



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.png)

TABLE OF CONTENT




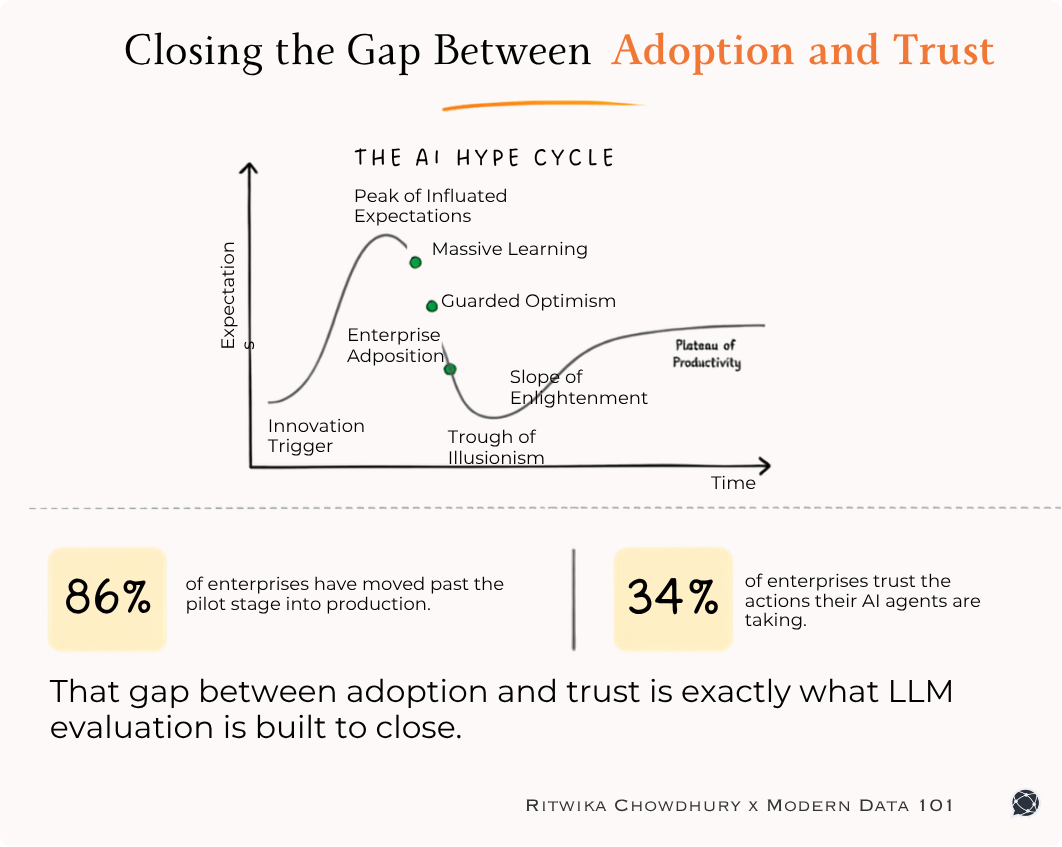
Last week, we published a piece on the Evolution of the Data Stack, and the community resonated well with the story of how the data industry has been interpreting data and the potential way it could effectively manage ever-growing data. Not surprisingly, the Data-First way turned out to be the unmistakable showstopper.
🔶 The Data-First Stack or DFS resonated for one key reason: It is an enabler for Data Products, which the community is increasingly aware of and is progressively creating an industrial demand for.
But to understand how exactly the DFS enables the Data Product construct, we need a couple of brief refreshers.
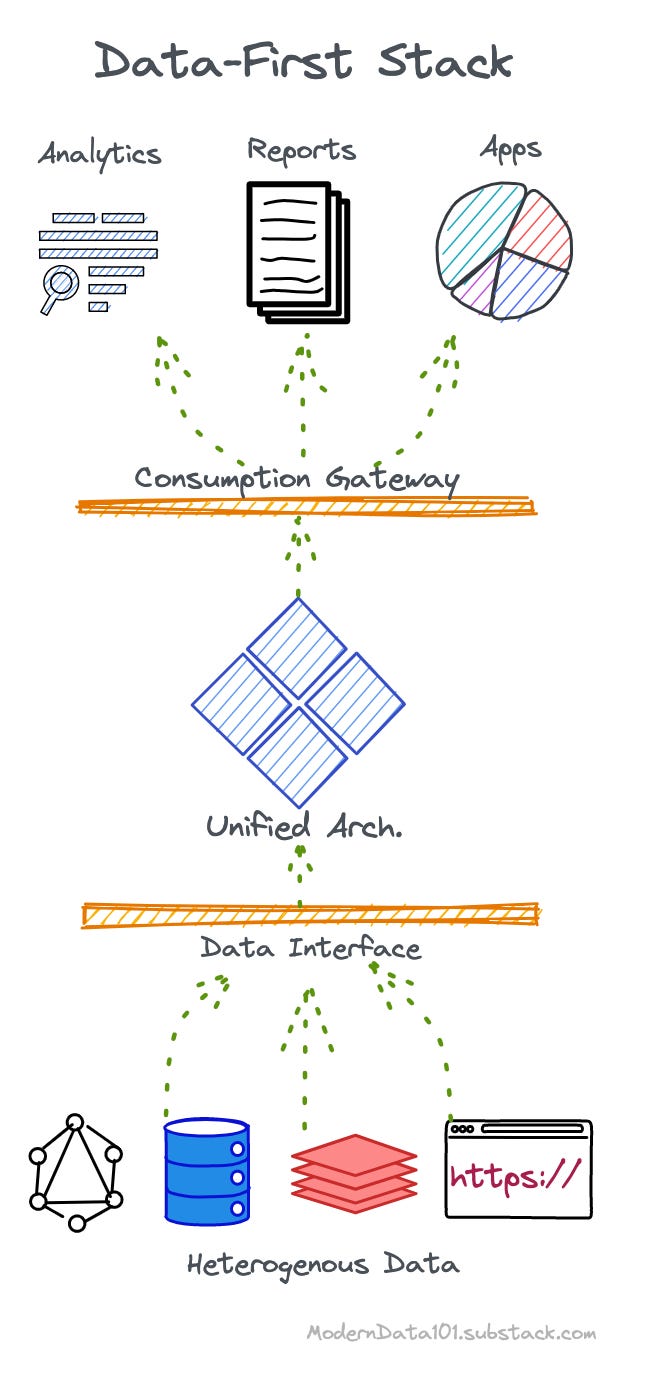
Data-first, as the name suggests, is putting data and data-powered decisions first while de-prioritising everything else either through abstractions or intelligent design architectures.
