


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...




%20(1).png)
TABLE OF CONTENT



Today, businesses are building AI models left, right, and centre. But a crucial question often goes unanswered, "Are they building it to last?" AI landscape is vibrant, buzzing with pilot projects and innovative models. However, scratch the surface a little and you might find a worrying fragility.
Pipelines are tightly bound to individual models, the same features are painstakingly re-engineered from scratch for every new use case, and the path from a promising experiment to robust production remains stubbornly complex. The silent backbone of most Machine Learning models, feature engineering, is frequently the culprit.
A team is building a churn prediction model. They're spending weeks on extracting, transforming, and engineering features specific to that model/use case. Now another team wants to build a customer segmentation model. Guess what? They end up repeating a significant portion of that same data wrangling work, reinventing similar features because there's no central repository or standardised process to leverage what's already been done. This ad-hoc approach leads to a tangle of tightly coupled, poorly documented feature engineering pipelines.
The technical consequences are significant. Time is consistently lost in re-extracting and re-processing data that likely exists elsewhere in the organisation. Inconsistencies creep in as different teams implement similar logic in slightly different ways across various environments. This also inflates the cost and effort required for experimentation and iteration.
Strategically, this lack of reusable feature assets hinders model governance, making it difficult to track feature lineage and understand how changes impact different models. Ultimately, it stifles the ability to scale AI initiatives across the entire organisation, leading to frequent "AI fatigue" as teams grapple with constant reinvention and struggle to demonstrate a strong return on their AI investments.
The inability to scale AI efforts effectively stems from the fundamental oversight: the data layer. The data layer is either ignored or treated as a byproduct of individual model development. We need a paradigm shift. Features are too often treated as throwaway pre-processing steps when they should be valuable data products in their own right.
After all, what is feature engineering if not high-quality data management? Why manage data repeatedly or accept subpar quality when features can be treated as first-class citizens in the data ecosystem? Features as data products ensure that data used for machine learning or AI gets the attention and is put through a quality management lifecycle at scale to ensure consistent usability by multiple teams.
When we begin treating features as products, a powerful transformation occurs. They become discoverable, versioned, and inherently reusable. Given the volume, data products have become a crucial aspect of feature engineering methods. Think about APIs in software development. Well-defined contracts and interfaces allow different applications and services to communicate freely. Likewise, well-defined feature products too require contracts, interfaces, and clear lifecycle ownership, ensuring they are maintained, reliable, and evolve appropriately.
[related-1]
So, what does a reusable feature look like? An ideal reusable feature is domain-agnostic. Meaning, it should not be tightly coupled to a single model or use case that adapting to changing requirements (which happens often) seem impossible. It needs well-defined inputs and outputs, which makes it super easy for different teams and systems to understand how to use it. Lastly, these features must be stored in a central registry or platform for ease of access.
That's exactly where shareable data products come into play: one of the most enriching data design approaches that serves as a top-notch suite of MLOps tools. When feature extraction logic is decoupled from the specific ML model, we create an independent asset that teams can "plug and play" into their workflows. This reduces redundancy. A number of key enablers facilitate this shift. Besides, a Feature store serves as a medium for storing, managing, and serving features.
Data Products are notably becoming a key aspect of MLOps best practices and boosting common feature engineering techniques. A data product platform essentially duals as an MLOps platform today. Having said that, the technology alone isn't enough, it must be coupled with a Product culture, where clear ownership, comprehensive documentation, and defined reliability SLAs are established for the features.

