


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
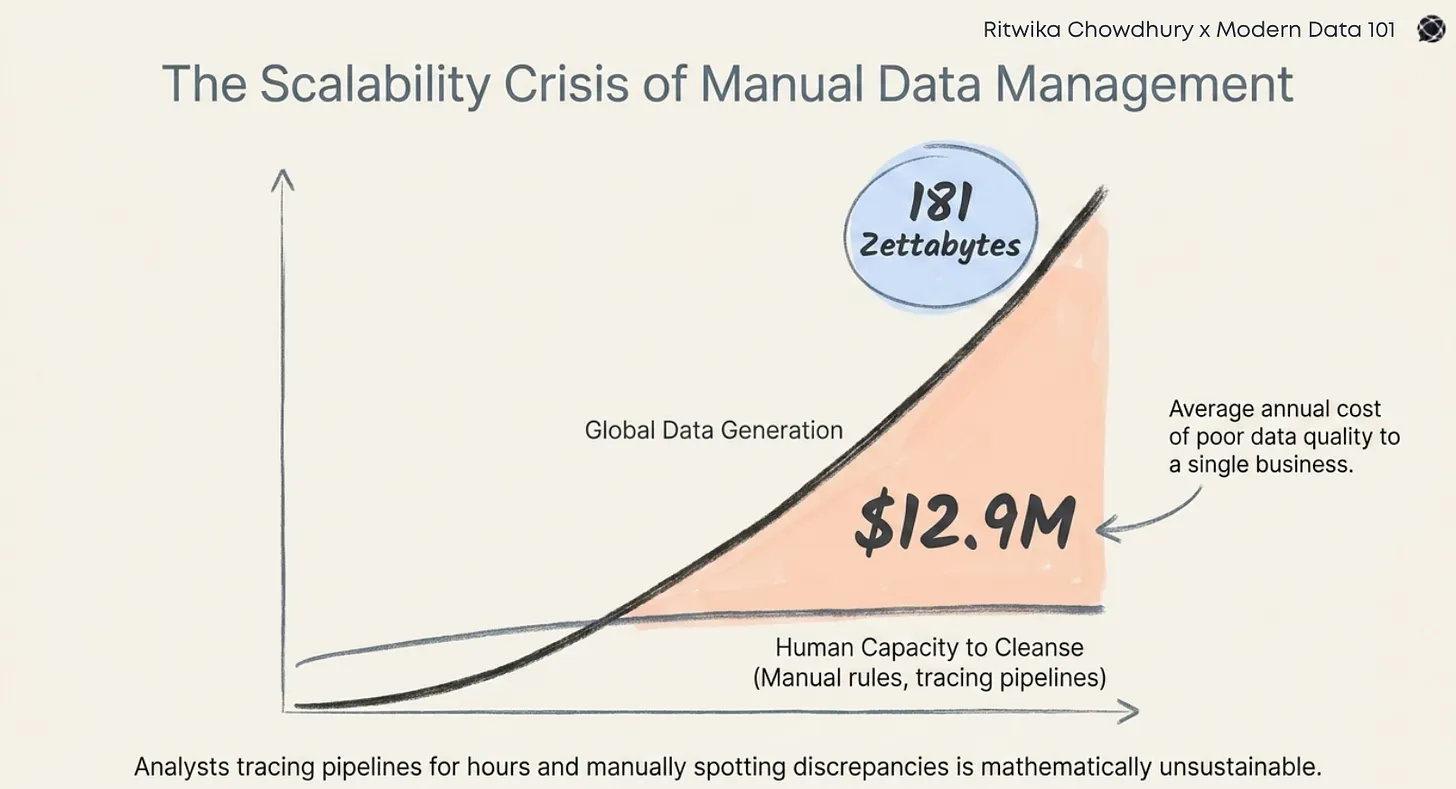
.png)

.png)

.png)
TABLE OF CONTENT



In data products, people often use ‘data risk’ and ‘data experimentation’ as if they mean the same thing. They are different, though, and mixing them up is a big reason why many organisations struggle to achieve real results with AI or analytics.
The difference may seem small, but it separates teams that just keep data flowing from those that create lasting value with their data products.
