



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...
.png)

.png)

.png)

TABLE OF CONTENT


.png)

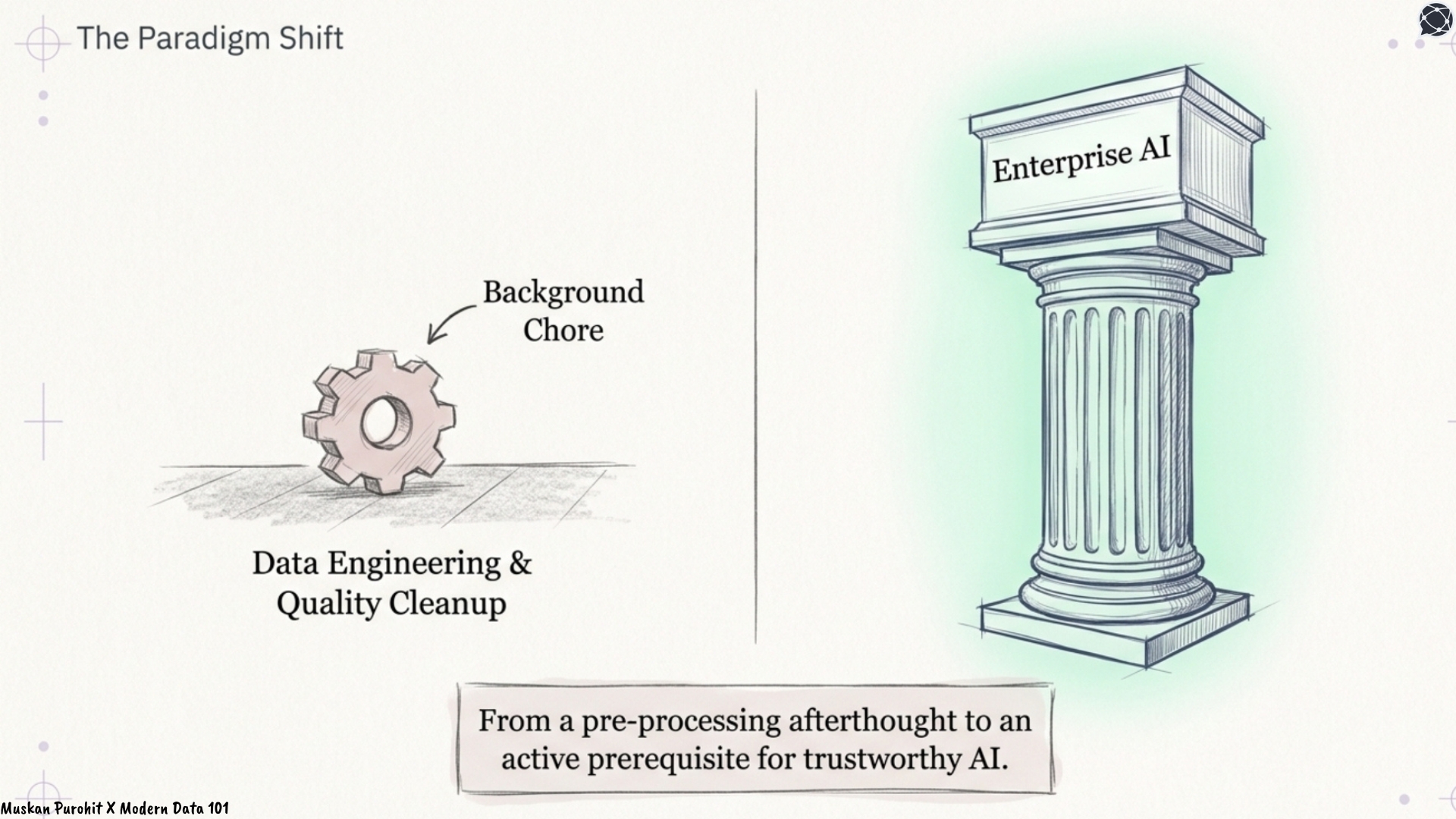
Entity resolution has always sat somewhere between data engineering and data quality: Clean up duplicates, reconcile records across systems, produce something reliable enough for analytics. It was never treated as an urgent job, more like running in the background, playing its important role.
