



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

%20(1).png)
.png)

.png)
TABLE OF CONTENT



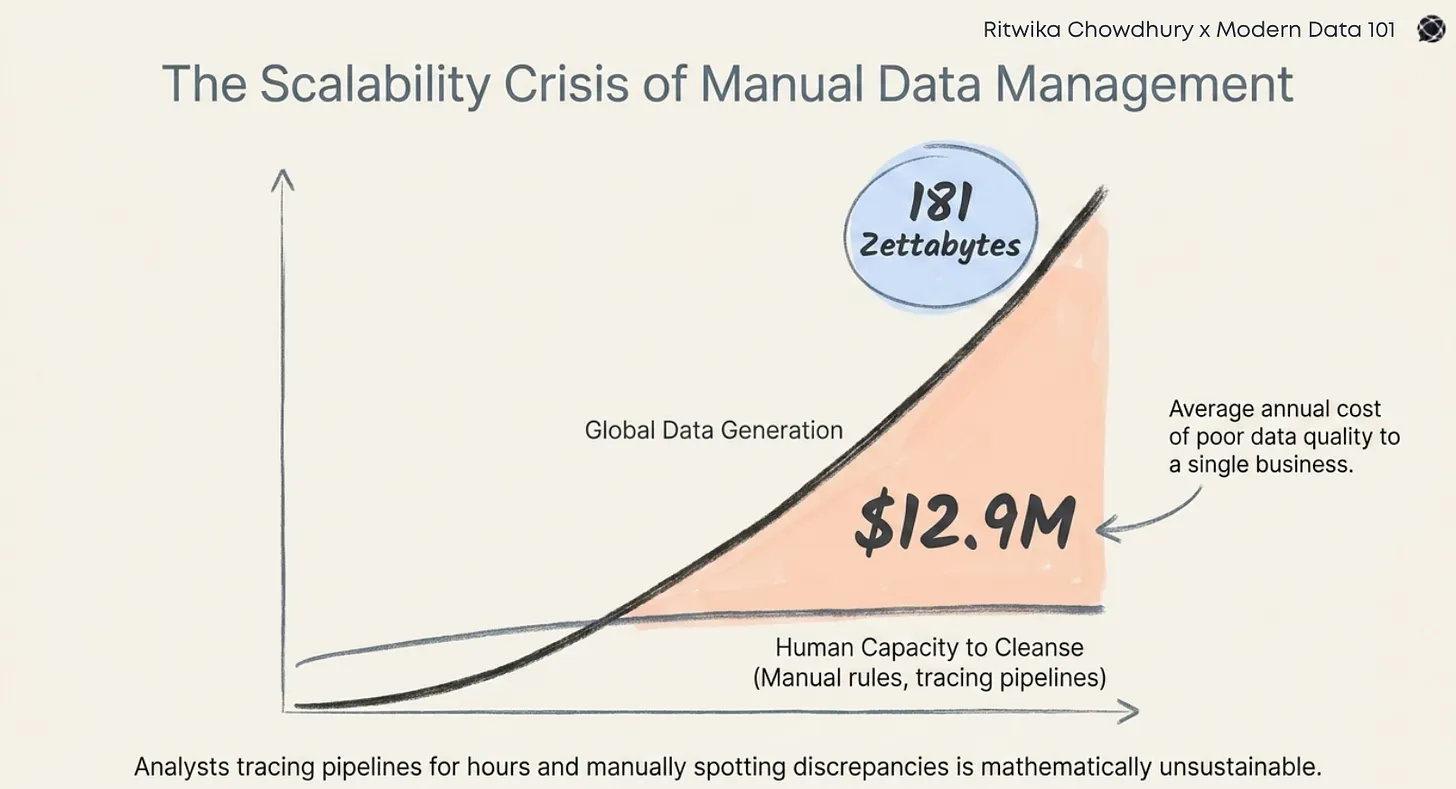
Most CDAO orgs today are playing a game they can’t win. Not because they lack the talent or tools, but because they’re trying to win with the wrong team architecture. In a global enterprise with 6 ERPs, 14 data warehouses, and a dozen SaaS platforms scattered across geographies, the traditional “central team + downstream consumers” model becomes a bottleneck factory. It’s like trying to run a Formula 1 pit crew with a medieval guild structure. Slow. Siloed. Outpaced.
This whitepaper introduces Team Topologies for CDAO Organizations, a modern operating philosophy designed for fragmented, fast-changing enterprise ecosystems.
At the heart of it: a shift from technology-centric teams (e.g., BI, ETL, cloud infra) to outcome-aligned product teams that own data products from source to signal. Think less “report factory,” more “data-as-a-service” mindset.
With this team topology framework, we don’t stop at org charts. We rewire how teams think, interact, and ship value. Powered by platforms built in the image of the data developer platform standard and ODPS (open data product specification), this framework helps leaders manage cognitive load, define clean boundaries, and create fractal structures that scale, without breaking under enterprise entropy.
If your teams still organize around tools instead of outcomes, this piece is an invitation to re-architect teams now.
Most CDAO organizations are built on a blueprint borrowed from an earlier era: one designed for stable, centralized IT delivery, not for the dynamic, decentralized, multi-system ecosystems we operate in today.
Data engineers, data scientists, BI folks, and governance each operating in their own lane, each with their own tooling, their own cadence, and their own definition of “done.” Collaboration becomes coordination theatre. Work bounces from team to team, and progress feels more like a relay race with no clear finish line. Everyone’s busy, yet nothing really moves.
Somehow we ended up organizing teams around tools instead of outcomes. SAP over here, Tableau over there, ETL somewhere in the middle. As if tools deliver value on their own. The result? Lots of activity, very little accountability. Nobody owns the business outcome, just their part of the machinery.
Everything still flows through a central data team. They’re expected to keep pace with growing demand, make sense of scattered requirements, and somehow be responsive to everyone. Instead, they become the choke point. What could’ve been a fast lane to insight turns into a never-ending ticket queue.
As more systems enter the picture, boundaries blur. Who owns the truth when five different teams touch the same dataset? It’s organizational chaos disguised as collaboration; like five people trying to parallel park the same car, each holding a different steering wheel.
Now layer on the real-world complexity, because no enterprise runs on one tidy system or one tidy process. Welcome to the jungle.
SAP for finance, BPCS for manufacturing, a hodgepodge of legacy systems, and a dozen SaaS apps duct-taped together. Each speaks a different language, follows a different rhythm, and breaks in its own spectacular way. Integration isn’t just technical, it’s political, operational, and deeply human.
Running a global operation means more than shifting standups by a few hours. You’re balancing regulatory regimes, data residency laws, and infrastructure gaps that vary by region. One country demands real-time streaming with full audit trails, another requires everything to stay inside national borders. It ends up in a fragile patchwork that looks less like a data platform and more like compliance debt.
Some teams are shipping predictive models to production. Others are still managing quarterly reports through nested Excel tabs and email chains. It’s not a skills gap, it’s a systems gap. Different levels of maturity, different tools, and different mental models all trying to collaborate under one roof. And yet, the expectation is still a single source of truth.
The biggest trap? Tool obsession. New tech enters the scene and teams reorganize around the next big platform, forgetting entirely why they’re here in the first place. The mission isn’t to win a hackathon. It’s to drive outcomes. But somewhere between buzzwords and budget cycles, that clarity gets lost.
When you combine these multipliers with legacy org design, you accumulate organizational deb: the structural misalignments and inefficiencies that make scaling data value feel like pushing a boulder uphill. This is a delivery problem, but more prominently, a design failure.
Most data orgs still operate like contractors: taking requirements, delivering something that looks like insight, and vanishing into the backlog void. The project is declared “done,” even if the value was never realized. It’s like building a house and never checking if anyone moved in.
Data product thinking flips this: it’s not about outputs, it’s about outcomes. The mindset shifts from “complete the report” to “own the signal.”