Data risk means your assumptions, models, or understanding of the business could be off in ways you might not notice. This can lead to wrong decisions, mismatched metrics, or loss of trust.
However, risk also presents opportunities for disproportionate gains. Strategic decisions embedded within models (such as definitions, granularity, dimensions, and transformations) can later yield sustainable competitive advantages. Data risk is the necessary cost of developing enduring digital assets rather than temporary dashboards.
Data experimentation is about discovering new things. It means looking at real business behaviours instead of just trusting assumptions. This could involve trying new data transformations, testing different features, tracking data flows, watching how people use data, and exploring unusual data connections. Experimentation focuses on learning and finding benefits, not just avoiding risks or chasing quick results.
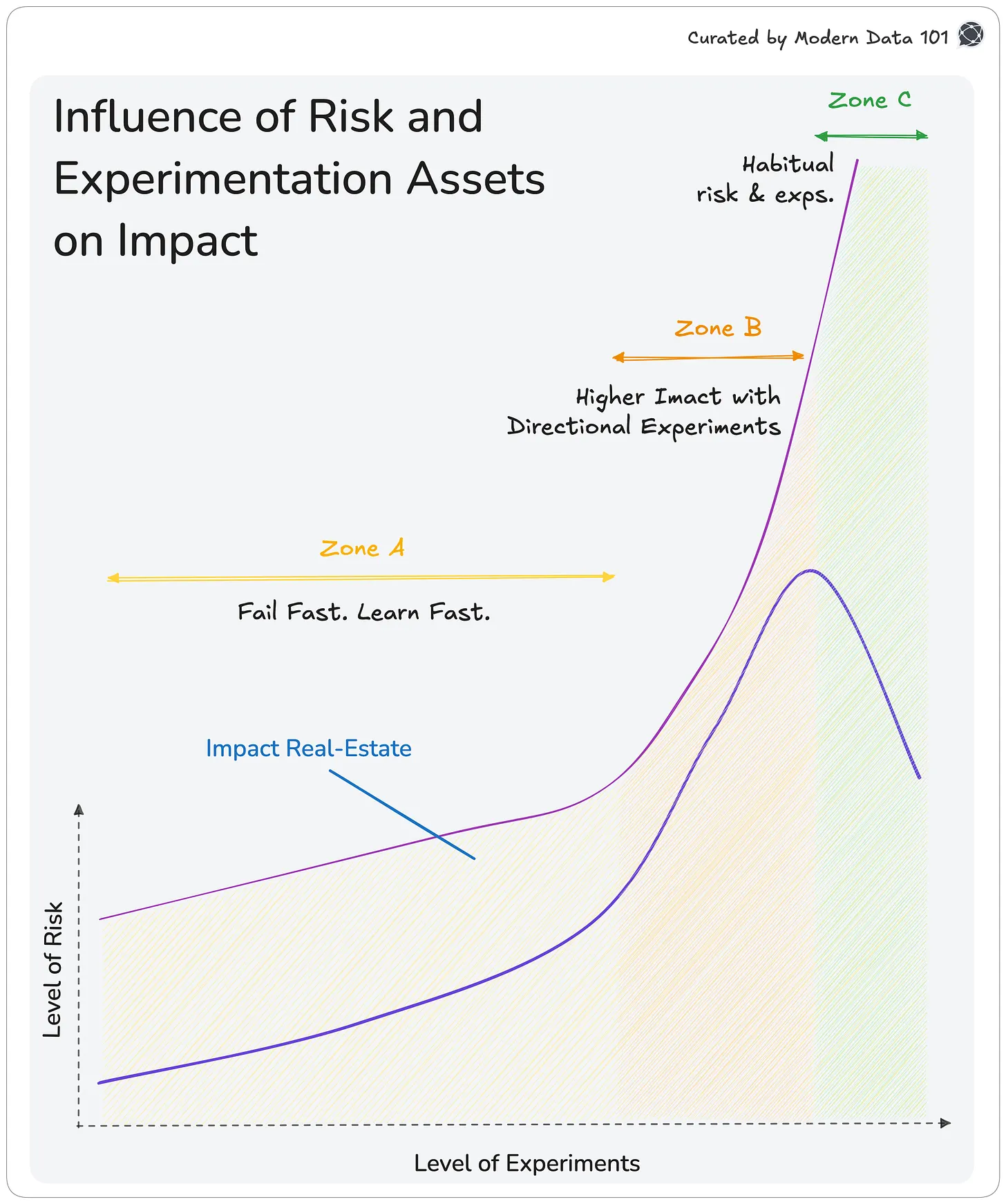
Consider a graph with experimentation velocity on the x-axis and data risk exposure on the y-axis.