Current practices, such as the Modern Data Stack, goes by ‘data-last” and focus too much on managing and maintaining data infrastructures. Data and data applications literally become the last priority, creating challenges for data-centric teams, producers, and consumers.
A data-first stack abstracts low-level resource management tasks while not compromising their flexibility to allow data developers the complete freedom to declaratively manage less strategic operations.
A DFS has the following key attributes:
For a more low-level understanding of each of the above features, refer to the “Defining factors of the Data-First Stack.”
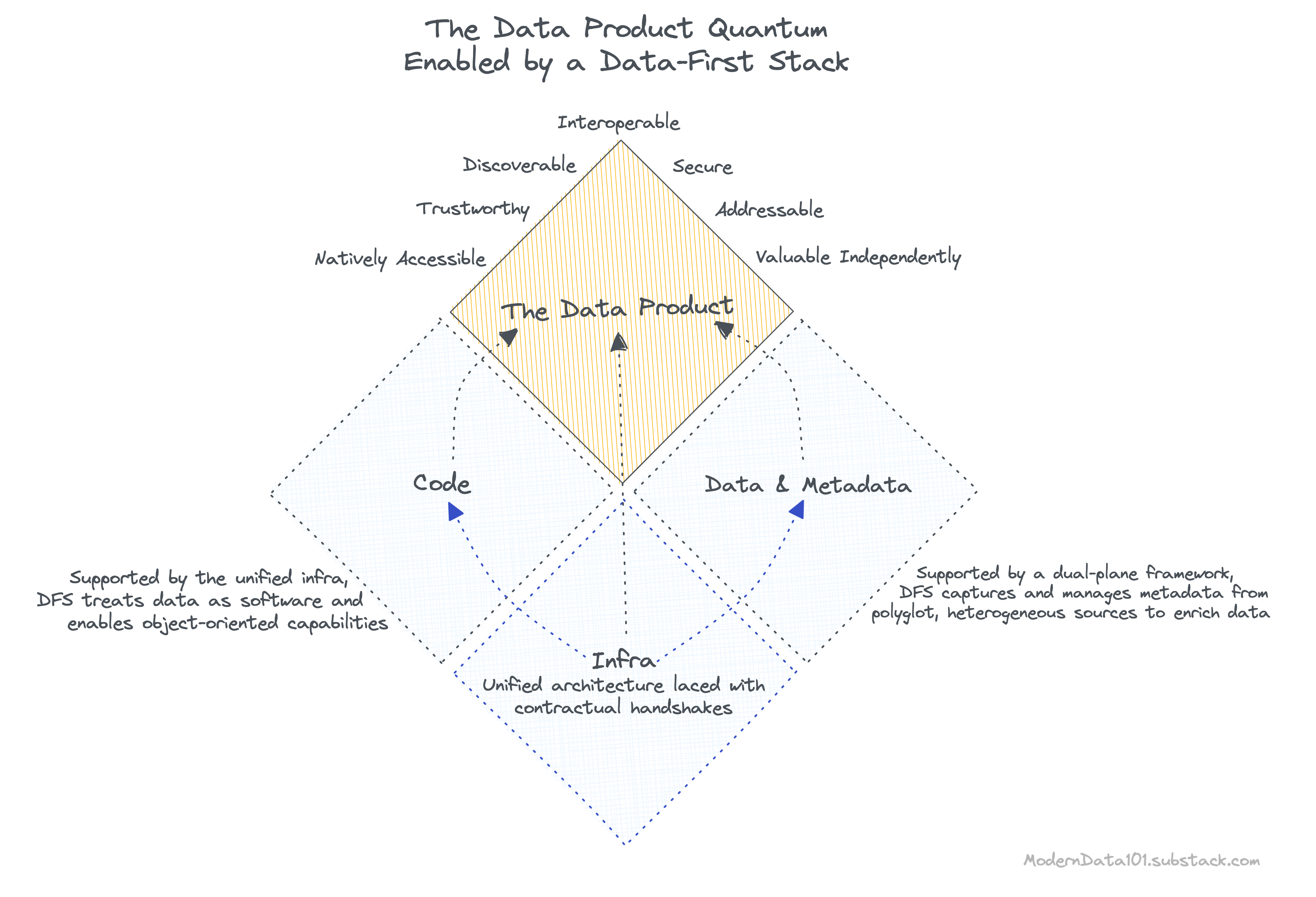
In Data Mesh speak, a Data Product is an architectural quantum, which is the “smallest unit of architecture that can be independently deployed with high functional cohesion and includes all the structural elements required for its function.”