Think of data products as APIs with passports. They travel across teams, plug into decisions, and carry identity, context, and safeguards with them. Each product should be:
The DDP Standard focuses on right-to-left data engineering or reverse engineering from outcomes.
It makes product-centricity real in four strategic ways:
Each data product is a complete unit: data, metadata, logic, infra, all bundled. It’s not a table, but a capability. This enables teams to own complete business capabilities rather than just fragments of functionality.
YAML replaces yak-shaving. Teams define needs in declarative config files (”vibe coding”), not code. Consider ordering sushi instead of catching and filleting the fish.
Governance controls are built into the platform rather than applied externally, enabling teams to maintain compliance while operating autonomously. Think of it as having traffic lights built into the road system rather than requiring a traffic cop at every intersection.
Teams can build on shared components and patterns while maintaining independence for their specific business domains. It's like having a well-organized toolshed where everyone can find what they need without interfering with each other's projects.
This shift is more than growing a semantic spine, it changes the anatomy of the team itself.
Team design in data organizations isn’t about drawing org charts. It’s about enabling value delivery in a complex, fast-moving enterprise landscape. The following team structures emerge from the operating realities of modern CDAO environments where multiple systems, business domains, and compliance regimes intersect. This is a practical framework for designing for flow, scale, and autonomy.
Stream-aligned teams are the primary delivery engines. They are directly aligned to business domains and own end-to-end responsibility for the data products that serve those domains. Their accountability is clear, their scope is outcome-driven, and their interfaces with the business are direct.
They do not just move data, they manage knowledge flows that inform action across the enterprise.
Delivers cross-system customer insights by integrating Salesforce, support platforms, and custom systems. Serves marketing, sales, and customer success teams with behavioral data and customer master records.
Integrates SAP, subsidiary ERPs, and procurement systems to deliver financial and regulatory reporting. Serves finance and leadership with consistent, auditable views of organizational health.
Brings together logistics, inventory, procurement, and supplier data from systems like BPCS and partner APIs. Supports operations and procurement teams with demand planning and supplier performance metrics.
Platform teams build and maintain the foundation others build on. Their job is not to centralize delivery but to enable delivery and make it possible for stream-aligned teams to move independently without duplicating foundational effort.
They provide shared capabilities, reduce cognitive load, and abstract away infrastructure and governance complexity.
Enabling teams help others grow. Their role is temporary but essential, they exist to build capability, not dependency. They come into the picture in when there’s a gap (which is often): new system rollouts, capability gaps, or a shift in how teams are meant to work. But their real value isn’t in how long they stay. It’s in how quickly they’re no longer needed.
Data Science Enablement Team: Helps domain teams adopt advanced analytics, develop models, and build internal statistical fluency
Data Dev Platform (DDP) Adoption Team: Supports teams migrating to a product-oriented model, building platform proficiency, and adjusting operational processes
BI Enablement Team: Bridges the technical-business divide by helping teams build effective, self-service visualizations and decision support assets
Some technical domains are too specialized, volatile, or complex to be distributed. Complicated subsystem teams own these domains so that others don’t have to. They aren’t on the front lines, but in their absence, the ecosystem (data and business) stalls.
Legacy System Integration Team: Manages integrations with obsolete systems, handles non-standard protocols, and abstracts legacy complexity for modern consumers
Advanced Analytics Team: Owns model optimization, algorithm development, and infrastructure for computationally intensive workloads
Regulatory Compliance Team: Tracks evolving requirements across jurisdictions, implements monitoring/reporting, and supports data sovereignty and risk management
These four team types are not theoretical. They provide a language for structure that balances autonomy with alignment. When designed well, they allow your organization to scale delivery without scaling complexity. When ignored, they become the source of organizational debt, duplicated effort, and slowed time-to-value.
Design your team topology like your architecture: for flow, clarity, and adaptability.
Modern data organizations don't scale through rigid handoffs. They scale through structured collaboration patterns that evolve with maturity.
The better question isn’t “Who owns what?”, it’s “How do we work together, and when does that need to change?”
Team interaction isn’t fixed. It shifts as capabilities mature and context evolves.

