


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)

.png)
TABLE OF CONTENT



Organisations today are under relentless pressure from rising costs, broken workflows, outdated systems, and customers who expect more than ever. Incremental fixes no longer cut it. Business Process Reengineering (BPR) offers something bolder: a fundamental rethink of how work gets done. But in a world drowning in data, redesigning processes without a clear data strategy is building on sand. Infact, intial studies on BPR mentioned around 70% of these initiatives fail during implementation, largely due to poor planning and unrealistic expectations.
This article explores BPR, its principles, its modern relevance, and why data products are quietly becoming the difference between transformation that sticks and transformation that fades.
[playbook]
Business Process Reengineering is the fundamental rethinking and radical redesign of core business processes to achieve dramatic improvements in performance, cost, quality, speed, and customer experience. Unlike continuous improvement methods that refine what already exists, BPR asks a more disruptive question: if we were building this process from scratch today, would we build it this way? The answer, almost always, is no.
The concept was designed for organisations willing to challenge their own assumptions, to discard legacy thinking and redesign the way value actually flows through the business.
But here's what often gets missed. A process is only as intelligent as the information feeding it. When you redesign how work gets done, you are, whether you realise it or not, also redesigning how data moves, where it lives, who owns it, and what decisions it enables. The most successful reengineering efforts treat each core process as something that should produce reliable, reusable outputs that other teams, systems, and decisions can depend on without having to question their quality or origin.
That shift in thinking changes everything: processes stop being isolated pipelines and start becoming interconnected systems that generate real organisational intelligence.
We might not have looked at BPR from the data POV, but today this cannot be ignored! This is largely because most organisations are now data-enabled or data-driven, and behind every minor and major process modification and change management step, data has started playing the central character.
Processes are ultimately powered by how data is created, shared, and used across systems and teams. When organisations redesign processes without addressing the data behind them, several issues arise.