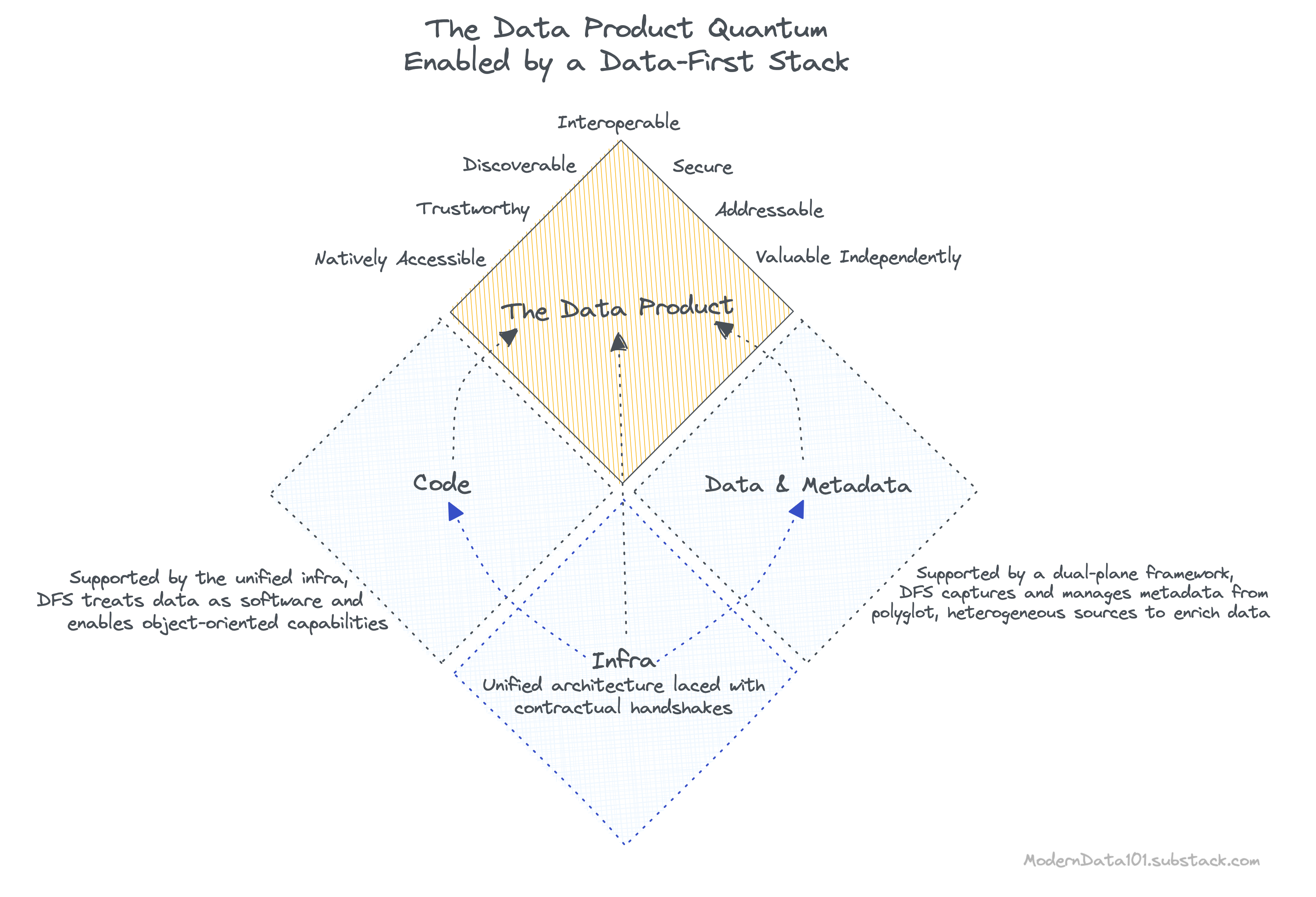
To become the independent architectural quantum, a Data Product needs to wrap three structural components:
The code required for data management (including complex data transformation) is far from simple or straightforward. It encompasses data pipelines (ingestion, transformation, and serving), APIs (access, metadata, and metrics), and enforcement (policies, compliances, lineage & provenance).
The reason why the data ecosystem is not as robust as the software ecosystem is that code for data management was never approached from a software development angle. In prevalent data stacks, all these code components are isolated and are unable to talk to each other.
🔑 We do not just suffer from data silos, but there’s a much deeper problem. We also suffer tremendously from data code silos.
A Data First Stack approaches data as software and wraps code to enable object-oriented capabilities such as abstraction, encapsulation, modularity, inheritance, and polymorphism across all the components of the data stack. As an architectural quantum, the code becomes a part of the independent unit that is served as a Data Product.
Becoming data-first within weeks becomes possible through the high internal architectural quality of a DFS that constitutes composable primitive components talking to each other to build finer and more complex data solutions: Unification through Modularisation.
The spiel on code composability is, in fact, endless. More so if we start talking about how data contracts fit into the enforcement narrative, or how federated governance plays out, or how metadata is centrally managed and utilised. Perhaps, I’ll reserve it all for a dedicated piece on the code aspect of data products.
Data is undeniably powerless without metadata. The Data Product construct understands this and augments heterogeneous sources to tap into rich metadata. While data can be served in multiple formats, as is usually the need, metadata allows the data product to maintain universal semantics.
🔑 Universal semantics allows the data product to become addressable, discoverable, interoperable, and natively accessible.
Having access to universal metadata, it is possible to identify associations between data assets, surface lineage, provenance, observability metrics, and key relations. It also enables the discovery of latent information, and with open APIs, users can augment and leverage this data programmatically.
With such rich information, data users can throw more light on the data and resurrect it from the limitations of ‘dark data’, which is rich, yet dormant information limited by subpar semantics.
The Data-First Stack enables high-definition metadata through the dual-plane principle. The central control plane has complete visibility across the data ecosystem and is able to oversee metadata flow from heterogenous polyglot sources. The data planes, on the other hand, are isolated instances that are deployed for niche domains, specific data product initiatives, or even for individual use cases.
Having contracts as a key resource of DFS adds more colour. If you think about it fundamentally, a data contract is nothing but metadata + enforcement. Establishing a contract inherently means establishing declarative enforcement. Contracts can either pull metadata from the central plane or be explicitly defined, and once established, they act as a guarantee on the metadata specifications and make change management (one of the biggest challenges) practically seamless.
The infra is the supporting foundation to enable the code for data products and to ensure that all the nine yards of governance, metadata, and orchestration are declaratively taken care of.
The Data-First Stack is a construct made feasible through a unified architecture ideology laced with contractual handshakes. This unique combination allows the reversal of data accountability to shift it closer to the data source, as is the requirement for a true data product. You’ll soon see how a few scrolls away.
While typically, having dedicated data product owners becomes essential to produce and maintain data products, the infrastructure powering the DFS frees the organisation or data teams from the additional friction of onboarding, training, and maintaining data product developers or data product developer teams.
🔑 Any data developer is a data product developer when armed with a Data-First Stack.
The declarative ability of DFS is feasible due to flexible abstraction that allows data developers to delegate the process-intensive work and focus on data and data applications.
Interestingly, this declarative ability also allows businesses and domain users to gain control over the data and define it as per the business requirements instead of having to depend on the sub-par domain knowledge of poor centralised data engineering teams who have to crunch information from across multiple domains.