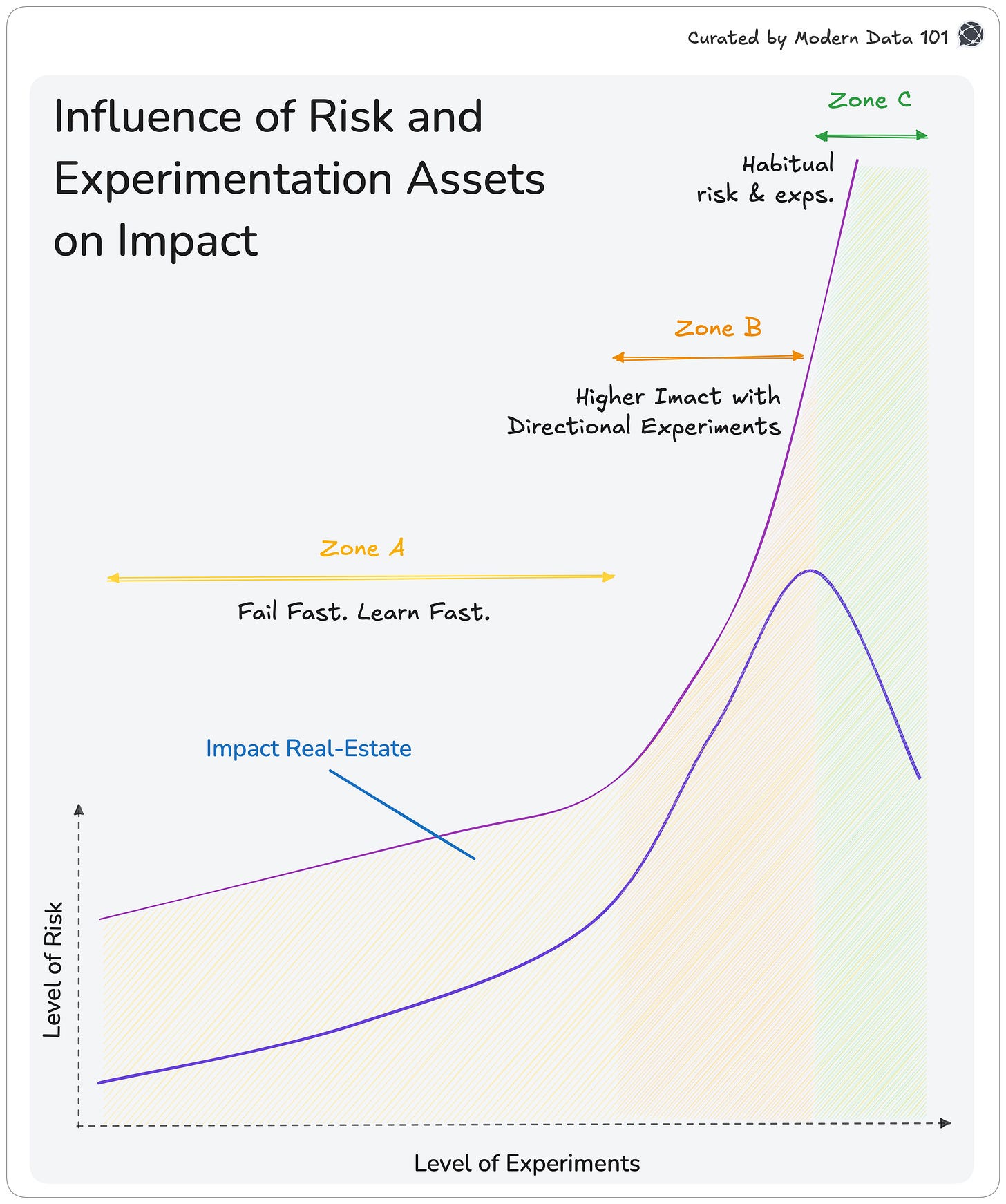
Strong data teams start here, moving quickly, running experiments that are safe to fail, and learning a lot about their data. They map out data, improve metrics, test connections, and check how users behave.
