



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...


%20(1).png)
.png)

TABLE OF CONTENT




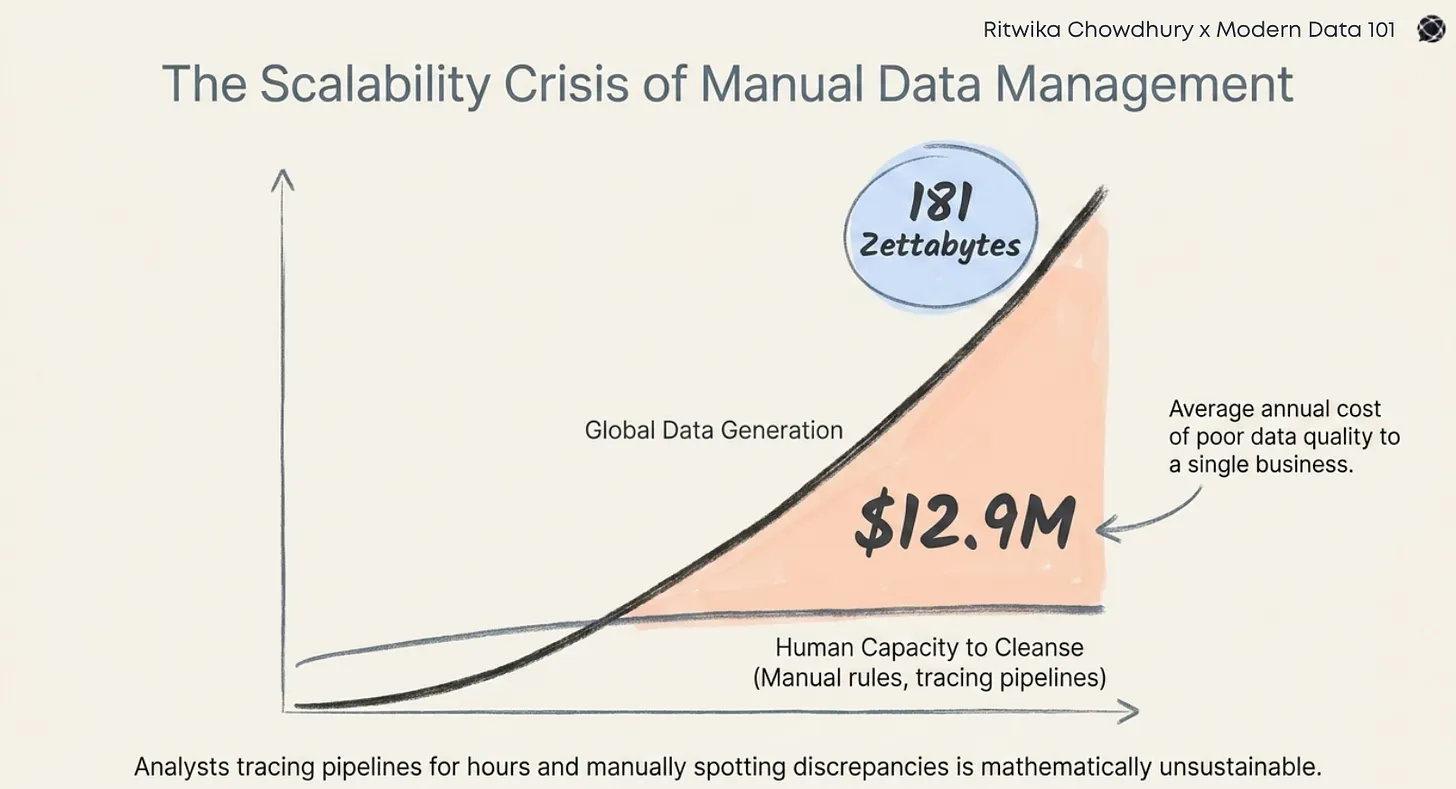
The "OG" phrase of data engineering: "it works on my machine," often signals upcoming trouble. It is that moment we're too familiar with; when juggling different software versions, library conflicts, and environmental quirks turns a simple deployment into a chaotic, frustrating puzzle. If you were seasoned before the advent of a rather heroic solution, you must have stumbled upon the question, "What if there was a simple way to package your data pipelines, ensuring they run perfectly anywhere?," must have crossed your mind.
Make way for Containerisation. It is that elegant of a solution. It brings consistency, portability, and much-needed predictability to complex data workflows. The bulging need for these environments is exactly why the modern data ecosystem is undergoing transformation.
Beyond those baffling quirks that keep data professionals up at night, a seismic shift is reshaping the data landscape. We're moving away from sprawling tools and monolithic data pipelines towards sleek, modular, composable data architectures.
Containerisation is your next superpower. It is a strategic pivot towards building data capabilities that are genuinely agile, reliable, and scalable.
In this transformative era, containerisation steps onto the stage as far more than just another infrastructure tool. It is a fundamental design philosophy, a way of thinking that aligns perfectly with how today's data products are conceived, built, deployed, and scaled. It’s about creating encapsulated, predictable environments that standardise how your data logic runs, whether you're developing locally on your laptop or deploying globally across vast cloud regions.
This massive shift pivots us to a very crucial question of the current times: What if we truly treated data infrastructure exactly like we treat robust applications: packaged, portable, and programmable?
So, what exactly is this "Containerisation" we’re all buzzing about? Imagine you are to ship a highly volatile, custom-built gadget across the country. In the days gone-by, you might carefully packed it in a unique, custom-made crate for its safe journey. This level of precise packaging might be effective for that one specific gadget, but a total no-no for the shipping company if every item needed its own customised container!
Containerisation is the software world's brilliant answer to the standardised shipping container. It is the art of bundling your application code, including an ETL script, a dbt model, or a machine learning inference service along with only the operating system libraries, dependencies, and configurations it needs to run.
All of this gets neatly packaged into a single, lightweight, and isolated executable unit: TA-DA, the Container.
This ingenious abstraction ensures that your code behaves consistently, predictably, and reliably, no matter where it is unpacked. It truly makes your code run "in any environment," from development to testing to production. No more "It works on my machine, honest!" excuses.