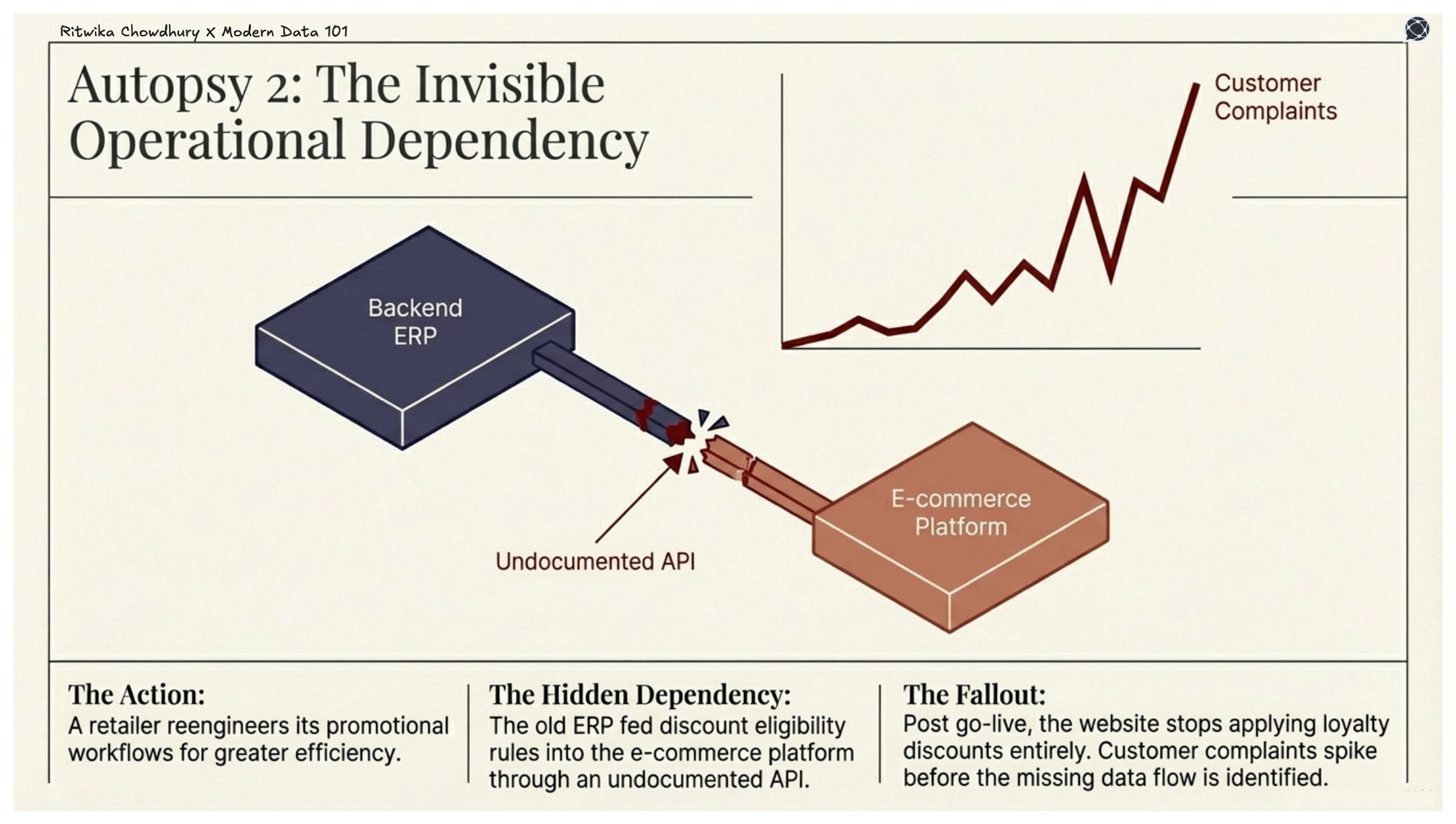
A large section of the challenges of implementing BRP, as discussed, are often data problems, exposed by process redesigning. And this is precisely where most BPR initiatives hit a ceiling because the information layer underneath it was never designed at all.
This is the gap that data products fill. So why should you consider using data products when dealing with data problems of BPR.
Every data product is built to cater to a specific business problem or purpose, involving outcome-first modelling where the business goal is set as a north star and the rest of the pieces are assembled around it. In BPR terms, this means every piece of information entering a reengineered process has a clear reason to exist, eliminating the noise that makes process diagnosis unreliable.
A data product approach means identifying the consumer and their problems before kickstarting any effort, mapping all data work to specific business goals, metrics, and challenges. BPR fails when redesigned processes serve internal technical logic rather than actual users. Data products force the opposite discipline from the start.
The objective is to build a product that can tend to novel queries at the speed of the business, consistently understanding the pulse of metrics and tracing back to deep-seated opportunities and risks. This is precisely what BPR’s continuous iteration phase needs.
One of the primary pillars of data products is data quality, enforced through data contracts at multiple endpoints. In BPR, KPIs and process metrics are only credible when the information feeding them is contractually guaranteed to meet quality standards instead of being hoped to be correct.
The legacy migration problem becomes manageable when the data is owned. Every field, every transformation rule, every business logic embedded in an old system has a named steward responsible for it. Migration stops being an archaeological dig through undocumented pipelines and becomes a structured handover between accountable owners. Think of a retailer is this scenario. His missing loyalty discount flow would have been a defined output of a governed data product, with known consumers, tested interfaces, and a clear audit trail.
[state-of-data-products]
The marketing domain of a company could give out one of the clearest instances where Business Process Reengineering either succeeds dramatically or quietly fails. The reason is simple: modern marketing is often a measurement problem.