At this stage, the rest of the company is not relying on your data definitions yet, which is helpful. You can learn freely without worrying about company politics. Here, it’s important to fail fast and cheaply, since each mistake helps you understand the business better.
As you experiment more, you start to see patterns. You find reliable ways to describe your data, set clear definitions, and notice which data stays consistent over time.
This is when the impact of data products starts to grow. As the experiments turn into real outcomes, more teams begin to use them almost instinctively, and the importance of the data team’s contributions increases by becoming more deeply connected to business lines.
[report-2025]
In this zone, data experimentation and risk become mutually reinforcing. Data products begin to influence decision-making, automate processes, and, in some cases, impact customer-facing outcomes.
Even a small change to a metric or model can affect millions in revenue or disrupt how things work. Still, this is the most promising area for growth.
Now, teams like sales, finance, growth, operations, and engineering rely on your data. They care about your predictions and the information you provide. Experiments at this stage are not just for learning. They can change how the whole business sees itself.
In this stage, your impact grows quickly. Data products become self-reinforcing, and each experiment makes the organisation’s understanding stronger.
But risk also increases. The key is to keep moving quickly while making sure you understand and manage the consequences.
By now, you have a steady process. You know which experiments are safe and where you need to set limits.
Your approach to risk is now based on experience, not fear. You use different models, definitions, and data layers to reduce risk. Tools like monitoring, tracking data history, and clear agreements help keep things stable, even as you move quickly.
Your goal is to get more value from each experiment. Every new test should give you bigger insights, more value, or better reliability compared to the effort you put in. At this stage, the organisation truly acts like a data-product company.
If Zones A, B, and C show how a data product grows from curiosity to impact and then to lasting value, exponential thinking is the mindset that helps this growth speed up instead of slowing down.
The World Economic Forum says exponential thinking means seeing how something small today can quickly become very important. This idea shapes data products: small changes and improvements add up to big advantages for the whole organisation.
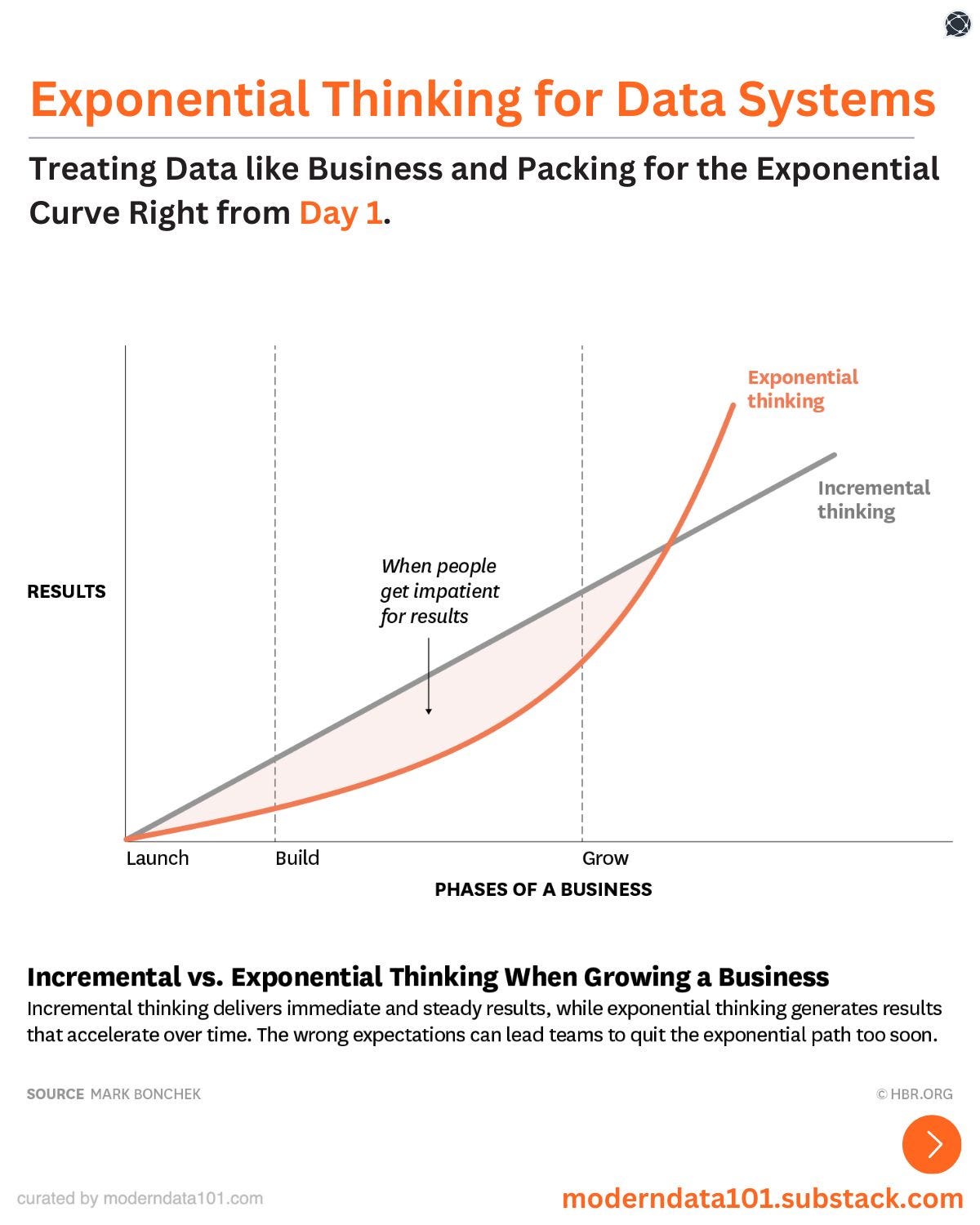