😉To take you a step back before jumping straight, Containerisation as a whole concept gained traction in software engineering to banish the "works on my machine" demon. 🎯
Before containers, developers often wrangled with Virtual Machines (VMs). Think of a VM as an entire house that’s complete with its own foundation, walls, and utilities but just virtually duplicated on a server. It’s powerful, yes, but also a bit hefty, slow to boot, and consumes significant resources.
Containers, on the other hand, are like fully furnished, self-contained apartment units within a larger building. It cleverly shares the core utilities (the host operating system's kernel) but maintains perfect isolation for each unit. This makes it incredibly lean, super-fast to spin up, and allows you to load far more data engineering muscle onto the same hardware.
So, how does this translate into our world of data engineering? Effortlessly. For us, containers become the ultimate Swiss Army knife:
This consistency across development, staging, and production environments is a genuine game-changer. It means your data product behaves identically from initial build to live deployment, stomping out those frustrating surprises that pop up when code migrates between servers.
To sum it up, Containerisation truly champions Modularity, leading directly to the elusive goal of Data Productisation. If a data product is a modular unit of valuable insight (say, a "Customer 360" API), then a container is its modular unit of execution. Both concepts thrive on composability, encapsulation, and discoverability. Each data product can be built, tested, and deployed independently within its own predictable box.
This also supercharges Repeatability & Reusability. Need a robust data validation module? Containerise it! Now, that perfectly tuned component can be effortlessly dropped into any new data product, behaving predictably every single time.
And for those battles with conflicting dependencies, let's hear it for Isolation. That perennial headache where different data products demand conflicting versions of Python or Spark Containerisation makes peaceful co-existence feasible. Each container is a self-contained universe, meaning your Python 2 legacy script can happily hum along next to your bleeding-edge Python 3.10 microservice on the very same machine, sans so much as a polite cough.
Finally, containers form the bedrock for modern CI/CD Pipelines for Data. They enable rigorous testing, precise versioning, and automated deployment of your data products, just like mature software products. No more crossing your fingers when pushing code to production. With containers, you know exactly what you're deploying.
At the heart, data products are purpose-built. These are designed to transform raw data into actionable insights, automated decisions, or readily consumable APIs. Think of a personalised recommendation engine fuelling an e-commerce app, a real-time fraud detection service, or a lively weekly sales forecast dashboard.
These are not just one-off scripts; they're very much living, breathing components that demand the reliability of any top-tier enterprise software. This is precisely where containerisation rolls up its sleeves and delivers some serious muscle.
Let's unpack how these versatile little boxes translate into tangible wins for your data applications:
Remember the frustrating moment when the data pipeline that performed flawlessly in development starts to throw a fit in production? This is known as a typical "environment mismatch". It is like throwing a wrench in the gears. With containerisation, those days are largely over. Each data product or application, from your meticulously crafted ETL job to a complex machine learning model, is bundled into an immutable release. This means its environment is identical across development, staging, & production. It's like a master chef giving you a pre-packaged, perfectly calibrated recipe kit. You are guaranteed the same delicious result, no matter whose kitchen you use. Your data product's behaviour stays consistent, and your sanity remains intact.
Once your data application is tucked inside a container, it becomes portable. This is not just about moving files, it is about moving a complete, self-sufficient runtime environment. Want to shift your analytics workload from an on-premises data centre to Google Cloud Platform? Or perhaps from one business unit's server to another? No problem. It's truly "written once, run anywhere." This flexibility means you're never locked into a specific infrastructure and can deploy your data products wherever they're most efficient or needed, scaling up or down with ease.
Let's understand this with a fitting example. Think your online store's recommendation engine suddenly experiences massive traffic during a flash sale. With a traditional setup, scaling up compute resources could involve provisioning new servers, installing software, and a whole lot of nail-biting. Containers, however, are built for agility. Since they are lightweight and self-contained, you can essentially hit the "clone" button, and your system can instantly spin up dozens, hundreds, or even thousands of identical instances of your data product. Need to scale down after the sale? No problem at all, just with a push of a button, you can scale flexibly. This ability to deploy containerised data products as services (like Feature Store APIs) means they dynamically adjust to demand, ensuring your data delivery is always responsive.
