



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.jpg)


TABLE OF CONTENT




This piece is a community contribution from Arielle Rolland, Data & AI Strategy Manager at Accenture Nordics & Alexandre Gontcharov, Sr. Manager, Process & Product at SSENSE. Arielle is all about Data Products & Data Mesh, with a passion for tech innovation and using data to connect and empower people. Whereas Alexandre brings the industrial engineering mindset to data, making governance smoother and operations sharper. We highly appreciate their contribution and readiness to share their expertise with the Modern Data 101 community.
We actively collaborate with data experts to bring the best resources to a 10K+ strong community of data leaders and practitioners. If you have something to say on Modern Data practices & innovations, feel free to reach out!
🫴🏻 Share your ideas and work: community@moderndata101.comcommunity@moderndata101.com
*Note: Opinions expressed in contributions are not our own and are only curated by us for broader access and discussion. All submissions are vetted for quality & relevance. We keep it information-first and do not support any promotions, paid or otherwise!
Welcome to Part 2 of our series on Strategic Data Products: Building Supply Chains From Within. It’s been a while! In Part 1, we explored the shift from traditional process mining tools to the need for custom, integrated solutions powered by data products.
As supply chains become increasingly complex, relying solely on off-the-shelf tools can limit your ability to address the full spectrum of use cases. If you missed Part 1, you can find it here ⬇️
EXPERT'S DESK ⭐️
ARIELLE ROLLAND AND ALEXANDRE GONTCHAROV
27 FEB
TOC:
(a) The Evolution of the Supply Chain
(b) Why Your Supply Chain is NOT linear
(c) Building a Strong Data Foundation Means Moving Beyond Process Mining
(d) How to Embrace the Future of GenAI
..
In this second article, we will focus on a critical aspect of resilience: edge cases. By integrating data and insights from these edge cases, your supply chain becomes not just reactive but proactive, enabling it to pivot quickly and avoid disruption, additional cost, and even gain a competitive advantage.
As discussed in Part 1, supply chain networks are inherently complex, shaped by a mix of processes, product types, customer expectations, and supplier behaviors. This combination inevitably introduces variability and nuance. While some of these variations are intentionally designed by the organization to meet local or product-specific needs, others emerge unexpectedly and fall outside the scope of standard controls.
These unexpected scenarios are what we call edge cases: rare, irregular, or complex events that sit outside normal operational parameters but can have a significant impact.
They often emerge at the intersection of multiple departments, systems, or processes where ownership is unclear, response mechanisms are weak or special handling is required. While edge cases may seem exceptional, shifts in market behavior or network dynamics can quickly become common patterns, the new normal, turning yesterday’s outlier into today’s operational risk.
Offices went dark. Homes lit up. Everyone rushed to set up work-from-home stations. iPads, gaming consoles, webcams, laptops: sold out. The chip factories couldn’t keep pace. But this wasn’t just about tech.
Because chips power more than laptops, like the brake sensors, navigation, and control systems in cars, the automotive industry came to a crawl. Cars were built and ready, but couldn’t be delivered. One missing chip and the whole value chain pauses. That’s the bullwhip effect in motion: small demand spikes at the edge becoming violent cracks at the centre. ~ Sagar Paul, SVP Global Growth and Solutions (Source)
Edge cases don’t need to be caused by major disruptions; they often stem from the design of the supply chain itself. However, organizations frequently operate without realizing these edge cases exist, or they’re aware of them but underestimate their true impact. Edge cases are easy to overlook in aggregate reporting, yet they often drive hidden costs, delays, and compliance risks.
Consider a company sourcing products under DDP (Delivered Duty Paid) terms. Most shipments clear customs in 3-5 days. But 5% of shipments, flagged for detailed inspection due to specific product attributes, take 15-30 days. This causes:
Because only 5% of shipments are affected, average clearance times look fine in KPIs. But that small subset can silently cost the company millions each year in inefficiencies and missed opportunities.
By identifying and managing edge cases systematically, companies can uncover hidden value, reduce operational risk, and design a supply chain that is not just efficient.
And surprise: without proper data structures and analytical capabilities to identify and monitor such edge cases, this "5% problem" continues indefinitely, accepted as an occasional annoyance rather than a systemic issue worthy of strategic intervention.
However, the next question you may ask is how many edge cases do you think an organisation has on average? 10s, 100s, 1000s? And the answer is always more than you think.
The short answer: environmental inertia.
Edge cases are often perceived as rare, but in today’s operational landscape, they are far more common and more costly than most organizations realize. In fact, they are no longer exceptions, but symptoms of complexity that’s been allowed to grow unchecked.
Over the past decade, digitalization has accelerated across all functions. HR, sales, customer service, operations. With companies adopting an average of 120 to 300 SaaS tools. Each one generates and consumes data in its own way, leading to:
This fragmented digital landscape makes edge cases inevitable and hard to spot. What one system tracks might be invisible to another. Teams end up managing exceptions manually, outside of governed workflows.
Edge cases are amplified when market conditions shift, be it geopolitical events, regulatory changes, or supplier disruptions. Systems and teams, optimized for "normal" operations, struggle to respond when those norms break. That’s when, say, forecasting becomes unreliable or capacity planning falls short, workarounds create hidden cost and risk.
You can’t eliminate every edge case, but you can manage them proactively. Here’s how:
The goal is not perfection, but resilience: to identify and address edge cases beforethey escalate into systemic failures.