Early on, teams need to build together: close, hands-on, iterative. But as patterns stabilize and fluency grows, that relationship should change. Collaboration gives way to clarity. What began as joint effort becomes clean service delivery.
Global enterprises don’t operate in a single regulatory regime or business context. Your team design should reflect that. Organizing for data at scale means recognizing when to centralize for consistency and when to distribute for relevance.
Whether to centralize or regionalize stream-aligned teams depends on two factors:

A single data product model does not scale across every geography. Design for divergence where necessary, but link teams through shared principles and infrastructure.
Platform teams provide critical capabilities that serve all other teams. How they’re distributed affects how quickly the rest of the org can move.

The right model depends on enterprise scale, system variation, and regional autonomy. Both can succeed when governance is clearly defined.
Distributed teams are not a blocker unless you design them that way. The following collaboration modes ensure cross-regional delivery is fluid, not fragmented.

Team structures in modern CDAO organizations are not static. As business domains expand, systems evolve, and capabilities mature, team shapes must adapt. The key is recognizing the signals early and acting deliberately before misalignment becomes inertia.
There are two primary directions of change: splitting when complexity rises, and merging when focus or volume declines.

Team types are not fixed and their states reflect the organization's maturity and needs at the time.

Scaling isn’t only about headcount, we should also consider scaling flow, capability, and clarity. There are three primary scaling motions:

No structure remains effective forever. What matters is how quickly the organization detects misalignment and responds. High-functioning data organizations build in feedback mechanisms at the system level, not just within teams.
Feedback Loops
Knowledge Management
Team Topologies provides a powerful organizational philosophy for CDAO teams operating in complex, multi-system environments. By focusing on cognitive load management, clear team purposes, and effective interaction modes, organizations can create structures that deliver data value efficiently while managing technical and organizational complexity without requiring everyone to have PhD-level expertise in everything.
The key insight is that team structure should follow data product architecture rather than technical system architecture. When enabled by platforms built in the image of the data developer platform standard and ODPS that provide data product infrastructure, teams can organize around business outcomes and customer needs rather than technical constraints.
The shift is simple but structural: teams should be organized around the value they create, not the tools they use.
What makes this model work:
How to put it into practice:
Build a platform foundation that supports team autonomy from day one. Start with domains where the value is obvious and measurable. Invest in enablement early (it compounds). Revisit team boundaries as performance and needs shift. Stay grounded in outcomes, not technical metrics!
Done right, this structure improves delivery speed, raises the quality of data products, and aligns teams more closely with business priorities. It also scales (quietly and naturally) as your organization learns and adapts.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