Knowing what your data product is doing, how it's performing, and if it's healthy is most important. Because containers provide clear, isolated boundaries around each application, they inherently make your data products easier to monitor and troubleshoot. You can easily capture richer metadata, stream comprehensive logs, and track performance metrics specific to a particular container.
Beyond just streamlining individual applications, containerisation plays a starring role in a much bigger, more strategic shift: platform thinking in data. If you’ve ever wished your data team operated with the slick efficiency of a well-oiled tech product company, containers are your secret weapon.
Think of it this way: a core tenet of data productisation is abstracting complexity. Just as a perfectly designed data product interface shields the consumer from the complex logic underneath, containers abstract the execution environment. Your data engineers no longer need to be system administrators, debugging OS-level quirks; they just need to ensure their code runs perfectly within its standardised container.
This encourages contract-based development between the platform and the domain teams. It is like an unsaid barter where the platform team provides a robust, container-orchestrated environment, guaranteeing specific resources and services, while the domain teams, in turn, deliver their data products as self-contained containers, fully aware of the environment in which it will be operating. This minimises the friction and accelerates development.
This basically becomes the runtime layer for data products platforms. These are sturdy yet universal building blocks upon which your entire data ecosystem stands tall. This foundational layer provides agile workflows, ensuring that as your data strategy evolves continuously, the infrastructure keeps up.
A little healthy dose of reality. While containerisation is incredibly powerful, it is not a magic wand that solves all problems in your data ecosystem. This strategy also comes with its share of effort and strategic approach. Like any sophisticated tool, there are quirks to consider.
No one is perfect; it is our use cases that make or break an effort. And containerisation is no different. Despite the hiccups, the strategic advantages of containerisation in data engineering are undeniable and have a profound impact on the business:
Consistently following the simple principles of standardising environments and streamlining deployments, containerisation can cut down the time to get new data products and features into the hands of users. This means faster experimentation, quicker iteration, and ultimately, a much shorter feedback loop. Believe us or not, it is almost like having a high-speed data product delivery service that ensures you never miss a beat.
No more "works on my machine" arguments across different teams! Containers create a universal language for packaging and running code. This simple hack can boost collaboration between data engineers, data scientists, analysts, and software developers. When everyone operates on the same plane, teams get time to focus on innovation rather than environmental discrepancies.
Encapsulated runtimes provide inherent boundaries that make it significantly easier to track, audit, and secure your data's journey. Containers are known to give you clearer metadata capture, robust audit trails, and the ability to enforce granular security policies at the execution unit level. This translates to stronger governance and lineage, building greater trust in your data products and simplifying compliance efforts.
To bring this all to life, let's look at some of the examples to understand how containers are actively transforming real-world data engineering scenarios into daily wins:
So, to sum it up, does a data engineer need to learn containerisation? The answer is pretty simple: while you might technically survive without it for a while, the reality is clear: Containerisation is not just a trend; it's a fundamental shift in how robust, scalable, and reliable data systems are built.
It is the ultimate answer to the OG, "works on my machine" nightmare. It delivers unparalleled consistency, portability, and isolation. What's more? It even streamlines your pipelines, empowers true data productisation, and fosters seamless collaboration across teams. We agree on the learning curve it has, and it does introduce new operational considerations without a doubt, but let's look at the strategic advantages that are simply too significant to ignore.
Connect with a global community of data experts to share and learn about data products, data platforms, and all things modern data! Subscribe to moderndata101.com for a host of other resources on Data Product management and more!
.avif)
📒 A Customisable Copy of the Data Product Playbook ↗️
🎬 Tune in to the Weekly Newsletter from Industry Experts ↗️
♼ Quarterly State of Data Products ↗️
🗞️ A Dedicated Feed for All Things Data ↗️
📖 End-to-End Modules with Actionable Insights ↗️
*Managed by the team at Modern
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.




