


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.jpg)


TABLE OF CONTENT




Unless you've been living under a rock or trying to book a GP appointment over the telephone in the UK, it can't have escaped your notice that the hype about AI and its varied uses is reaching fever pitch.
Every PowerPoint presentation worth its salt now has at least three mentions of ChatGPT, two references to "transformational opportunities," and at least one tantalising promise of Agentic nirvana.
Inevitably, following this peak of inflated expectations, we will then enter the trough of despondency before finally emerging, battle-scarred but wiser, into the plateau of productivity. Only at that point might we actually get some work done, rather than simply talking about how AI will fundamentally change every aspect of modern existence while simultaneously rendering most of us unemployed.
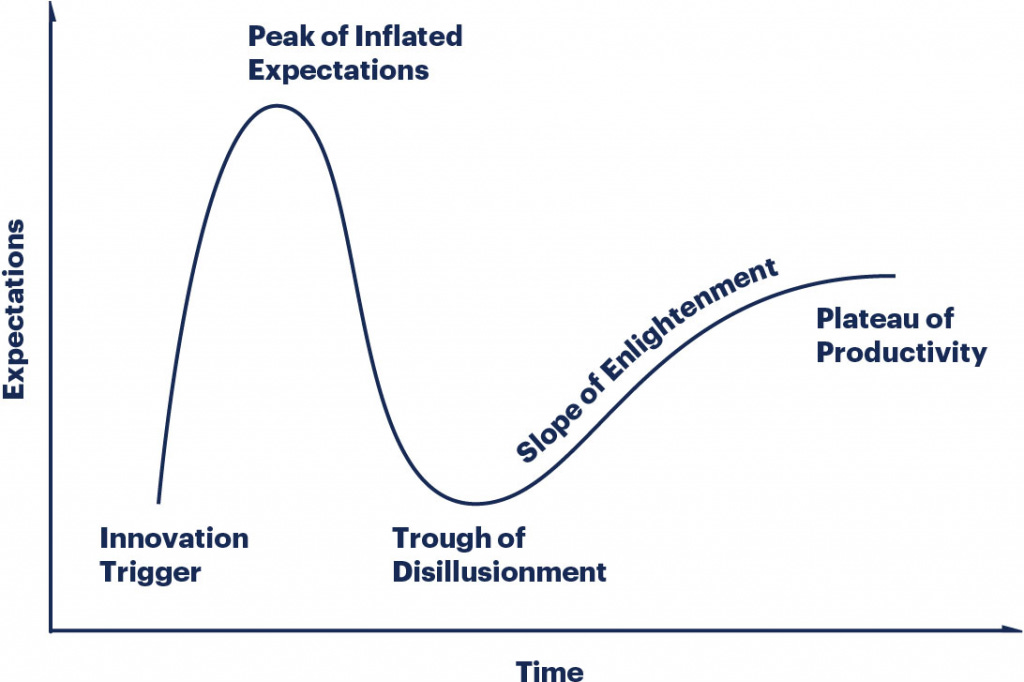
As we navigate this treacherous landscape, trying to sift fact from fiction, it's worth examining the critical but often overlooked role of the Data Architect in laying the groundwork for successful AI initiatives.
One reason the Data Architect can be forgotten when talking about AI may be that the term itself is massively overloaded and means different things to different people, rather like how "biscuit" describes a completely different culinary experience depending on which side of the Atlantic you're standing.
A quick survey of job listings reveals a veritable alphabet soup of titles, each purportedly describing a "Data Architect" role but with wildly divergent expectations and responsibilities:
The common thread running through all these roles is a responsibility for designing and maintaining the scaffolding upon which effective data systems and, by extension, AI systems are built. From defining data strategy to implementing governance frameworks, from creating data models to facilitating knowledge graph development, these professionals are the unsung heroes working behind the scenes to ensure that Agentic coffee maker doesn’t mix your matcha latte up with your mocha frappe.
