


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)




TABLE OF CONTENT


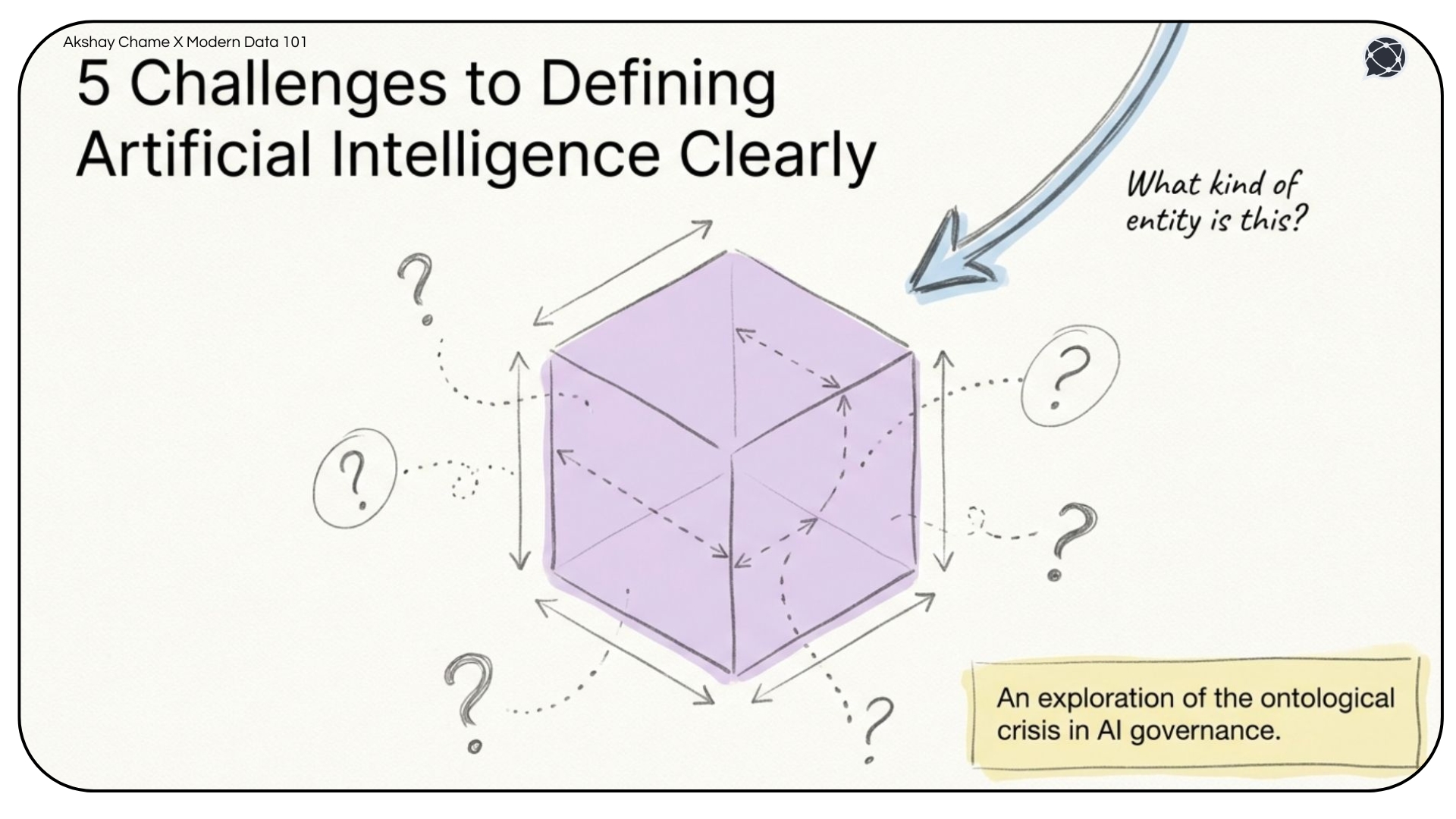

Before you can govern, regulate, or hold anyone accountable for artificial intelligence, you must answer a foundational question that almost nobody is asking: What is AI, really? Not just in technical or product terms, but basically, in the philosophical sense: what kind of thing is artificial intelligence?
This is the domain of ontology: the study of what things fundamentally are.
Yet when it comes to artificial intelligence, no benchmark, regulation, or technical standard has resolved this question. We still lack a stable, coherent account of what AI actually is.
The following article maps five challenges that make building that account so difficult.