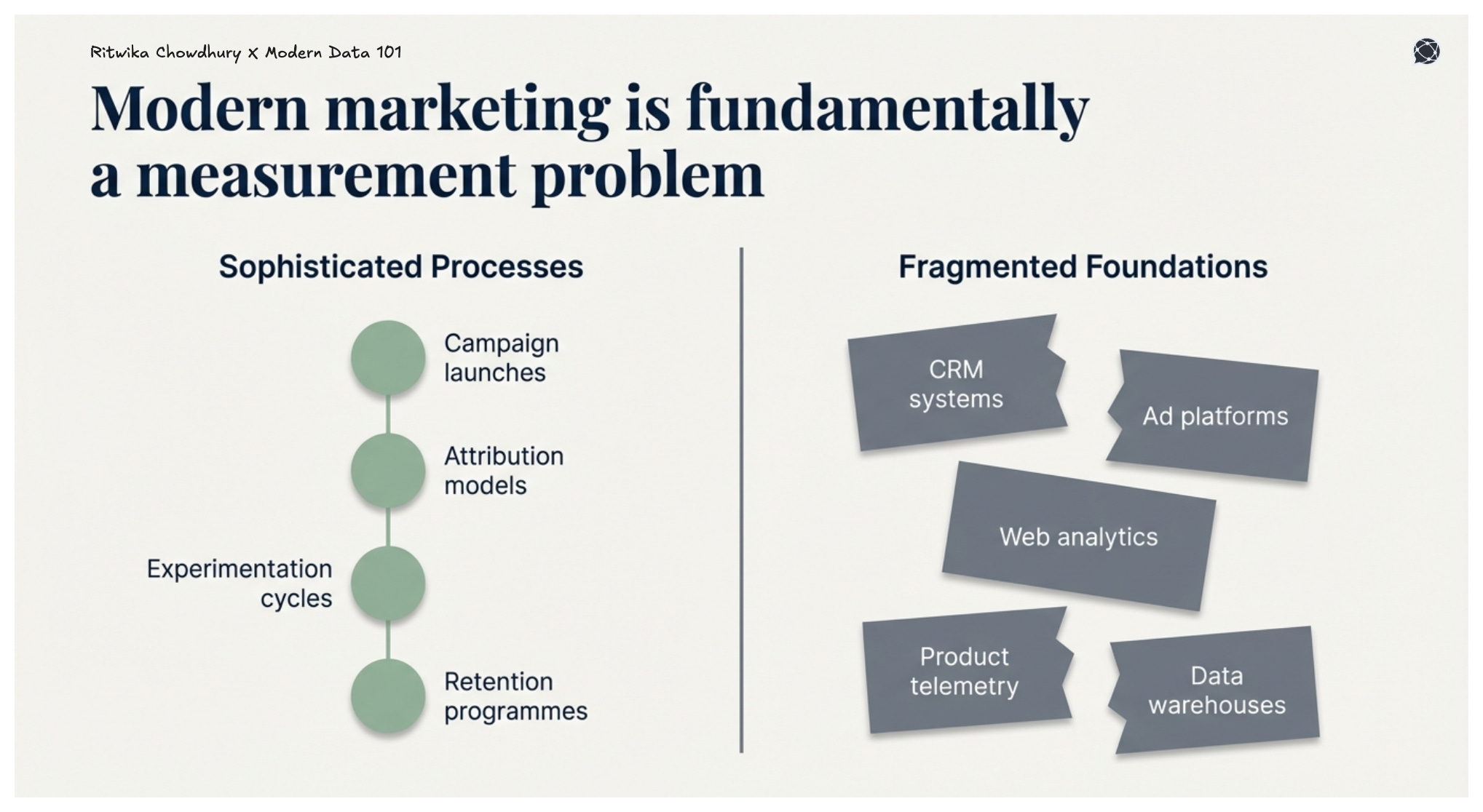
Most marketing teams already run sophisticated processes like campaign launches, attribution models, experimentation cycles, and retention programs. But the information layer beneath these processes is usually fragmented across CRM systems, ad platforms, web analytics, product telemetry, and data warehouses.
[related-1]
When organisations attempt to redesign marketing processes, such as moving to experimentation-led growth, lifecycle marketing, or product-led acquisition, they quickly discover that data is a bigger constraint in the process.
This is where data products fundamentally change the equation.
Imagine a Growth Intelligence Data Product designed specifically to support the reengineered marketing process.
