new product adds structure. Every model becomes reusable.
This is where platform leverage shows up: in shared language. DDP’s semantic spine turns internal reuse into network effects. Strategic levers:
These principles help organisations develop scalable architectures that encourage standardisation, improve interoperability, and support future AI-driven innovation.
Treat your models as living things that evolve with your business. Bake data observability and monitoring into your data flows: track usage across experiments, monitor for drift or anomalies, and collect feedback. Continuous oversight keeps your models healthy and your AI responsive to real-world change.
Observability also helps organisations adapt to evolving business requirements, regulatory expectations, and AI performance demands without constantly redesigning underlying data structures.
😉Think of metadata as your data’s ultra-detailed personal profile. Without it, AI models (and data scientists) are left guessing about what values actually mean, risking confusion and mistakes. Context matters, especially if you want intelligence & not just automation.
Even the best data practices require people and processes to stick. Assign clear ownership roles tasked with the health and quality of specific data models that create accountability and ensure ongoing investment in your most important assets. Foster close collaboration between engineers, AI specialists, and domain experts. It’s everyone’s job to ensure your data models truly represent the business and its goals.
📝 Related Reads:
Universal Truths of How Data Responsibilities Work Across Organisations by Paul Jones
Data Product Manager vs. Data Product Owner: Decoding the Roles for Data Success by Nikhil Singh & Swami Achari
The Role of the Data Architect in AI Enablement by Colin Harde
It’s tempting to focus on the shiny advances in AI and Machine Learning, but as organisations like Gartner and Forrester point out, sustainable scale always comes back to the basics: data infrastructure and modelling.
In particular, organisations that invest in scalable data models gain a stronger foundation for supporting AI workloads across cloud-native and cloud-based environments, while remaining flexible enough to accommodate future business needs.
Nail these fundamentals, and you’ll accelerate every downstream AI project and not just this year, but into the future too.
Teams that commit to strong data modelling practices build faster, safer, and more trustworthy AI. By investing in scalable data models, organisations can reduce technical debt, encourage innovation, and create future-proof foundations that support long-term growth. These models help businesses adapt quickly as technologies, customer expectations, and AI capabilities continue to evolve.
This is true for more than teams like to admit. If the modelling in question is poorly done, it leads to inconsistent features, brittle pipelines, and expensive corrective actions later. The models will run, but scale and trust will always be a struggle.
Yes. This is because AI models place more emphasis on feature reuse and evolution, whereas analytics models give more attention to reporting efficiency. When they are treated the same, it creates slower experimentation and fragile ML workflows.
Data practitioners recommend to go for the latter approach, that is, evolving data models incrementally, because large upfront designs stop the progress of AI innovation. On the other hand, iterative changes allow teams to learn from model behaviour, data drifts, and feature needs in real-time without early over-engineering.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