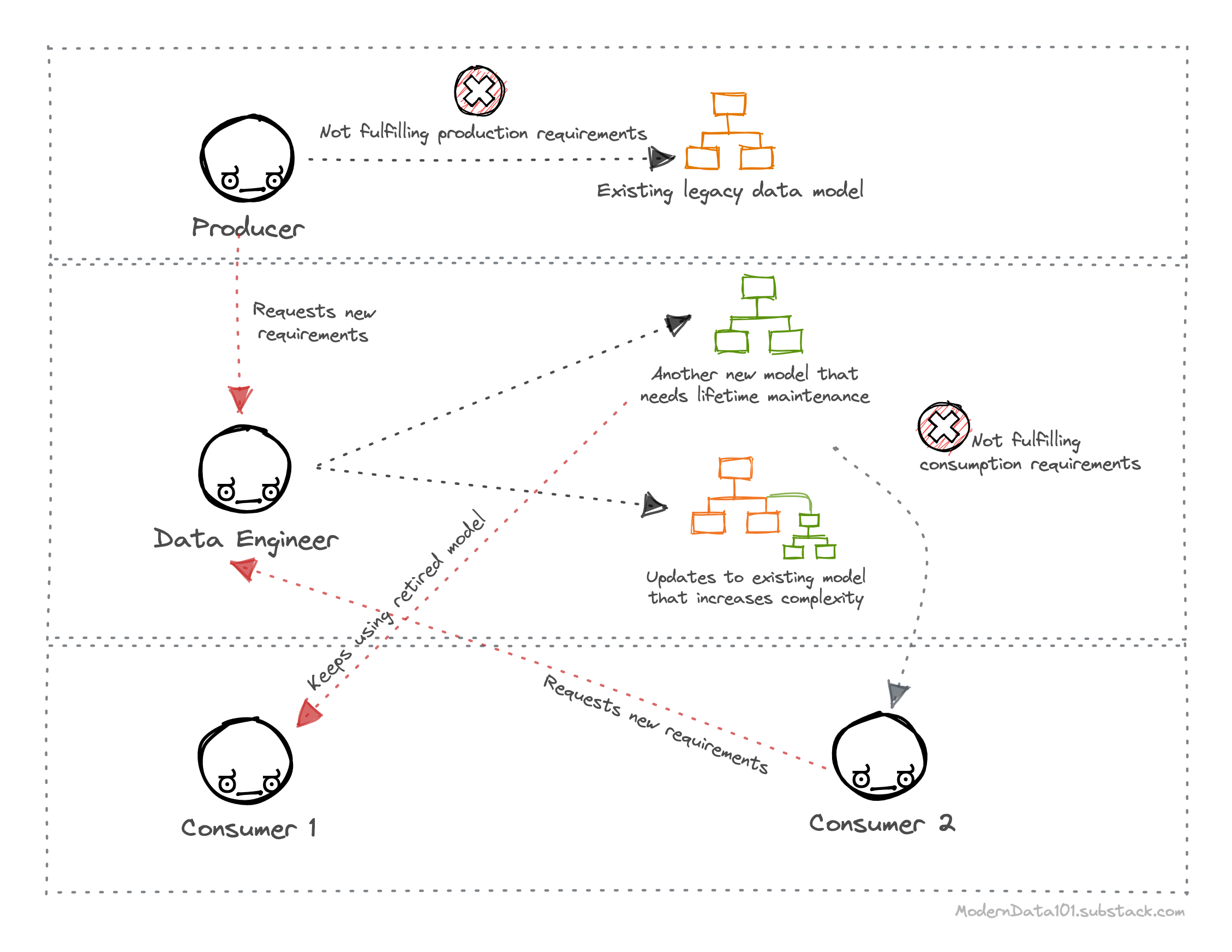
The control goes back through the right-to-left data modeling approach, which is succinctly enabled through DFS. As per the Data Product ideology, accountability for data quality shifts closer to the source of data.
Right-to-left data modeling is the reversal of prevalent paradigms of data modeling, which has been to have central data engineering teams model data based on their partial view of the business landscape, consequently leading to countless iterations and subpar business results.
Thus, the data models produced lack in business context leading to:
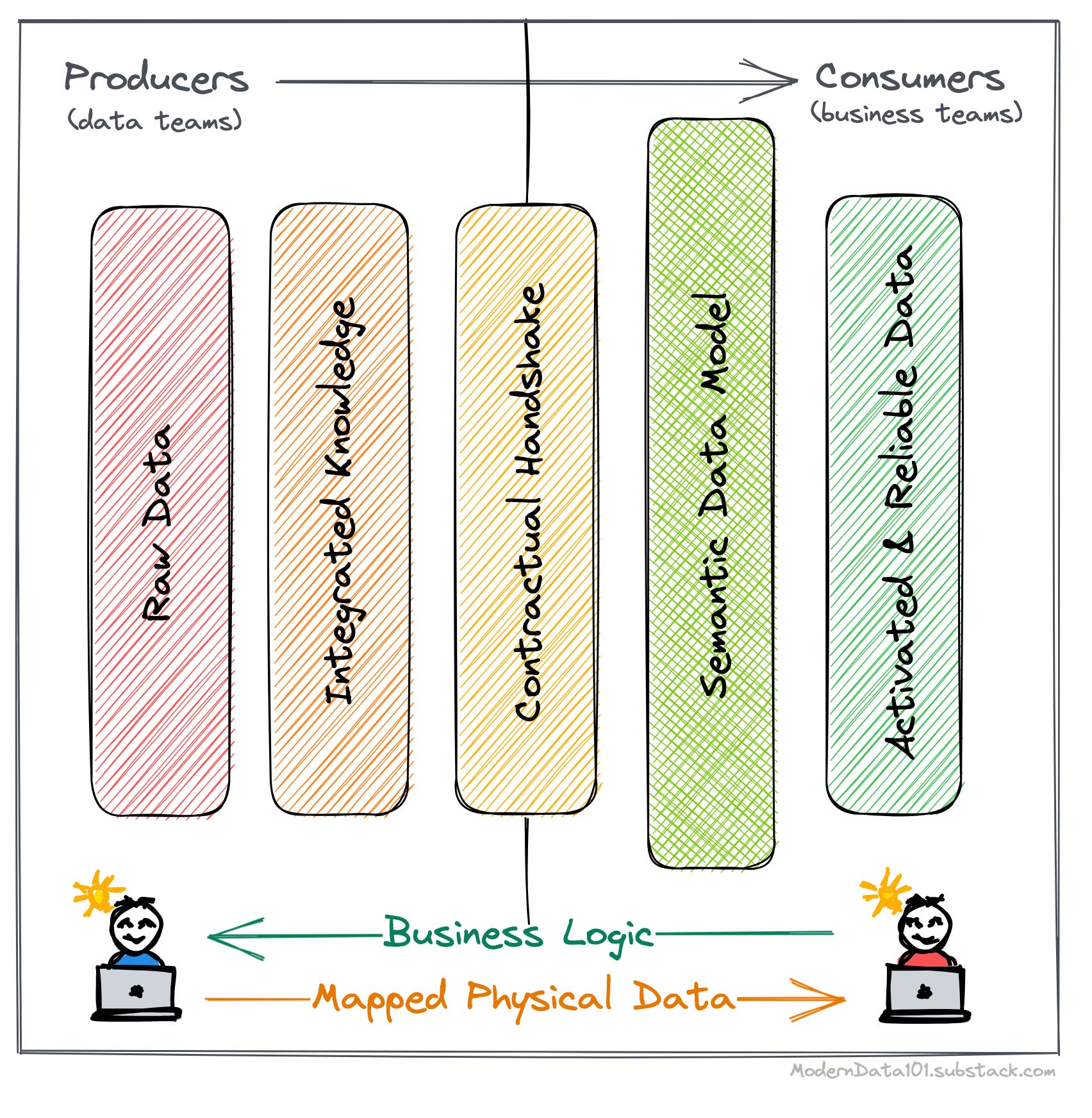
Right-to-left data modeling is where the business user defines the data models based on use case requirements. This holds even when the data demanded by the model does not exist or has not yet arrived in the org’s data store.