"AI" has never meant one thing; The category "artificial intelligence" has no single, stable, agreed-upon definition.
💡Academic researchers define AI functionally. Marvin Minsky's foundational framing put it plainly: "the science of making machines capable of performing tasks that would require intelligence if done by humans.”
The EU AI Act calls it "a machine-based system designed to operate with varying levels of autonomy." But the U.S. National AI Initiative Act of 2020, section 3(3) makes a different approach, defining AI as a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations, or decisions influencing real or virtual environments.
This serves as a structurally distinct formulation centred on objectives and outputs rather than autonomy and inference.
In practice, the boundary shifts constantly. Spam filters, product recommendations, and OCR were all once heralded as AI. Today, they are invisible infrastructure, so whatever normalises exits the category, and whatever is novel enters it. The ontology expires as fast as you build it.
[playbook]
This becomes a structural problem rather than just being an inconvenience for anyone trying to classify, govern, or reason about AI systems.
[related-1]
Even where a definition exists, individual AI technologies have a well-documented tendency to become so familiar that they stop being perceived as AI at all. This is sometimes called "the AI effect” because with time, the oversight quietly evaporates.
Playing chess at a grandmaster level was AI until Deep Blue. Machine translation was AI until it became a browser feature. When a technology normalises, it typically exits the governance and scrutiny structures built around it. This is because it gets reclassified as software, as automation, as infrastructure.
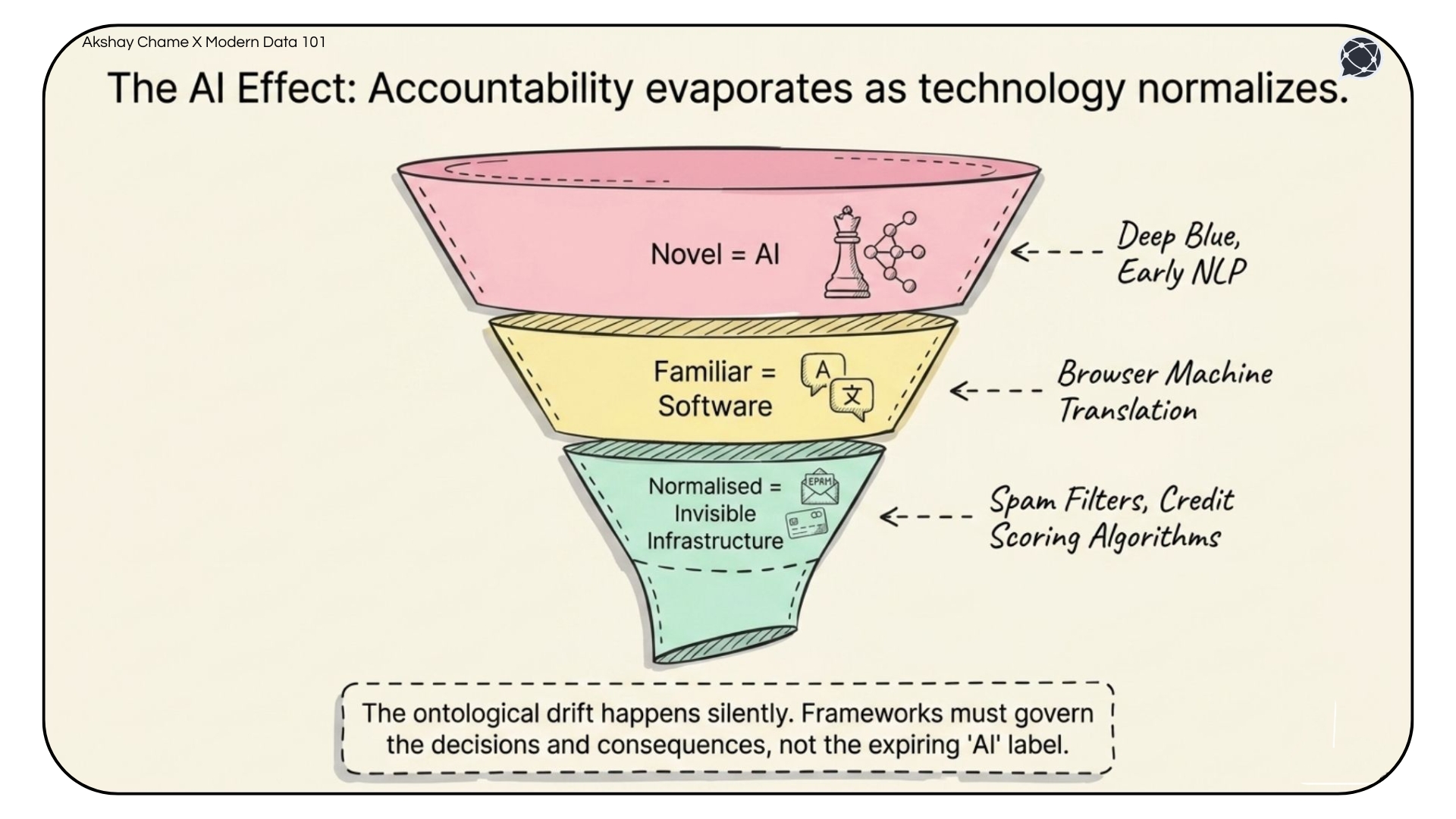
This matters as the reclassification does not change what the system does. Credit scoring algorithms use statistical techniques that originated squarely in AI research. Today, these systems are often treated like operational software, even though they influence who gets access to credit and housing for millions of people. The ontological drift happens quietly, and over time, the structures meant to ensure accountability begin drifting as well.