But now, we are seeing a major shift in the industry: Entity resolution, as a result, has become foundational AI infrastructure, not a pre-processing afterthought but an active prerequisite for trustworthy enterprise AI.
Reason being: When enterprises began feeding their data into RAG pipelines, knowledge graphs, and AI agents, they quickly discovered that unresolved entity data creates false structure. Redundancy among customers in the knowledge graph is not an issue to deal with; it is a mirage that the machines have to deal with as if it exists. Agents trained or grounded on that graph inherit its errors and amplify them at scale.
The shift happened when enterprises began grounding AI in their own data. When RAG pipelines, knowledge graphs, and agentic systems are fed unresolved entity data, they inherit a fundamental flaw: they construct false structure.
A customer who appears three times in your knowledge graph is not a data quality issue for an analyst to clean up later, it is a phantom that your AI will reason over as if it were three distinct realities. Agents trained or grounded on that graph inherit its errors and amplify them at scale.
The question enterprises now face, therefore, is whether they can afford to build AI systems without it.
Rule-based ER: blocking on shared keys, fuzzy-matching on name and address, was built for a different era. It performs reasonably well when data is structured, schemas are consistent, and source diversity is limited. But enterprise AI environments look nothing like that.
[state-of-data-products]
Organisations now ingest data from dozens of systems: CRMs, ERPs, product databases, third-party enrichment providers, event streams, and unstructured documents. The same supplier might appear differently across different source systems, each contextually valid, none obviously wrong. A customer active in one geography may be dormant in another under a slightly different identifier.