Before we discuss how Data Architects can enable AI, it's worth establishing a conceptual framework that helps position their role and the broader considerations we need to keep in mind for AI to be successful.
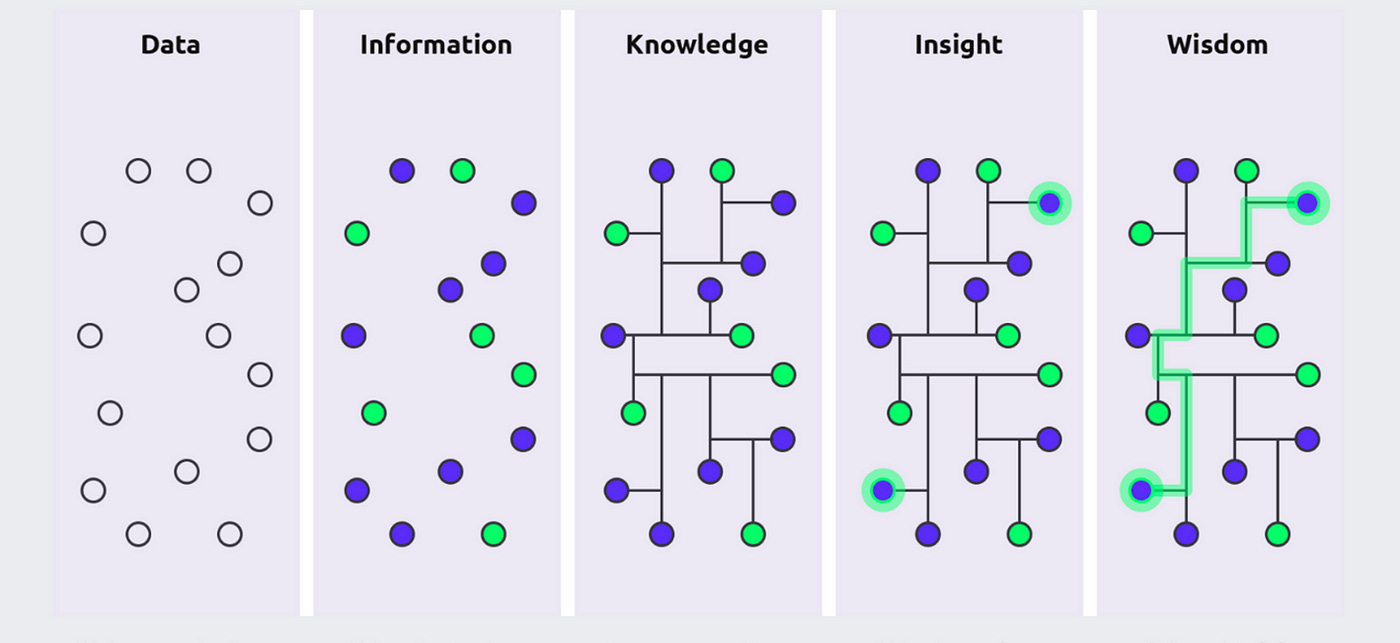
Two complementary models prove particularly useful here: the classic DIKW (Data-Information-Knowledge-Wisdom) Pyramid and the more recent AI Hierarchy of Needs.
The DIKW Pyramid has been a staple of information science since the 1980s, describing how:
📝 Related Reads
Back to Basics of Knowledge Management
Meanwhile, the AI Hierarchy of Needs (a clever riff on Maslow's psychological hierarchy and, in this version, inspired by that used by Shopify) outlines the foundational requirements for successful AI implementations.
While traditional AI Hierarchies of Need tend to emphasise tools and technologies, placing AI and deep learning at the pinnacle, Shopify's Data Science Hierarchy of Needs takes a more impact-focused approach that aligns better with the practical role of the Data Architect:
What's striking about this approach is that it places impact, not technology, at the pinnacle.
