


Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...





TABLE OF CONTENT


%20(1).png)

Vector representations became the default foundation for enterprise AI between 2022 and 2024: fast to deploy, easy to scale, and effective for straightforward Q&A. But when applied to reasoning-heavy tasks like compliance analysis or cross-domain relationship mapping, outputs appeared plausible without being logically correct. The problem is representational: vector embeddings compress meaning into numeric space where similarity is statistical, not structural.
.png)
High cosine similarity does not guarantee contextual relevance. A query like “Java” in a technical corpus may surface both the programming language and the island because both occupy adjacent regions in embedding space, despite representing entirely different concepts.
[report-2025]
These are structural edge-case limitations.
.png)
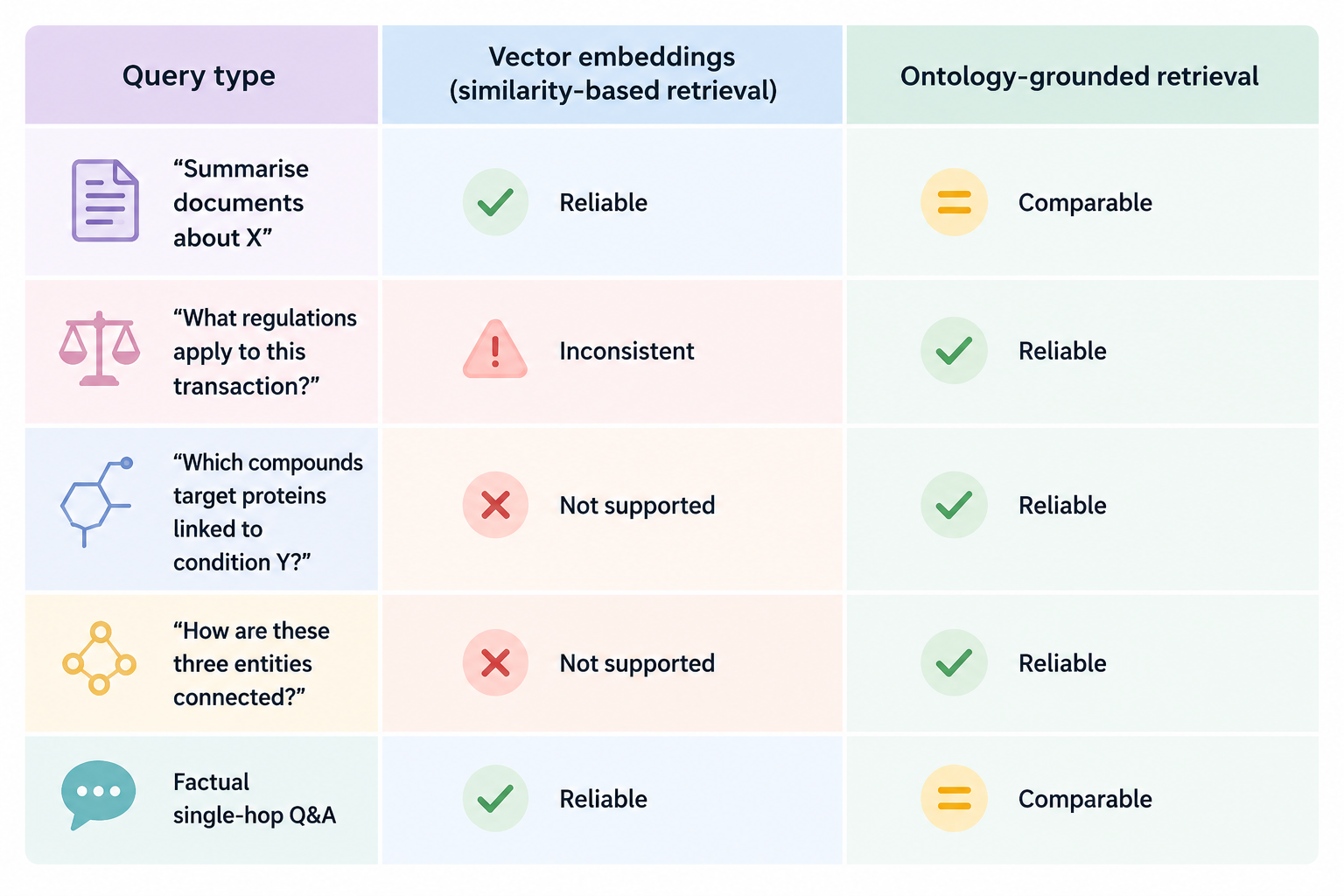
An ontology is a structured representation of a domain that defines entities, their types, and the relationships between them. Instead of representing meaning as proximity in vector space, it encodes meaning as explicit, typed connections between concepts. For example, a drug is linked to a target protein, which connects to a disease through defined biological pathways.
Unlike embedding space, ontology-grounded retrieval follows typed entity relationships step by step, making it structurally suited to queries that imply a chain:
[related -1]
Multi-hop queries, those requiring information connected across multiple entities, are where vector retrieval breaks down in production.
A concrete case: A pharmaceutical team evaluating whether a compound can be repurposed must integrate information across multiple layers. The answer spans multiple datasets and entities, each connected through a defined dependency chain.
A 2025 PMC study (Han X et al.) showed that large-scale drug knowledge graphs can efficiently surface multi-step repurposing pathways at scale.
Vector retrieval fails here for a structural reason: Each chunk is independent of the others, with no structural awareness of how the underlying entities relate. The model is then asked to reason across implicit connections that the retrieval layer has made no attempt to surface.
The ontology defines the domain's entity types, named relationships, and constraints on valid reasoning paths. A query follows typed edges in a structured graph. Each hop is constrained by the schema, which means:
Because the retrieval context is already structured around domain logic, the model fills fewer gaps: OG-RAG's 40% improvement in answer correctness reflects the same model performing better on better-grounded input.
.png)
OG-RAG was evaluated across four LLMs on domain-specific reasoning tasks, compared against conventional RAG and graph-based baselines on identical datasets.
.png)
Benchmarks confirm the gap: a Lettria/AWS implementation (December 2024) reported 86% accuracy versus 32% for standard RAG on an enterprise corpus, and selectively combining RAG with GraphRAG improved QA accuracy by up to 6.4 percentage points on the MultiHop-RAG benchmark (Han H. et al., Llama 3.1-70B).
OG-RAG figures were measured on structured domain-specific tasks. Validate against your own query distribution before architectural decisions.
[state-of-data-products]
.png)
[related-2]
.png)
[related-3]
Vector embeddings will remain part of most serious AI stacks: as a component of hybrid systems but not the primary reasoning layer. Retrieval architecture is increasingly becoming a balancing act between structure and approximation. The real challenge is deciding where relationship-aware reasoning is necessary and where semantic similarity alone is still practical, and recent benchmarks are finally making those boundaries much clearer.
Q: Do I need a pre-existing Knowledge Graph for GraphRAG?
A: You do not need a pre-built knowledge graph to use GraphRAG. Current pipelines can automatically generate knowledge graphs from your existing unstructured data using AI models. This enables rapid deployment without manual graph engineering.
Q: What tools are used to build these ontologies?
A: Specialised tools like BootOX, Karma, LogMap, and D2RQ help convert raw data into formal ontology formats such as RDF or OWL. These tools streamline mapping and integration across different data sources. They support efficient ontology creation and maintenance.
Q: Why does Vector RAG fail on complex queries?
A: Vector search typically loses the logical structure and relationships between entities. This means it can miss connections needed to answer multi-step or reasoning-based queries. Graph-based retrieval preserves these links for more accurate results.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