Traditional ER resolves surface-level similarity. What AI-scale identity resolution demands is semantic disambiguation: understanding that two records refer to the same real-world entity even when the signals are indirect, partial, or deliberately obscured.
This is precisely where machine learning and graph-based approaches shift the performance curve. Rather than comparing records in isolation, they examine surrounding relationships (shared phone numbers, co-occurrence in transactions, overlapping lineage) to make resolution decisions that rule-based systems cannot.
[related-1]
There is a productive circularity between entity resolution and knowledge graphs that the industry is only beginning to exploit properly.
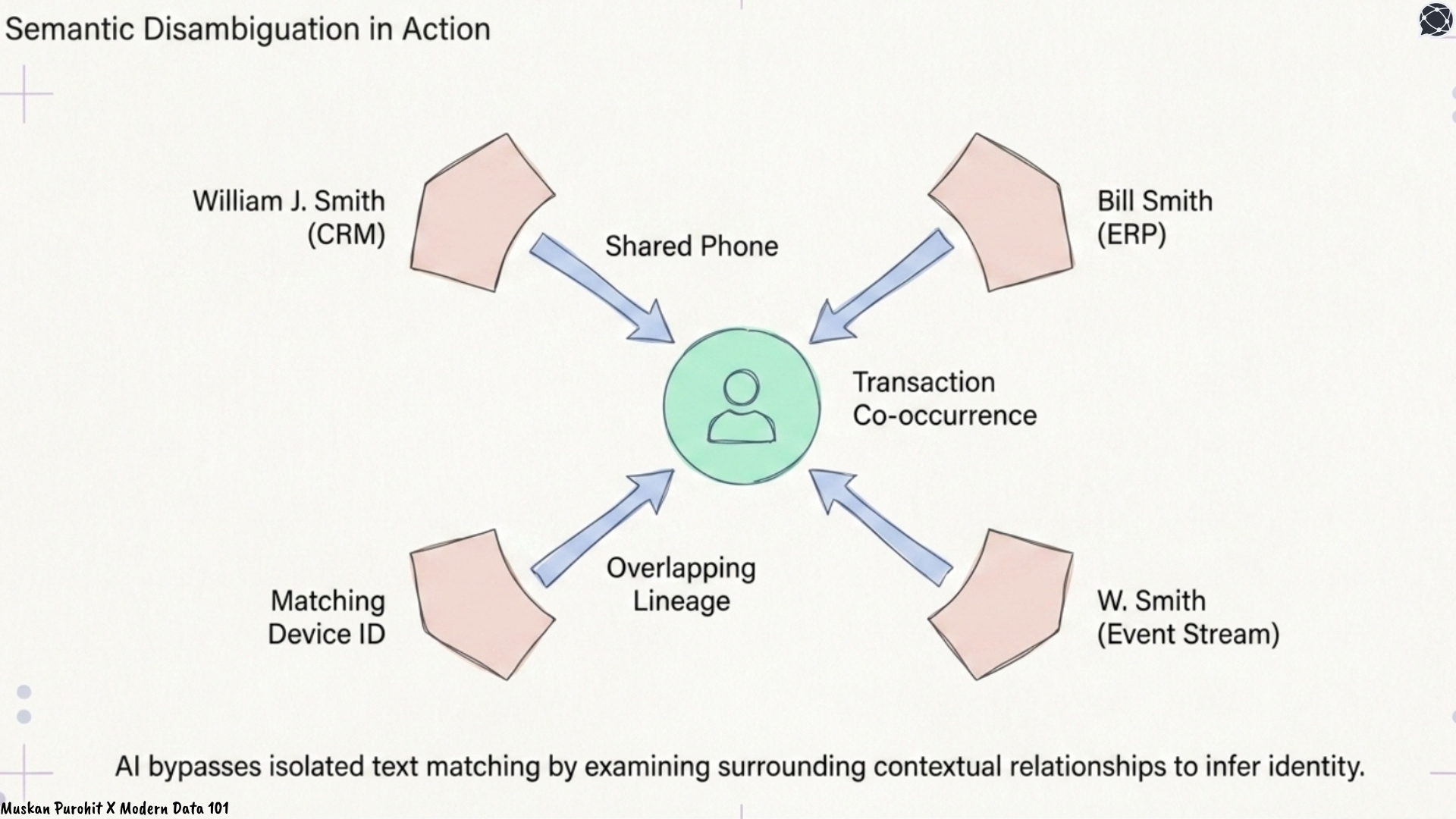
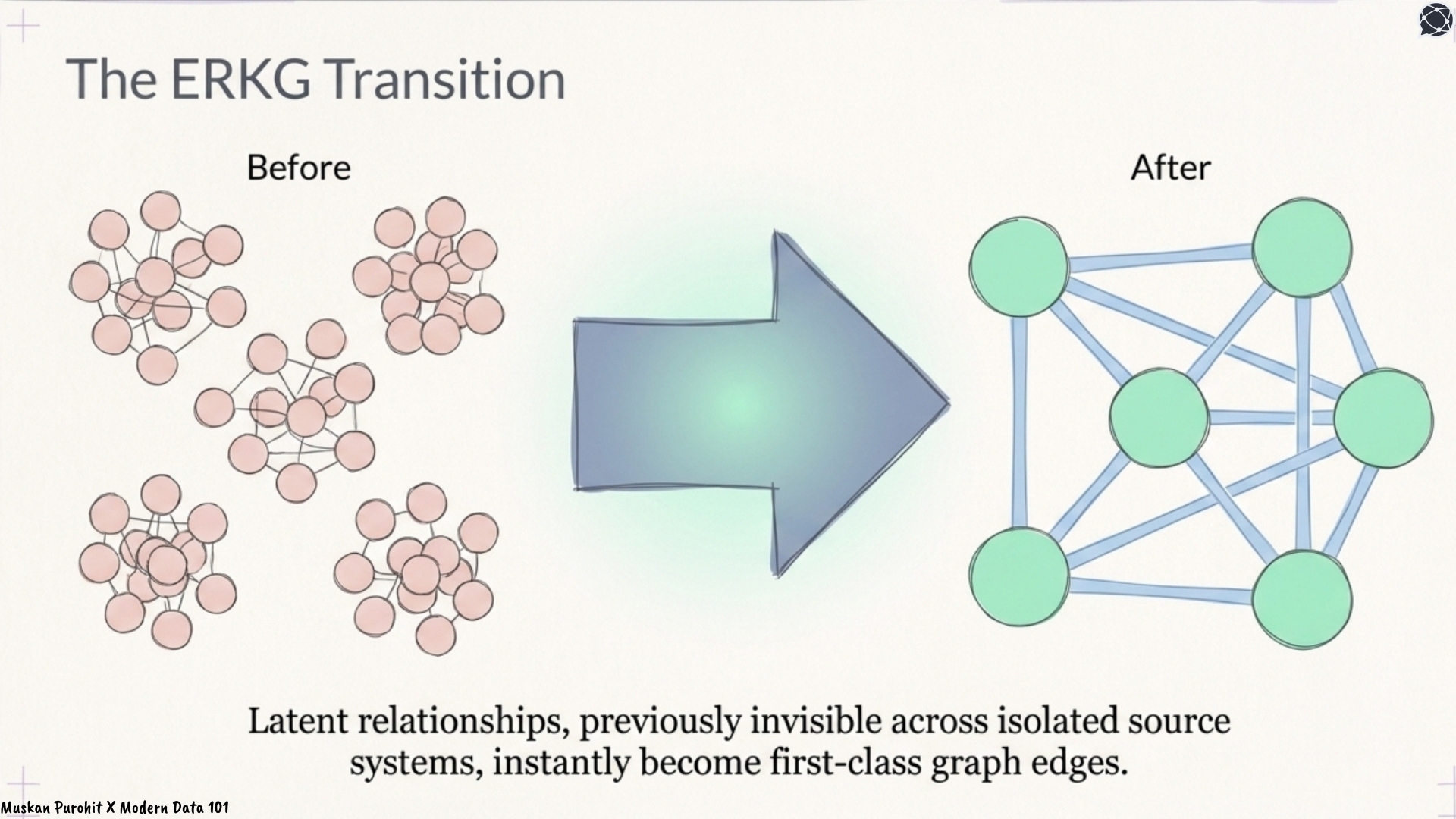
AI identifies individuals by analysing contextual relationships like shared phone numbers, instead of simple text matching.A knowledge graph, by definition, represents entities as nodes and relationships as edges. When you apply entity resolution before constructing the graph, duplicate nodes collapse and hidden connections surface. The result is an entity resolved knowledge graph (ERKG).
When entity resolution is applied first, duplicate nodes collapse and hidden connections surface. The resulting ERKG is structurally different: latent relationships that were invisible across source systems become first-class graph edges.
Additionally, the graph structure itself provides evidence for resolution decisions. If two apparently distinct records share neighbours such as the same employer, the same address cluster, or the same transaction counterparty, their proximity in the graph raises the probability that they are the same entity. Graph-based AI and entity resolution are, at their best, mutually reinforcing.