Instead of raw tables from ad platforms, CRM exports, and product analytics tools, the data product exposes governed, metrics-ready interfaces such as:
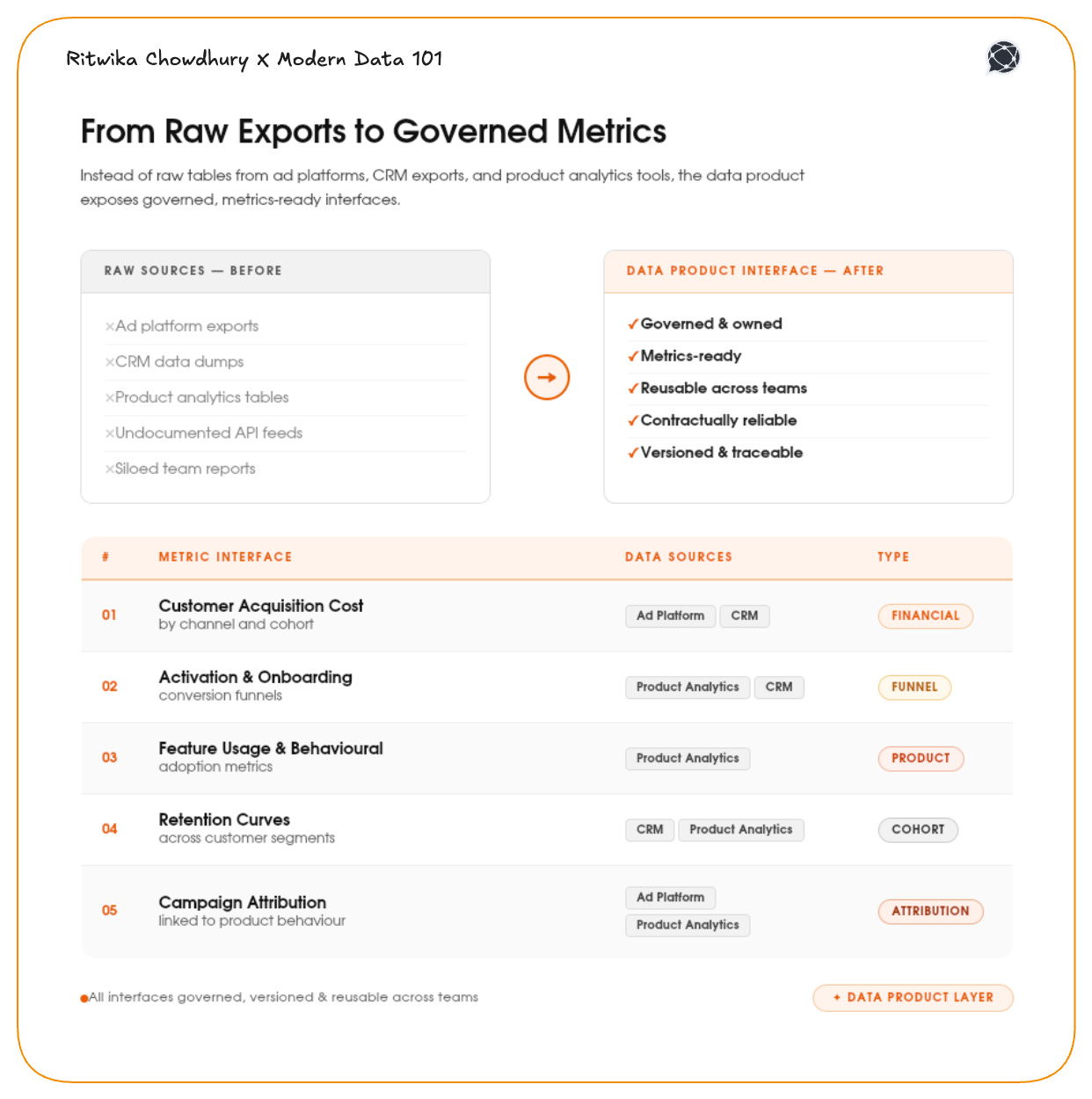
These are structured, governed outputs of a product designed to power marketing decisions.
The data product is modelled around growth questions instead of data sources.
‘Which acquisition channels drive long-term product usage?’ ‘Which onboarding paths lead to higher retention?’ ‘Which campaigns generate customers who actually adopt core features?’
This outcome-first modelling aligns perfectly with a reengineered marketing process where experimentation and iteration are central.
Today's marketing increasingly depends on usage analytics, understanding how customers interact with the product after acquisition.
A marketing data product integrates behavioural signals directly into growth metrics. Feature adoption signals feed lifecycle campaigns. Product usage drives segmentation for retention strategies. Engagement metrics trigger automated experimentation loops
In other words, the marketing process extends into the product itself.