Data Architects operate primarily at the lower levels of this hierarchy, establishing the foundation that makes everything else possible. While data scientists and ML engineers might focus on prediction and prescription, data architects ensure that reliable, high-quality data is available first.
This is why the Data Architect's role is so critical. In the rush to climb to the top of these hierarchies, to create influence and prescribe solutions, organisations often underinvest in the foundational layers of collection and modelling. It's rather like trying to build a palace without first ensuring solid foundations and structural integrity. The resulting palace might look impressive in the architectural renderings, but it will inevitably collapse when constructed.
As Shopify's approach reminds us, the most advanced techniques aren't always necessary to create impact. Sometimes, a simple, well-structured dataset with clear documentation can be more influential than the most sophisticated neural network built on shaky data foundations.
However, while strong foundations are essential, there's a significant risk in the other direction too: spending so much time perfecting the foundational layers that you never actually deliver value. This is where we can learn from an elegant French pastry and a brilliant software development analogy.
About ten years ago, I lived in Blackheath village in London, where I regularly visited a French bakery called Boulangerie Jade. My favourite patisserie there was the delight of their opera cake: a meticulously crafted confection of layered almond sponge, coffee buttercream, and chocolate ganache, each layer distinct yet harmoniously integrated with the others.
In 2003, Bill Wake used this type of layered cake as an analogy for software development. He wrote:
"Think of a whole system as a multi-layer cake, for example, a network layer, a persistence layer, a logic layer, and a presentation layer. When we split a story, we're serving up only part of that cake. We want to give the customer the essence of the whole cake, and the best way is to slice the cake vertically through the layers. Developers often have an inclination to work on only one layer at a time (and get it 'right'), but a full database layer (for example) has little value to the customer if there is no presentation layer."
This analogy applies perfectly to AI enablement. Data Architects must resist the temptation to build comprehensive, enterprise-wide data models or governance solutions before allowing any AI initiatives to go ahead.
Instead, they should collaborate with business stakeholders and data science teams to deliver "vertical slices" that include everything necessary for specific, high-value use cases.
📝 Related Reads
A. Vertical slicing embodied by data products: Directly coupled with Data/AI use cases | Impact on Lineage
B. Vertical Infrastructure Slices of Data for Specific Use Cases | How Data Becomes Product

Data Products are vertical slices of the data architecture, cutting across the stack, from data sources and infra resources to the final consumption points (for representation) | Source: How Data Becomes Product
Each vertical slice should include just enough of each layer:
As more slices are delivered, patterns will emerge that can be standardised and expanded into more comprehensive capabilities.

With this balanced approach in mind, let's explore ten practical ways the Data Architect can enable successful AI implementations, moving methodically through these hierarchical levels from foundation to execution, but always with an eye toward delivering complete vertical slices.
Before diving headfirst into the latest AI trend, Data Architects should ensure the organisation understands its current state. This means conducting a brutally honest assessment of data maturity and AI readiness.
Rather than boiling the ocean, start by identifying specific business units or functions that already have relatively mature data practices. Map their existing datasets, assess quality, and determine whether they have the foundational elements required for AI: sufficient volumes of relevant data, basic governance, and clear use cases.
Simultaneously, engage with business stakeholders to identify immediate challenges that could benefit from AI solutions. The goal isn't to produce a 300-page report that will gather digital dust in some forgotten SharePoint folder, but rather to quickly identify low-hanging fruit and problems where AI could provide tangible value with existing data assets.
Once a potential use case has been identified, the Data Architect must become temporarily obsessed with understanding the business domain and processes involved. This task is sadly neglected in many AI initiatives that rush headlong into technical solutions. This process should be conducted with business and domain experts, including any Business Architects the organisation may have as part of a wider EA capability.
It involves:
The output should be a clear vision of how the business process will be transformed, with specific touchpoints where AI will add value and the data and information flows necessary to support it. It should not be a nebulous promise to "use AI to make things better" that leaves everyone scratching their heads about what that actually means.