[related-2]
The downstream consequences of poor entity resolution are specific, and here is where they surface:
A resolved entity is only valuable if it carries its meaning forward. That requires a semantic layer: shared definitions, typed relationships, and organisational ontology that make resolved entities machine-interpretable across the AI data infrastructure.
This is where data products become architecturally relevant. When a Customer 360 or Supplier 360 is built as a governed, versioned data product, entity resolution is embedded into the product contract. The resolved identity travels with its lineage, confidence score, and source provenance, so AI systems consuming it don't need to perform ad hoc resolution upstream.
[related-3]
Most organisations are deduplicating when they should be resolving. Removing records feels clean. But AI it needs traceable data. Deduplication discards the provenance that RAG systems and agents depend on to reason with confidence.

Several practical questions arise when positioning ER within an enterprise AI architecture:
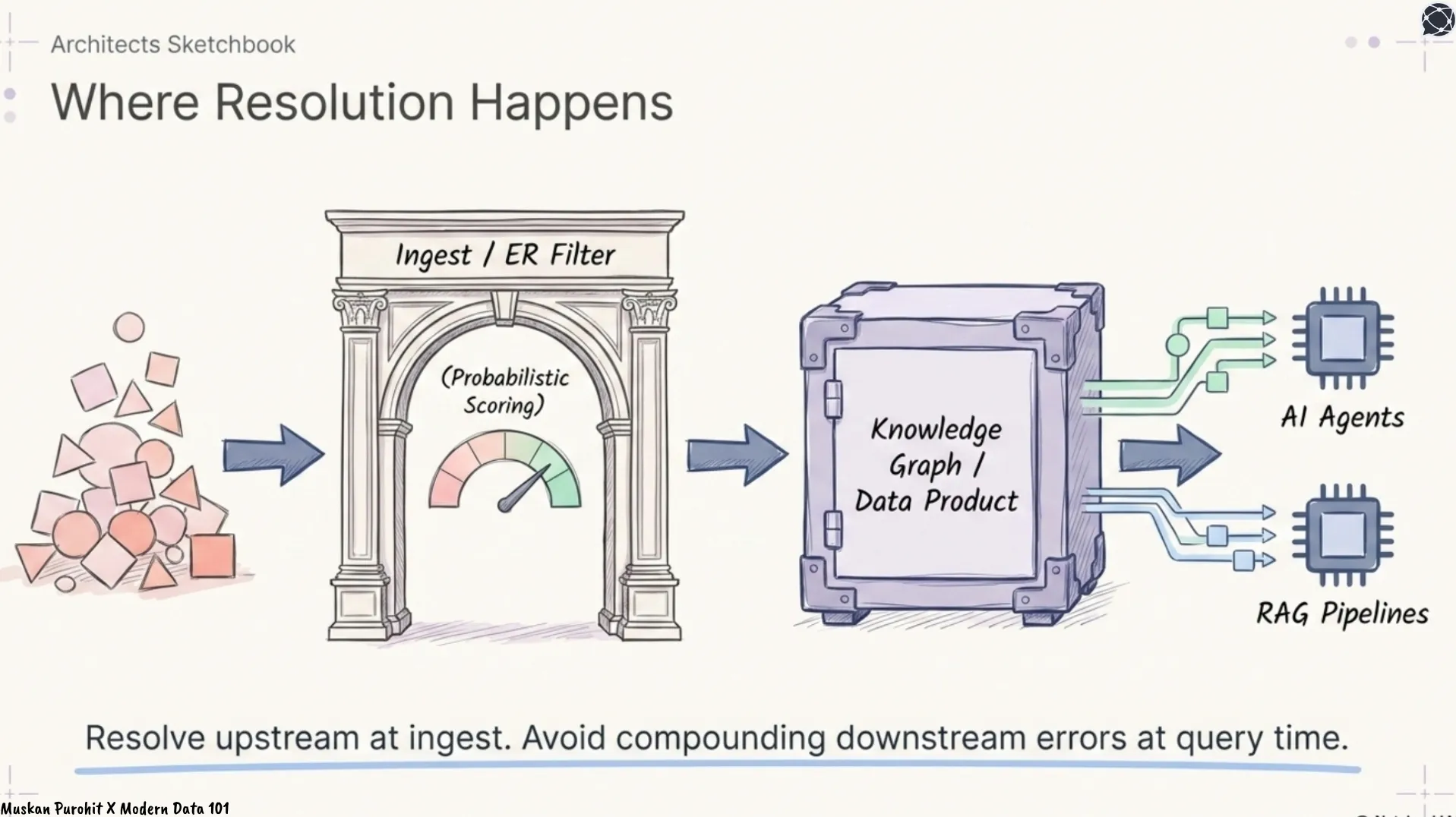
Where does resolution happen?
At ingest, not query time. Resolving entities before they enter a knowledge graph or data product layer avoids compounding downstream errors. Resolution is probabilistic, confidence scores should be preserved, not flattened to binary.
How does the graph feed back into resolution?
Treat the two as iterative. Graph analytics surface new evidence, shared relationships, unexpected proximity that refines resolution decisions in subsequent passes.
What about entities that change?