In this reverse approach, business users can further ensure that the data channeled through the data model is of high quality and well-governed through contractual handshakes.
Now, the sole task of the data engineer is to map the available data to the contextually rich data model. This does not require them to struggle with or scrape domain knowledge from vague sources. Imagine a team of less frustrated DEs and nearly happy faces 🌞
This also implies that the use cases on top of the data models are powered by the right data that specifically aligns with the high-value requirements.
What does the outcome look like?
To get a more detailed understanding of the reversed data management paradigm, refer to the “proposed right-to-left dataflow.”
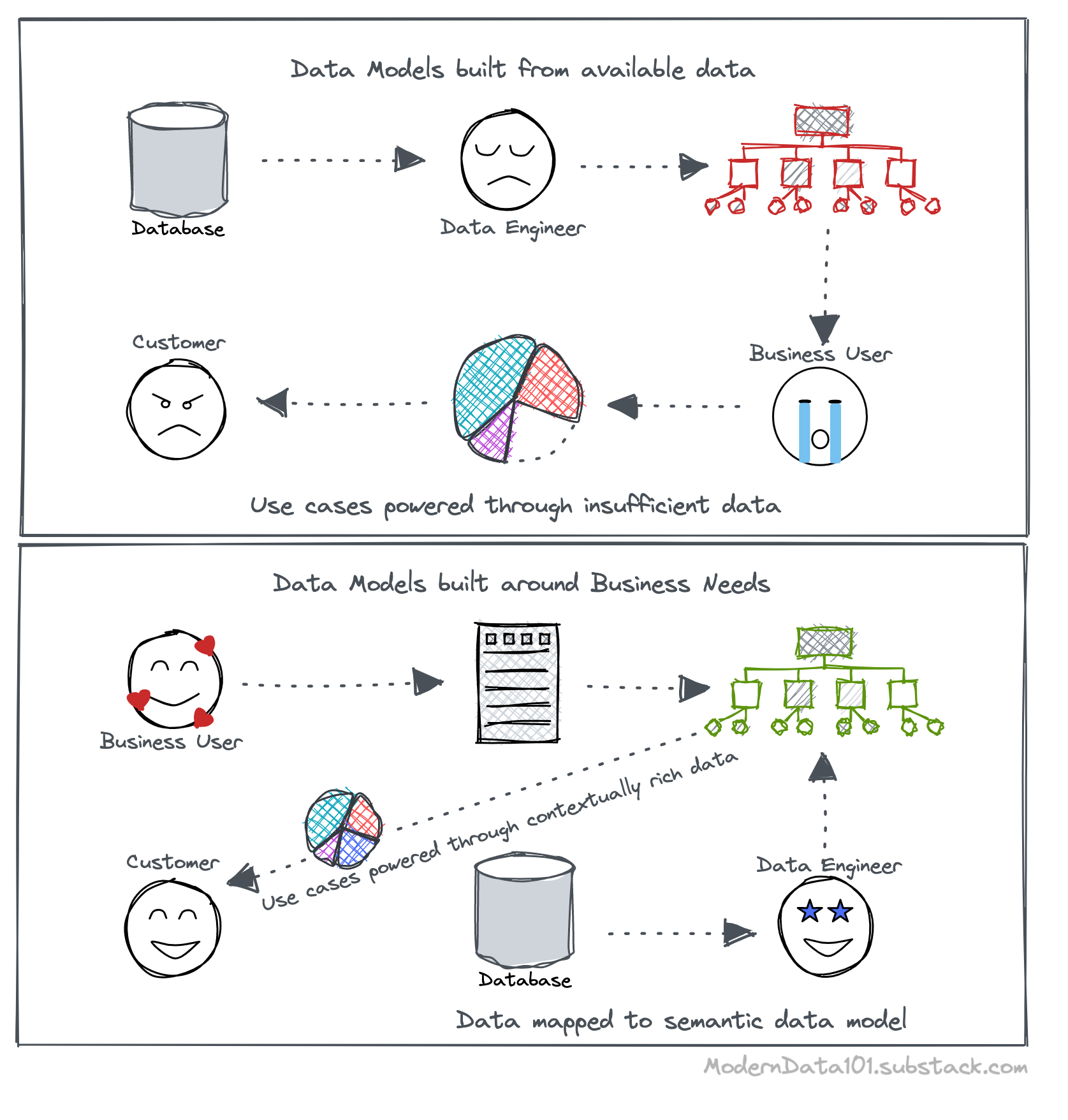
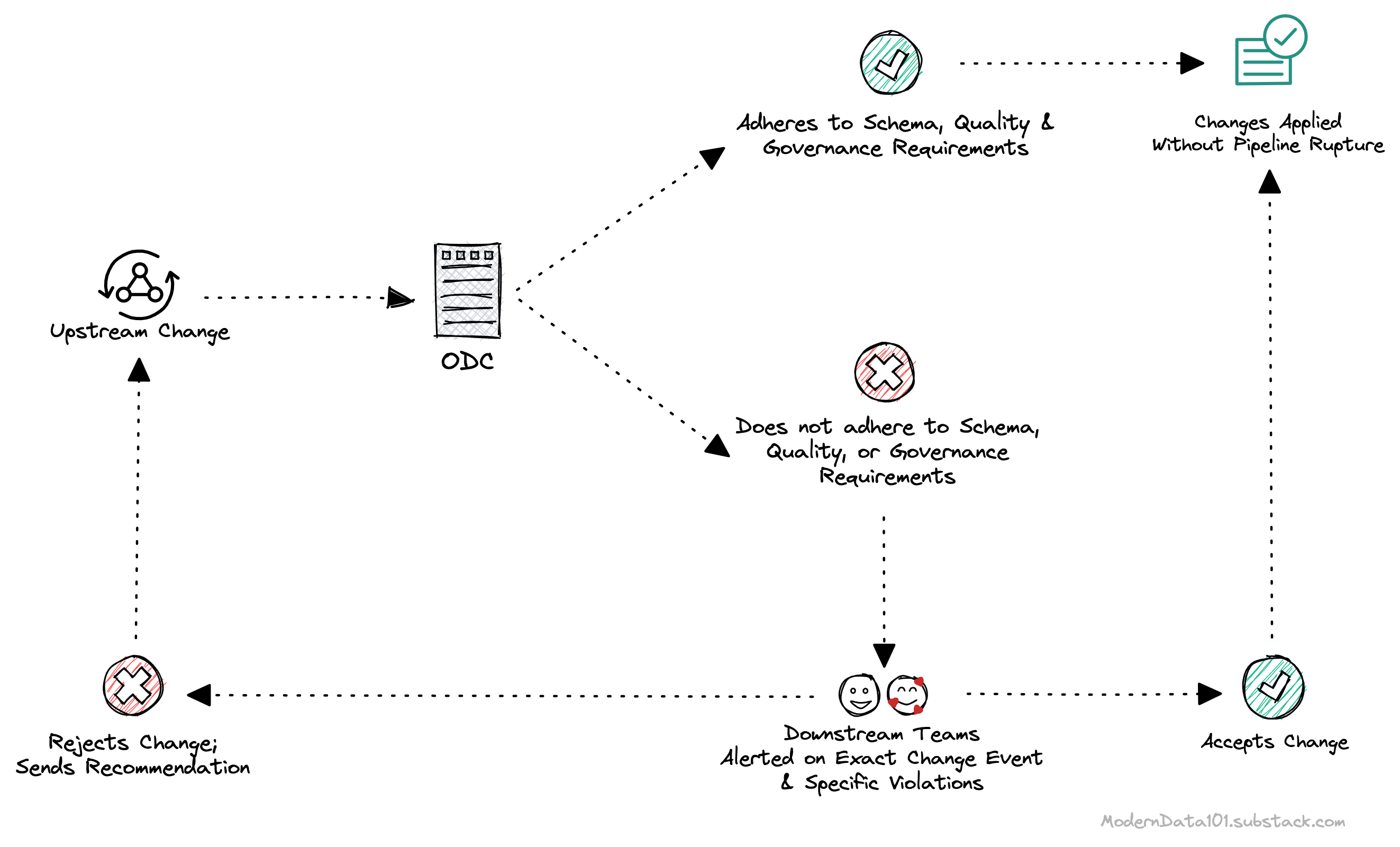
Data contracts are the enablers of right-to-left data control, moving data accountability closer to the source and materialising true data products in the process. Without the implementation of Data Contracts in data-first stacks, models and the apps in the activation layer cannot channel data that has quality, semantics, and governance guarantees.
Through data contracts, business users define their data expectations based on the use case instead of consuming whatever IT feeds them. This holds even when the data demanded by the data model and the contract do not exist or have not yet arrived in the org’s data storage.
Business users can ensure that the data channelled through the data model is of high quality and well-governed through contractual handshakes. The sole task of the data engineer is to map the available data to the contextually rich data model. This does not require them to struggle with or scrape domain knowledge from vague sources. This also implies that the use cases on top of the data models are powered by the right data that specifically aligns with the high-value requirements.