The practical implication: any framework for governing AI needs to govern the decision and its consequences, not merely the label applied to the system producing it. Reason being: Labels expire, but consequences don't.
[related-2]
The third challenge is tied closely to human psychology and anthropomorphism: people naturally assign intention, emotion, and agency to systems that do not actually possess those qualities.

This tendency is widely documented across cultures and appears even among technically informed users. Language models intensify the effect because they are designed to produce responses that feel natural, contextually adaptive, and socially coherent.
A few characteristics make this especially difficult to avoid:
Over time, people can begin treating statistical systems as though they possess judgment, motives, or awareness. The policy implications become significant at that point because accountability discussions can shift away from the humans who build and deploy these systems toward regulating “AI behaviour” itself. Approaches such as semantic modelling help counter this by explaining what a system is actually doing beneath the interface rather than reinforcing what it merely appears to be doing.
[related-3]
Hawley's original paper focused on classification: what AI is. But a closely related and equally unresolved question is about what it does: at what point does a system cross the line from executing instructions to making decisions?
.jpg)
This is the agency problem, and it has no clean answer. Just like a calculator executes, a chess engine selects, and an agentic AI system plans, delegates sub-tasks, and adjusts its strategy in real time based on environmental feedback. But what is that?
Three foundational thinkers have staked out positions that remain in direct tension:
Why does this matter ontologically? Because the attribution of agency is precisely what triggers moral and legal responsibility. Not being able to determine with clarity whether an AI system is an agent or a tool, we cannot determine who is responsible when it causes harm: the system, the deployer, the developer, or the user who gave the instruction. AI readiness frameworks that treat this question as settled are building on an unstable foundation.
[related-4]
A philosophical extension grounded in three foundational debates in the philosophy of mind.
The fifth challenge cuts deepest: does the physical substrate on which a computation runs affect what that computation is? Three positions define the debate, and none has won!
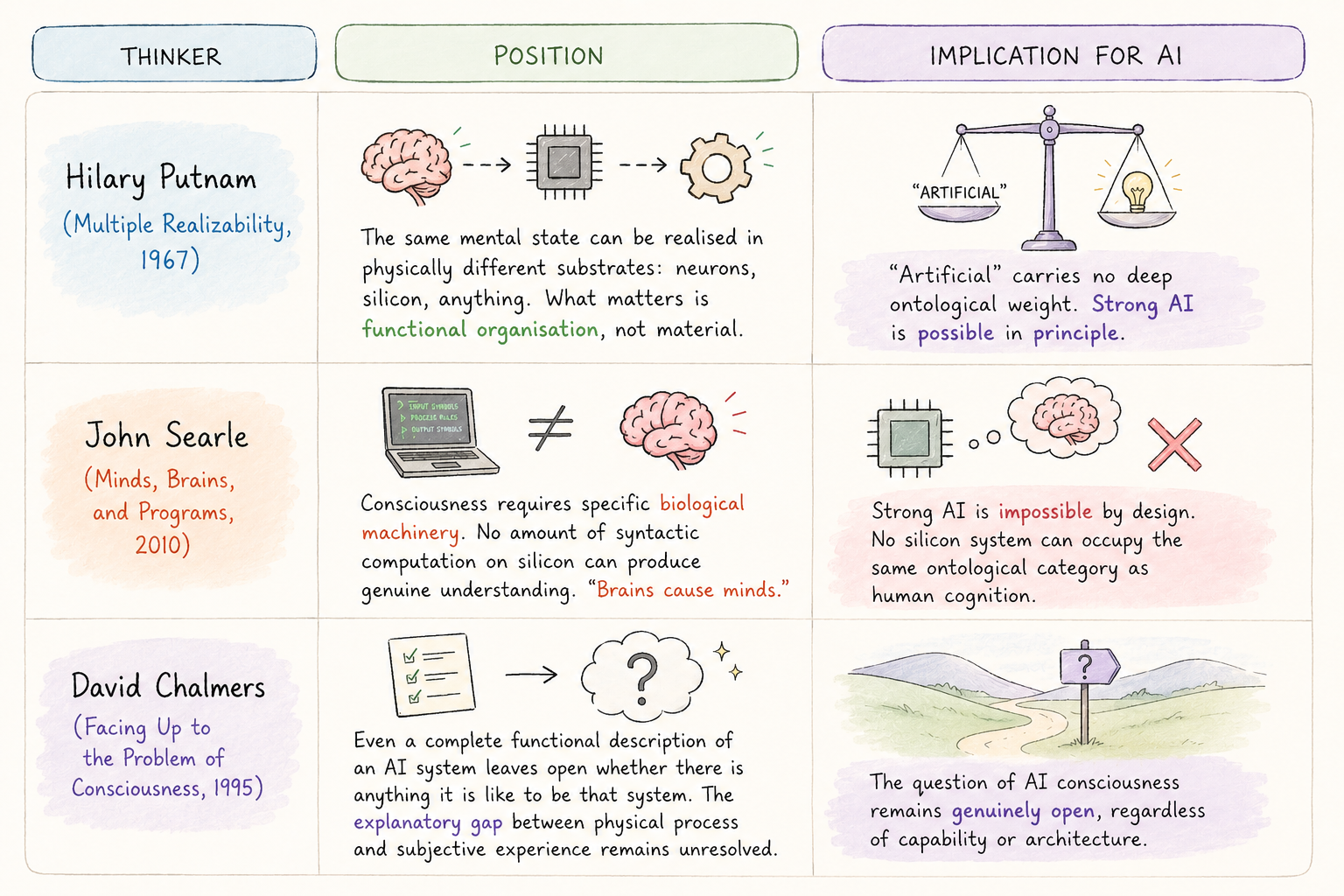