A static resolved graph degrades as companies merge, people change names, and structures shift. A graph continuously enriched by agents that detect new links is a fundamentally different proposition. Data deduplication vs. identity resolution. Deduplication removes redundant records. Identity resolution creates a canonical view while retaining source records with traceable provenance far more useful for AI applications.
As agentic AI systems take on increasingly complex multi-step tasks (cross-domain queries, compliance checks, automated supplier assessments, intelligent customer interactions), the quality of the entity model they navigate becomes a direct determinant of business outcomes.
The organisations building durable AI infrastructure are the ones treating entity resolution not as a data cleansing exercise but as an ongoing, architecturally embedded capability. Resolution confidence should flow into data product contracts. Resolved entities should propagate through semantic models. The enterprise knowledge graph should evolve, not fossilise.
AI is extraordinarily good at reasoning. It cannot, however, reason its way around a graph that misrepresents reality. Entity resolution makes the graph worth reasoning over.
Entity Resolution is crucial for finance, healthcare, e-commerce, and government sectors, enabling accurate data integration, fraud detection, and improved regulatory compliance.
AI-driven ER leverages machine learning to detect complex patterns, reducing false matches and missed links, delivering higher precision than traditional rule-based systems.
Regularly update data sources, implement robust entity disambiguation, and use automated validation to ensure your knowledge graph remains accurate and valuable for enterprise AI.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