📝 Related Reads
How to Build Data Products - Design: Part 1/4 | Issue #23
Despite what the army of vendors knocking at your door might suggest, not every problem requires an LLM. As a result, we need to determine which analytical approaches are most appropriate for the problem at hand.
Critically, this analysis must be conducted in close collaboration with the Data Science and AI teams and may overlap somewhat with the Solution Co-Creation phase of the previous step. The Data Architect brings expertise in data structures, quality requirements, and enterprise integration; the Data Scientists bring expertise in algorithms, model characteristics, and analytical approaches. Neither group alone can make the optimal decision.
Together, create a simple decision framework that helps stakeholders understand when to use:
Remember that the simplest solution is often the best. If a problem can be solved with a well-crafted SQL query, there's no need to deploy a transformer-based neural network that requires a small power station to run.
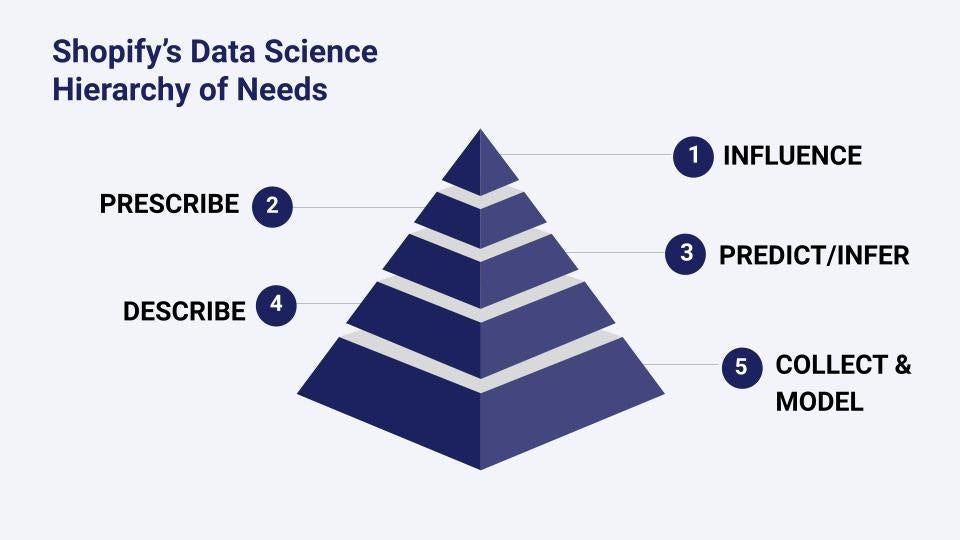
As Shopify's hierarchy reminds us, impact matters more than technological sophistication.
Different AI systems have different governance requirements. Traditional ML models reliant on structured data are more sensitive to data quality issues, while LLMs require governance around knowledge management and business contextual metadata.
Data Architects must ensure that governance frameworks extend to these AI-specific concerns while also addressing regulatory requirements. However, consistent with our opera cake approach, focus on creating just enough governance for each vertical slice rather than attempting to build a comprehensive enterprise data governance framework from the outset.
Map data needs to governance implications by considering:
Develop just enough governance to ensure appropriate context, understanding, and compliance without stifling innovation. For each AI initiative, create a minimal viable governance framework that can be expanded as the solution matures, rather than insisting on full-scale governance from day one.
📝 Related Reads
How to Create a Governance Strategy That Fits Decentralisation Like a Glove
AI models require data, often lots of it, and ensuring the correct data is available at the right time is a critical architectural concern.
Assess:
Avoid over-engineering data pipelines to provide real-time data when daily or weekly updates would suffice. Conversely, ensure that time-sensitive applications have the necessary infrastructure for low-latency data access. The goal is to create a technical architecture that is fit for purpose rather than unnecessarily complex or expensive.