[related-2]
Because the data product exposes metrics as governed interfaces, marketing teams can run rapid experimentation cycles, launch campaigns, observe acquisition cohorts, track behavioural adoption signals and adjust targeting, messaging, or onboarding
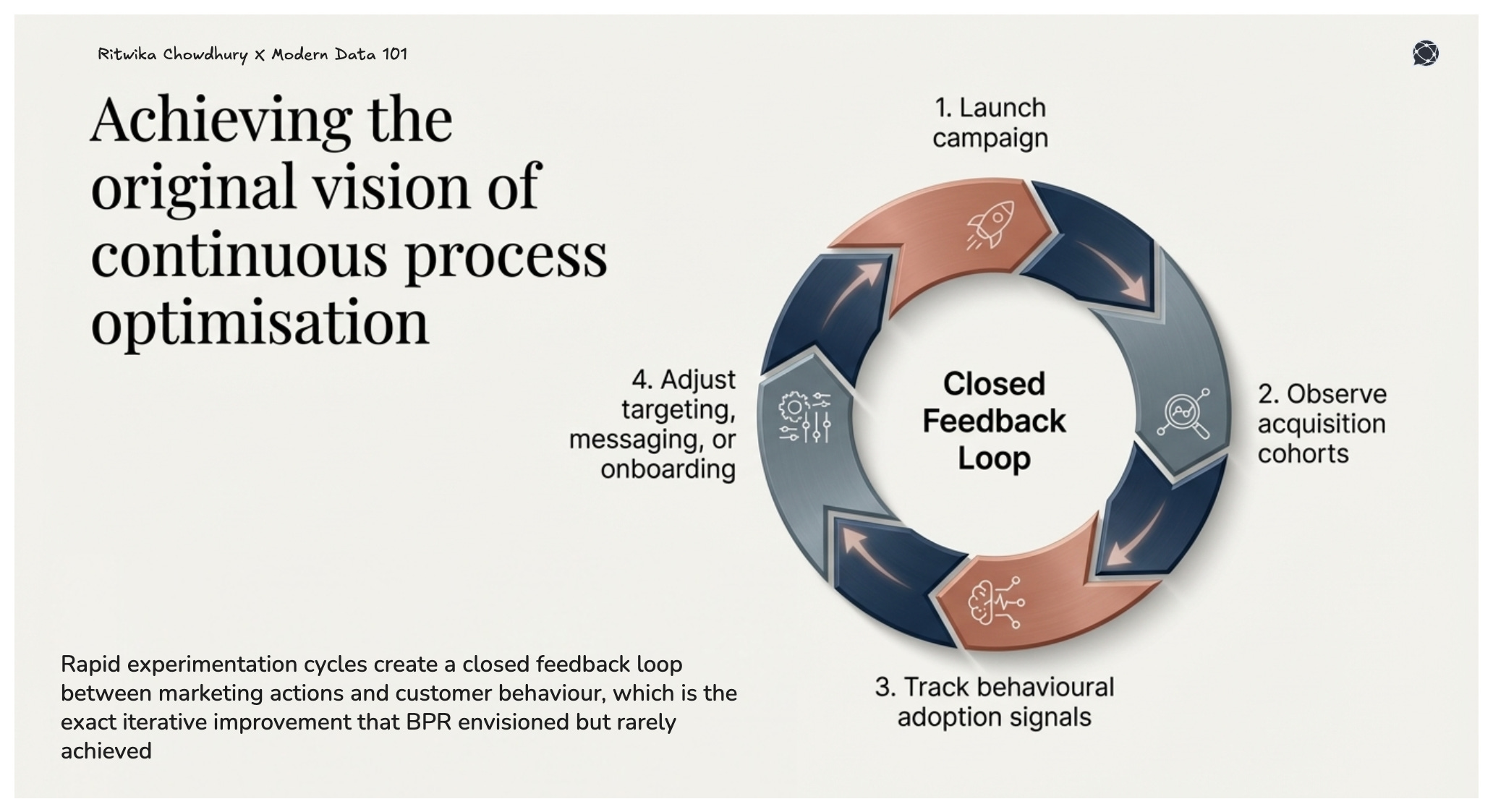
This creates a closed feedback loop between marketing actions and customer behaviour, exactly the type of iterative improvement that BPR originally envisioned but rarely achieved.
Most marketing analytics efforts collapse under inconsistent definitions. CAC is calculated differently across teams, conflicting attribution models, and inconsistent definitions of “active user.”
A data product resolves this by publishing metrics as contractual outputs. CAC, activation, retention, and feature adoption become trusted interfaces rather than disputed calculations. When marketing leaders can rely on the numbers, decision cycles accelerate.
From the instance, we deduce how a marketing data product creates infrastructure that is future-proof.
Campaign teams, lifecycle managers, growth engineers, and product teams all interact with the same governed metrics layer. Experiments can be launched faster, insights travel instantly across teams, and process redesign becomes sustainable because the underlying information layer finally supports it.
Hence, the reengineered marketing process stops being a fragile set of workflows and becomes a continuously learning growth engine powered by data products.