Thinkers: Hilary Putnam, John Searle and David Chalmers
Each position draws a different ontological boundary around AI. Together, they make one thing clear: an ontology of AI that does not acknowledge this unresolved foundation is claiming more certainty than the philosophy warrants. As data modelling and semantic systems grow more sophisticated, the substrate question will surface with increasing urgency in design choices that currently go unexamined.
.jpg)
The challenges of AI ontologies are deeply interconnected. Issues like unstable definitions, shifting categories, distorted intuitions, unclear accountability, and the fundamental nature of AI all hinder effective governance.
Addressing one challenge alone is not enough; real progress requires a cross-disciplinary effort among philosophers, engineers, legal scholars, and data governance practitioners. Ultimately, understanding what AI is proves as difficult and arguably more urgent than building it.
1. What is the difference between AI governance and AI ethics?
AI ethics is about the guiding values and principles that AI systems should follow such as fairness, respect for privacy, and non-discrimination. In contrast, AI governance involves the concrete processes, oversight mechanisms, and organisational structures that ensure these ethical principles are actually implemented and enforced throughout the AI lifecycle.
2. Why does AI need an external ontology if it’s so smart?
Large Language Models and similar AI systems generate responses by identifying patterns in data, not by truly understanding the concepts they discuss. External ontologies provide structured, foundational knowledge, helping AI systems avoid inconsistencies and hallucinations, especially in fields where reliability and accuracy are critical.
3. How are businesses dealing with this lack of a fixed category?
Businesses increasingly adopt “Ontology-First AI,” anchoring AI outputs to carefully structured domain knowledge and business logic. This ensures that AI-generated information is accurate, consistent, and aligned with specific organisational needs, reducing the risk of misinterpretation or misinformation.
4. What should be done to improve accountability?
Improving accountability in AI involves maintaining clear documentation, establishing traceable audit trails, conducting regular impact assessments, and ensuring ongoing human oversight. Incorporating ontologies and transparent mechanisms for decision-tracing further clarifies responsibility and supports trustworthy AI deployment.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