It starts with a basic idea: treat data as a key part of your business strategy.
When you view data products as strategic assets, you work backwards from your big goals. You think about what needs to be in place now (like certain features, behaviours, and structures) to make that future possible.
This is how exponential thinking links back to Zones A, B, and C:
But to build products that last through this process, you need to address four key gaps.
[state-of-data-products]
These are not technical problems, but issues with how the organisation and design work. They decide if your growth continues or stops.
In Zones A and early B, your data product is still small. Exponential thinking means you need to explain how things will come together: how definitions will settle, metrics will align, and insights will grow. You have to help others see the final goal before it’s clear to everyone.
At first, the value from data products grows slowly, not quickly. Still, you need others to stay interested until bigger benefits appear. The challenge is to show that steady progress now will lead to bigger results later.
Every good data product reaches a point where more teams start using it, new processes are added, and trust grows. Knowing when this will happen helps you decide how much to experiment in Zone B.
Once your data product starts growing quickly, your teams need to manage the extra work:
new consumers, new use cases, higher SLAs, increased semantic commitments.
If you didn’t do the necessary prep work, rapid growth can overwhelm both your team and your systems.
To fix these gaps, your data product setup needs two main systems, both closely tied to the Zone enablements.
This helps with fast experiments in Zone A and focused results in Zone B. Modularity is more than a technical idea, it also shapes your data culture and processes:
Apple is a great example. Their design approach shapes everything from hardware to teams. The same applies to data. Modularity should be part of both your systems and culture, making operations leaner and more effective. This approach lets experiments in Zone A grow into real impact in Zone B without being slowed down by team dependencies.
If everything is decentralised, you get silos. If everything is centralised, you get bottlenecks. To grow quickly, you need a mix where teams work independently but share the same information.
The operations worth centralising are:
This shared foundation keeps risks in early-stage data products from overwhelming the organisation and helps Zone C stay stable as more people use your data products. Without central visibility, growth stalls. With it, growth continues.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