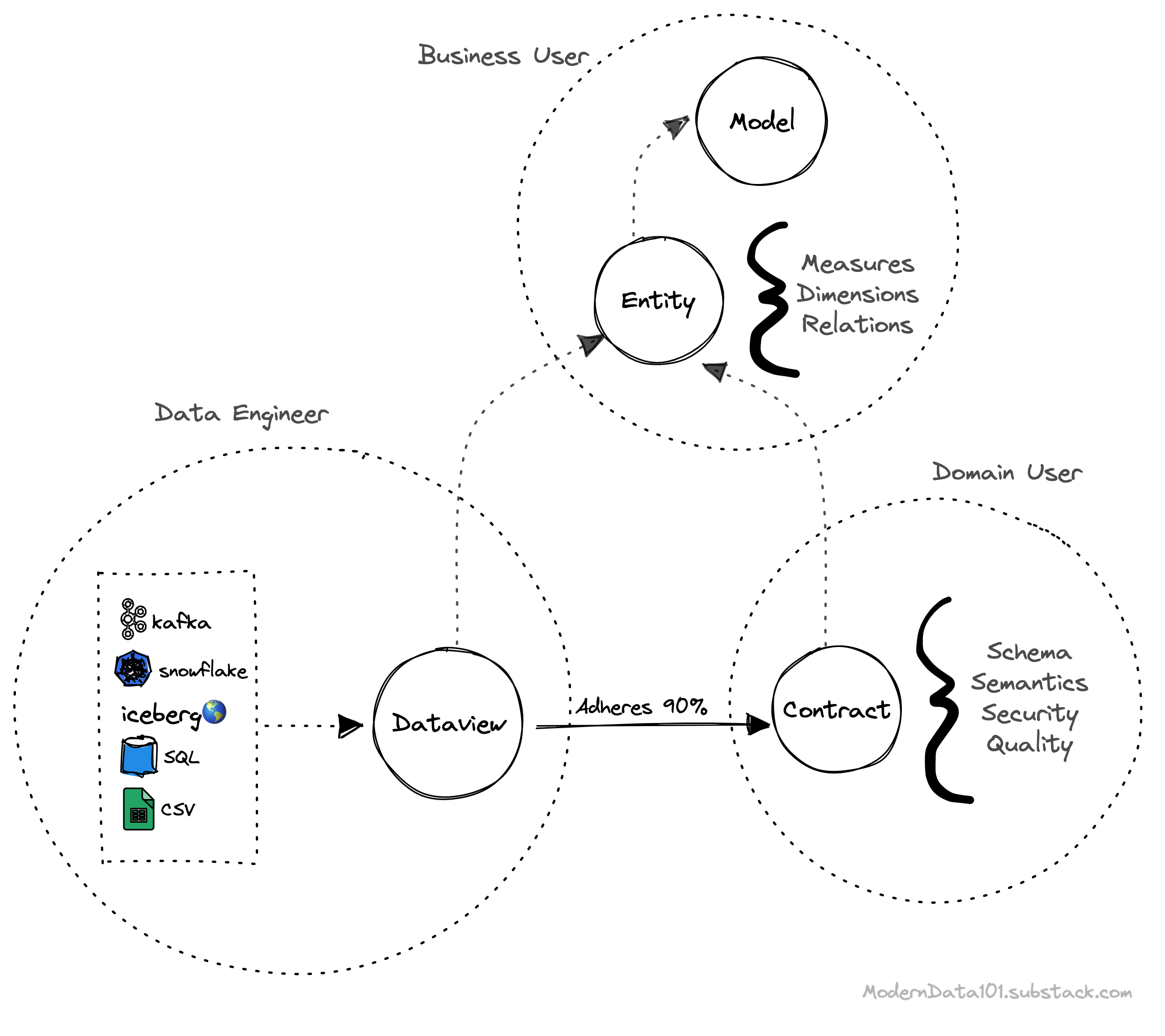
To not become another point of resistance when you build a data-first stack, this landscape allows Data Engineers to independently create dataviews without any dependency on Contracts. Contracts need not be enforced on dataviews. Instead, they may act as guidelines that Data Engineers could choose to adhere to stick to business expectations.
This landscape enables data engineers to start seeing the data contract as an ally and resourceful assistant instead of as an imposing boss. Over time, the value that contracts deliver by reducing the number of requests on the data engineer’s plate leads DE teams to demand contracts and incline towards higher adherence percentages.
🔑 Anytime a data product has to be materialised, a dataview-contract pair needs to be pulled up, where the dataview (not the physical data) adheres to the contract over the required adherence percentage.
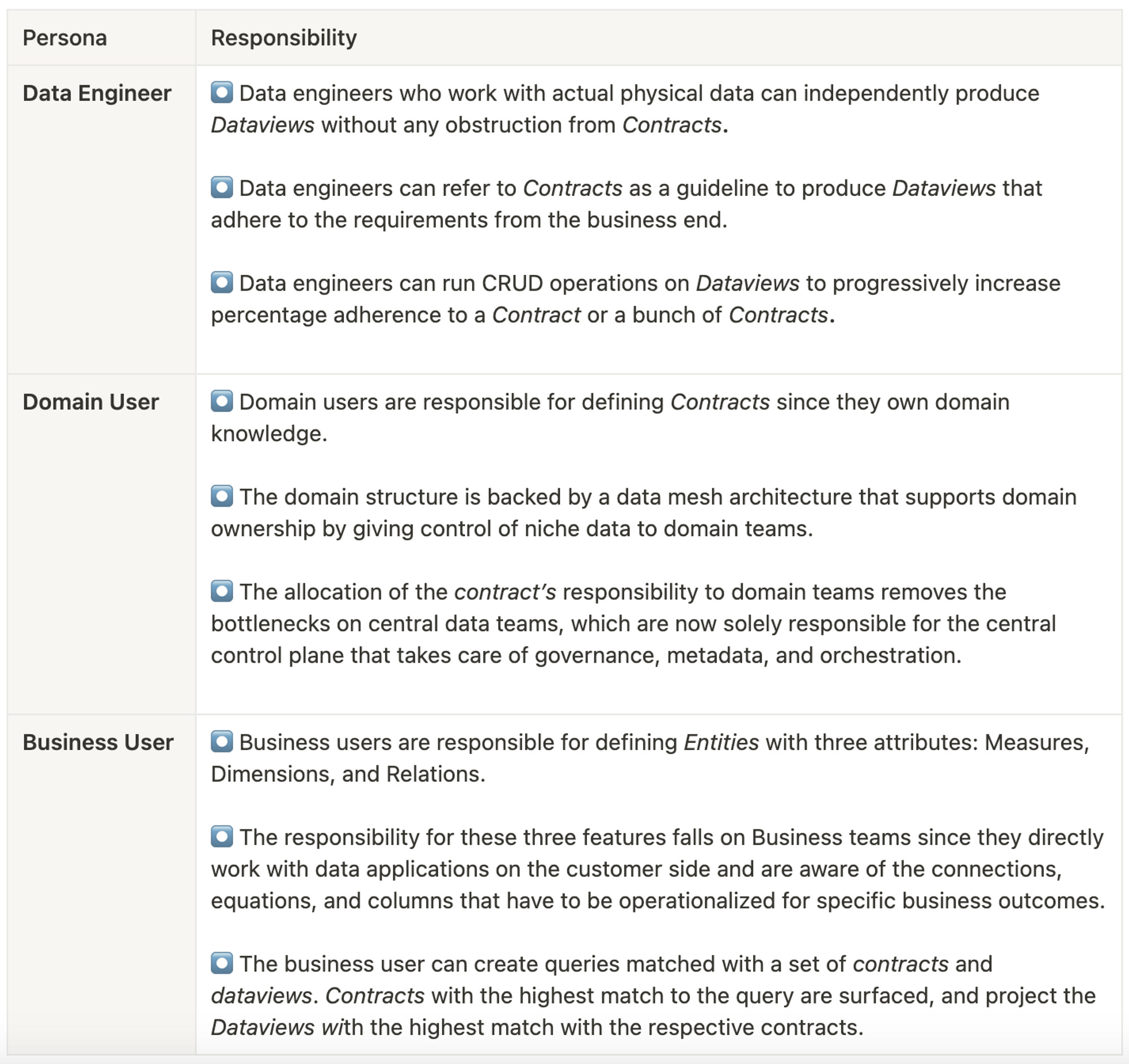
Dataview, Contract, and Entity, each fall under the ownership of different personas. However, no persona is restricted from setting up either of the components. The boundary is loosely defined based on the typical role of three different personas. Here’s what the division of responsibility looks like:
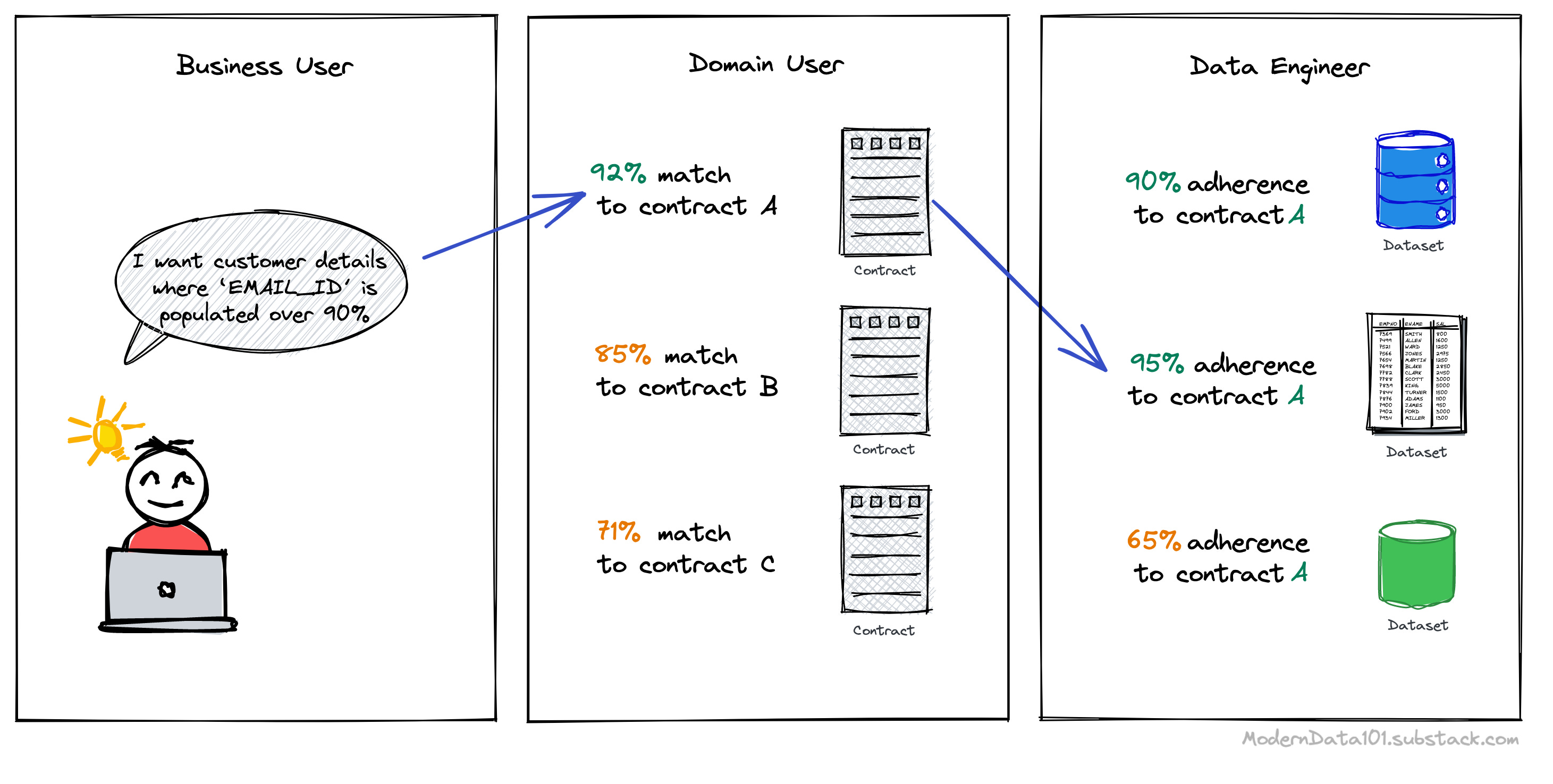
In a DFS that is supported by a unified architecture and dotted with contracts on both production and consumption ends, the Data Developer is intrinsically the Data Product Developer. The need to provision new resources and teams specifically to build and curate data products is dissolved.
Here’s how three data personas interact in the contractual landscape:
The unified foundation of the DFS allows users to catalogue contracts and dataviews intelligently and in a highly discoverable way to ensure that they do not become another unmanageable data asset.
To summarise, it’ll be best to bring back the data product quantum illustration. Now that we have more context around the details, it will help to connect the dots between the concepts we discussed in this article:
Knowing what is a data stack might have been the omnipotent aspect decades back. But, today, we see a clear transition from legacy data stacks to modern data stacks, and we are now moving beyond to the data-first approach.
Though the modern data stack architecture proved to be like the big wheel for organizations aiming to be data-driven and nailing their data maturity journey, it required a revolutionary shift. This is where we will see the data-first stack coming to the forefront with the evolving data business user needs, making data analysis and overall usage more efficient and impactful.
Since its inception, ModernData101 has garnered a select group of Data Leaders and Practitioners among its readership. We’d love to welcome more experts in the field to share their story here and connect with more folks building for better. If you have a story to tell, feel free to email your title and a brief synopsis to the Editor.
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.