When we speak of hundreds of data producers across an organisation, integrating these systems is rarely straightforward. The same task may be performed in multiple tools, leading to duplication, conflicting data, and critical integration gaps. In many cases, employees are forced to bridge these gaps manually, copying data between systems using Excel or Google Sheets.
This kind of fragmentation leads to inefficient workflows, broken processes, and limited visibility across the business.
No wonder 50% of companies using multiple SaaS applications plan to centralize them within the next five years (source: Gartner). Gartner Research also shows that organizations without centrally managed SaaS lifecycles are 5x more vulnerable to data loss or cyber incidents caused by misconfiguration.
And it’s exactly where data platforms can make a difference, helping teams cut through the noise and bring clarity to complex, fragmented environments.
📝 Editor’s Note
Refer to the Data Developer Platform Standard, a community-advocated platform standard to build and support a range of centralised, hybrid, or decentralised data design paradigms on top of it.
What the community advocates on DDPs ↗️
The challenge is even greater when 30% of employees use SaaS tools not approved by IT (source: IBM), or when local offices customize fields and parameters independently. This results in inconsistent data, non-standard workflows, and unpredictable system behavior.
And when disruption hits, whether due to geopolitical events, supply chain shocks, or regulatory changes, these inconsistencies become magnified. Forecasting, planning, and capacity allocation quickly deteriorate. Teams, optimized for stability, struggle to adapt when parameters shift rapidly, leading to cascading impacts on speed, quality, and cost.
The core issue? People build habits around the tools they use and the KPIs they’re measured on, not around the end-to-end value stream of the business.
That’s why data products are essential. They surface hidden scenarios, connect the dots across functions, and enable product and process teams to see the full picture, not just during normal operations, but under stress and disruption as well. This visibility is the foundation for resilience and better decision-making.
Data products help uncover, quantify, and contextualize edge cases by providing a cross-functional view of operations. They answer:
This enables teams to align on what truly matters, not just within their own function, but for the business as a whole.
📝 Related Reads
A. Vertical slicing embodied by data products: Directly coupled with Data/AI use cases | Impact on Lineage
B. Vertical Infrastructure Slices of Data for Specific Use Cases | How Data Becomes Product

So when you’re collecting data from hundreds of producers across 120 to 300 systems, integration becomes a challenge. That’s why having well-designed data products is essential: they unify fragmented data, standardize definitions, and provide a consistent, trusted layer for analysis and decision-making across the organization.
Leaders and functional managers often operate based on their own perspectives and priorities, each shaped by the metrics they track and the parts of the system they see. As a result, what one leader views as a critical issue may be seen as less important by another.

Without a shared view of the full value stream, decisions are optimized locally but often create unintended consequences elsewhere. Actions that may appear beneficial in one department can, in reality, create downstream discrepancies, rework, or inefficiencies for others.
That’s where a clear, shared data model of the supply chain through interoperable Data Products anchored in end-to-end business objectives becomes essential. It removes bias from vertical thinking and aligns leadership around the broader picture, ensuring that everyone is operating from the same source of truth and making more effective cross-functional decision-making.