None of the orgs want AI to become a liability for them, which is perfectly why data products make one of the best solutions to BPR challenges along with amny others.
When an organisation reengineers a process and then deploys AI on top of it, any ambiguity in the data layer becomes an AI decision risk. Regulators, auditors, and customers increasingly want to know why an AI made a specific decision. If the data feeding that decision is undocumented, unowned, and ungoverned, there is no defensible answer. Data products make AI explainability structurally possible rather than a retrospective scramble.
Not to miss on the fact that LLMs and AI agents need semantic clarity.
This is the part most organisations are underestimating right now. It is not enough for data to be technically present and formatted correctly. For AI to reason over it, the data needs to carry meaning, what does "activated user" mean in this organisation? What counts as a "closed deal"? Data products enforce that semantic layer. They are where business definitions live, get versioned, and get inherited by every system consuming themm including AI systems.
Process reengineering is the fundamental redesign of business processes to improve performance, efficiency, and outcomes. It involves rethinking workflows, roles, and technologies from the ground up rather than making incremental improvements to existing processes.
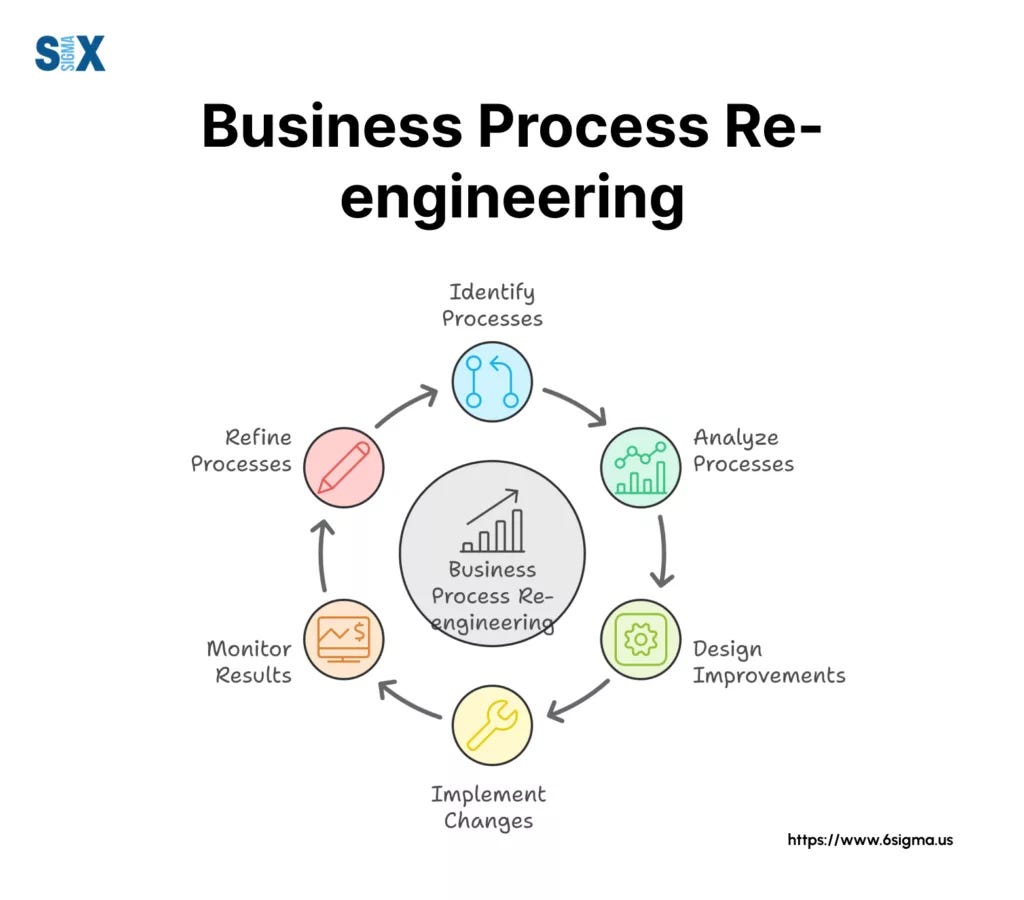
Business Process Reengineering typically follows five stages: identify processes for redesign, analyse existing workflows, redesign the process for desired outcomes, implement the new process with supporting systems, and continuously monitor and optimize performance using defined metrics.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