Getting there is a journey. From ad-hoc to reusable feature assets, it is a gradual process. Here are some step to consider to make it an easy one for you:
Start with identifying the "commons." Obviously there will be features that are frequently repurposed across multiple models or are likely to be valuable for future AI initiatives. Common examples include customer segments, lifetime value (LTV) buckets, and churn risk scores. Find that wheel and stop reinventing.
[related-2]
Instead of embedding feature engineering code directly within individual model training scripts, move this logic to centralised, well-tested pipelines. This makes the extraction process independent and reusable.
Establish clear responsibilities for the maintenance of each feature asset. This can include ensuring data quality, updating the feature if underlying data sources changes, and managing its versioning and testing procedures.
{state-of-data-product]
Creating a catalog or enabling access through the data product marketplace with appropriate feature tags ensures high-impact ease for data scientists and ML engineers, where they can easily discover available features. Implement comprehensive metadata tagging, including the feature's definition, inputs, outputs, and use cases where it has already been successfully applied.
Monitor which models are consuming which feature. Based on this insight, one can quantify benefits such as: time saved in development of new models or improvements in model performance due to consistency of feature definitions.
There can be multiple strategic advantages of embracing reusable feature assets including:
While the benefits are clear, let's see if the path to reusable feature assets is smooth or has some stumbling blocks:
Don't try to build a massive library of reusable features upfront. Start with the most frequently used, highest-impact features and iterate based on actual demand.
A feature store is a powerful enabler, but it's not a substitute for a well-defined strategy, clear ownership, and robust governance processes around your feature assets.
Features are a durable asset of a business. With regular care, maintenance, and investment, the quality, relevance, and freshness of features remain aligned with the growing needs of the business.
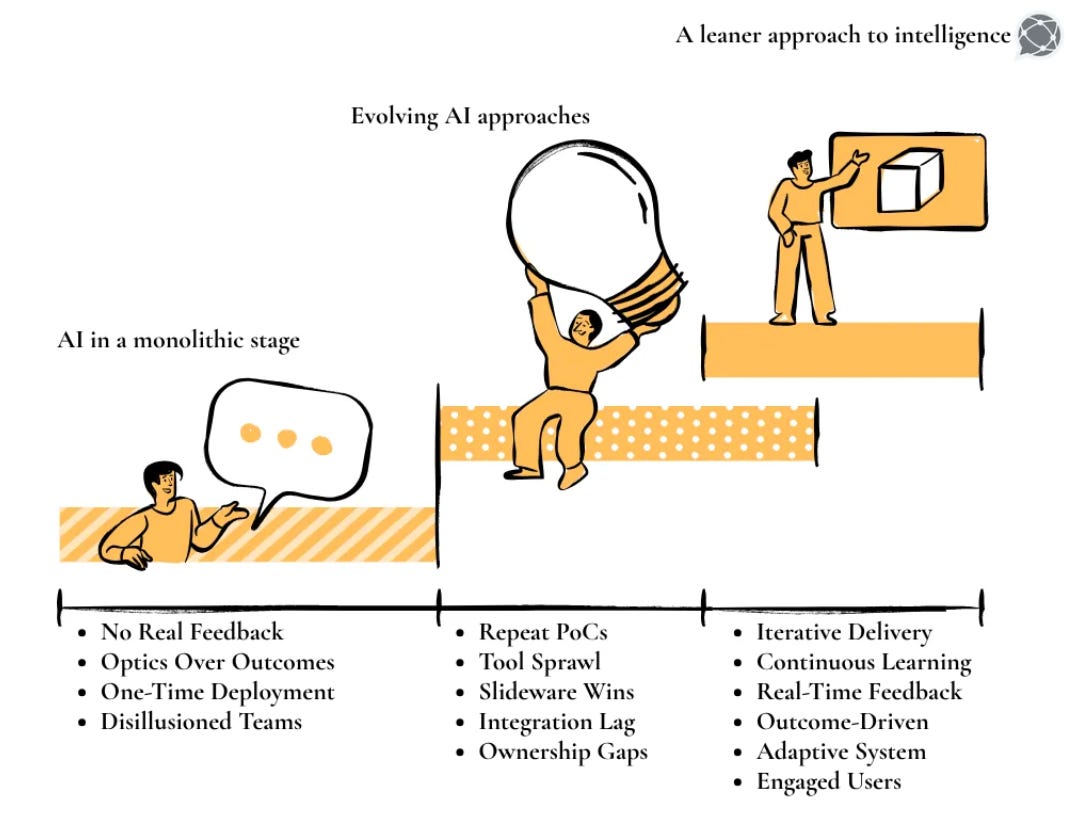
AI maturity is not about developing an overly complex or fancy model that barely moves the needle. True advancements lie in building a robust, structured foundation for how we manage and leverage our data. The future of scalable and efficient AI is modular that is built on a foundation of reusable components rather than monolithic, siloed pipelines.
Bottom line: Start treating feature engineering for machine learning as a key business strategy for ROI, value, and consistent usability for multiple teams. Treat your features as the valuable, reusable data products they are. It's not just a best practice; it's the only sustainable path to unlocking the full potential of AI across your organisation.
A feature store is a system to store and serve features consistently, while reusable features are what we can term as the actual engineered data elements. Reusable features can also be thought of as reusable assets, and a feature store can be thought of as a platform aimed at discovering, managing, and serving them reliably.
Teams prioritise features that are used to improve upstream data quality, used in multiple models, as well as the core business logic. A good rule here is to reuse features that come with stable definitions, expansive applicability, and a clearly outlined business proposition.
This is not necessarily true. Yes, building usable features takes more effort, but it significantly cuts down repeated work later on. In fact, this upfront investment boosts the pace of experimentation by offering tested and consistent building blocks, minimising quality issues and bugs, often notorious for slowing models down.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



.avif "Brij Mohan Singh")