The technical infrastructure for model training and deployment is often underestimated until it becomes a critical bottleneck. Data Architects should proactively work with AI and ML Engineers to support and design a sustainable AI Technical Architecture that supports both initial model development and ongoing operations.
It should address questions such as:
Create reusable patterns that incorporate best practices for model versioning, experiment tracking, and deployment automation. By establishing these patterns early, you create a foundation for efficient scaling as AI adoption grows across the organisation.
AI systems often process sensitive data and can potentially expose information in unexpected ways. This is a critical cross-cutting concern across all aspects of solution design. In partnership with CISOs or equivalent teams, Data Architects must ensure appropriate security controls at all levels.
Consider:
Design security as an integral part of the architecture, not as a bolt-on afterthought when the CISO starts asking uncomfortable questions the week before launch. Security by design ensures that AI systems can be trusted not just for their accuracy but also for their handling of sensitive information.
Models degrade over time as the world changes around them, a phenomenon known as model drift. This monitoring function ensures ongoing quality and maintains the credibility needed for the solution to be a success. Data Architects should work with their AI counterparts to design and support monitoring systems that detect and alert on various types of drift.
Things to consider include:
Design architectures that not only detect these issues but also facilitate remediation, such as automated retraining triggers or fallback to simpler models when performance degrades. A well-monitored system can maintain its value over time, even as the world around it changes.
As before, create reusable patterns that incorporate best practices and can be leveraged by other projects later on.
AI doesn't exist in isolation; it must integrate with existing systems and workflows, where insights are translated into actions. The Data Architect should ensure the solution design is fit not just for model development but also for consuming AI outputs and the all-important feedback loop.
Consider:
Design the entire feedback ecosystem, both for business impact and model improvement. This might include developing lightweight annotation tools for users to correct model outputs or implementing A/B testing frameworks to compare model versions. Remember that effective feedback loops transform a one-time analytical exercise into a sustainable system that delivers ongoing value.
AI initiatives should ultimately deliver business value, not just technical achievements. Data Architects must design systems that track and communicate this value effectively.
Establish:
Bake measurement into the architecture from day one, rather than scrambling to quantify value after the fact. This might include A/B testing frameworks, value attribution models, or integration with existing business performance tracking systems. By explicitly connecting AI initiatives to business outcomes, you create a virtuous cycle where success breeds further investment and adoption.
📝 Related Reads
*(for 8, 9, 10) How to Build Data Products - Evolve: Part 4/4 | Issue #30
The journey to AI enablement isn't a single grand transformation but rather a series of practical, incremental steps guided by a clear vision and grounded in business reality. The DIKW Pyramid and the AI Hierarchy of Needs provide valuable frameworks for understanding this journey, highlighting the critical foundational work that must be done before more sophisticated AI capabilities can be realised.
The Data Architect plays a crucial role in this journey, not by promising AI-powered unicorns that deliver infinite ROI, but by methodically building the foundations that make meaningful AI applications possible and working as part of a team to provide complete vertical slices of our Opera cake. In this way, we can ensure that AI initiatives deliver value quickly while gradually building toward more comprehensive capabilities.
The most successful Data Architects in this space will be those who can bridge the gap between hype and reality, between technical possibilities and business needs. They'll focus not on boiling the ocean but on identifying specific problems where AI can deliver tangible value, then systematically addressing the architectural requirements to make those solutions sustainable.
As we navigate the AI hype cycle, Data Architects who take this grounded approach will deliver real value while others wax lyrical about the theoretical possibilities. And when we finally reach that plateau of productivity, they'll be the ones with working systems rather than PowerPoint slides.
After all, in the wise words that no tech consultant has ever actually uttered,
"It's better to have a simple solution that works than a brilliant one that doesn't."
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡

From The MD101 Team 🧡
The quarterly edition of The State of Data Products captures the evolving state of data products in the industry. With the Q1: 2025 Report, we’re capturing the whirlwind of AI-natives that have taken the data product space by storm! If you’ve not already tapped into these insights, get them now!

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