Let’s revisit the customs clearance edge case. We all agree that in a typical organization running hundreds of disconnected systems, this type of issue often stays hidden and unresolved. Why?
Data silos prevent teams from seeing the full end-to-end picture or understanding the downstream impact of delays.
The supply chain team builds complex Excel trackers to monitor recurring shipment issues. Over time, this workaround becomes "business as usual."
The issue isn’t logged, flagged, or escalated in the IT system.
So leadership remains unaware of the hidden costs and inefficiencies downstream.
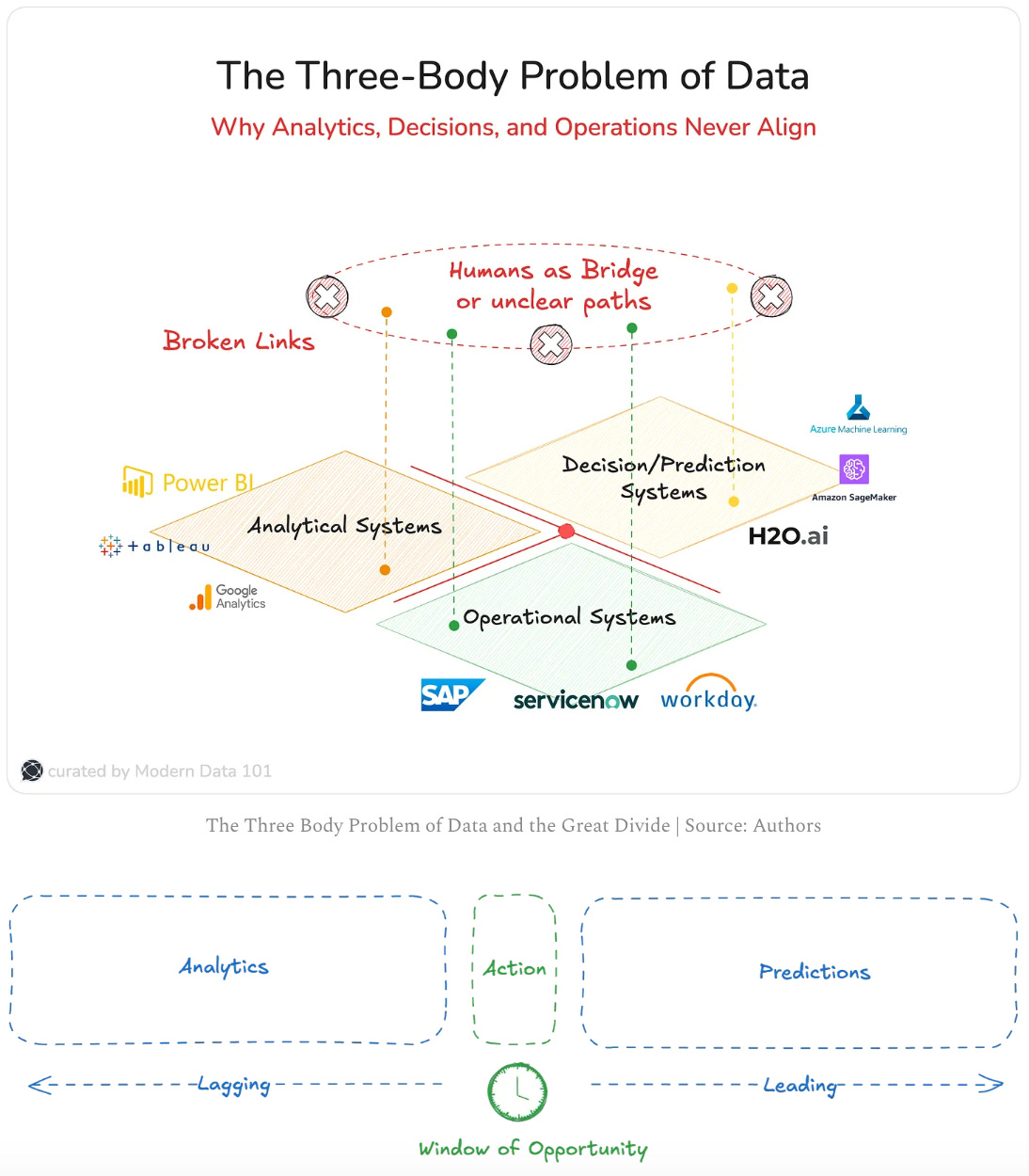
Most enterprises have three disconnected engines running: analytics that tell you what happened, ML that tries to predict what might happen, and operations where reality unfolds every minute. But the moment you ask, “Who actually did something based on this insight?”, there’s usually no answer or a vague one with non-existent transparency…But there’s a moment these systems converge on a unified execution surface, built to act, not just report. It’s what emerges when your data platform stops being a silent archive and starts running the business.
~ Excerpt from Sachin Dharmapurikar’s The Three-Body Problem of Data
This is where data products make a real difference. By integrating fragmented data sources and surfacing cross-functional patterns, data products:
They don’t just show what’s happening, they reveal why it’s happening and who it affects, making it possible to prioritize systemic fixes over isolated optimizations.
📝 Related Read
Building "Thousand Brains" Data Systems: Designing Reflex with Edge Intelligence
SAGAR PAUL
31 JULRead full story
If there are any takeaways, they are that Data Products unify fragmented systems↗️, align metrics to end-to-end business outcomes↗️, and create a shared understanding across functions↗️. They help organizations see beyond isolated KPIs, surfacing the cumulative cost of inefficiencies and making the invisible visible.
More importantly, they shift the mindset from firefighting to foresight.
By operationalizing data at the edges of your business where complexity is highest and clarity is lowest, Data Products enable supply chain teams to not only manage exceptions but also shape better systems, faster decisions, and more resilient operations.
Because in today’s world, resilience isn’t built from the outside-in, it's built from within. And data products are the foundation.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
📝 More food for thought
The Reflexive Supply Chain Stack: Sensing, Thinking, Acting
SAGAR PAUL
12 JUN
Read full story
If you have any queries about the piece, feel free to connect with the author(s). Or connect with the MD101 team directly at community@moderndata101.com 🧡

Find me on LinkedIn 🙌🏻

Find me on LinkedIn 😀
From The MD101 Team 🧡
230+ Industry voices with 15+ years of experience on average and from across 48 Countries came together to participate in the first edition of the Modern Data Survey

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


