



Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.jpg)


TABLE OF CONTENT




You have some great data! But is it easily accessible? If not, there is unfortunately no real business value it can drive.
In organisational terms, data accessibility is crucial as it sails beyond getting permission to open a dataset. It’s about how easy it is to find, understand, and trust that data.
So what is data accessibility?
Data Accessibility refers to the scenario where the right people receive the right data at the right time. They also understand its quality, meaning, and context. This helps them use the data effectively.
In a lot of enterprises, though, this accessibility is missing, proving to be a hurdle for analytics and AI. The models in use might be cutting-edge, but if we do not adequately document the data and scatter it without proper lineage, data-driven decision-making becomes slow and leads to a loss of trust. In the case of AI, context-poor and inaccessible data make it practically impossible to deliver scalable solutions. According to IBM, streamlining data management can save engineering teams 90% of their time.
This is a big reason why future-driven organisations are now moving on from ad-hoc requests to accessibility that can be explained and governed at scale. It is directed towards productising data so that it’s discoverable, self-explanatory, and accessible at scale.
If treated as an afterthought, the impact of poor data accessibility trickles through the entire organisation. Teams often work in silos, rebuilding the same pipelines, reports, and transformations without realising it’s already been done elsewhere. Valuable time gets wasted digging through endless documents just to find data that might be usable.
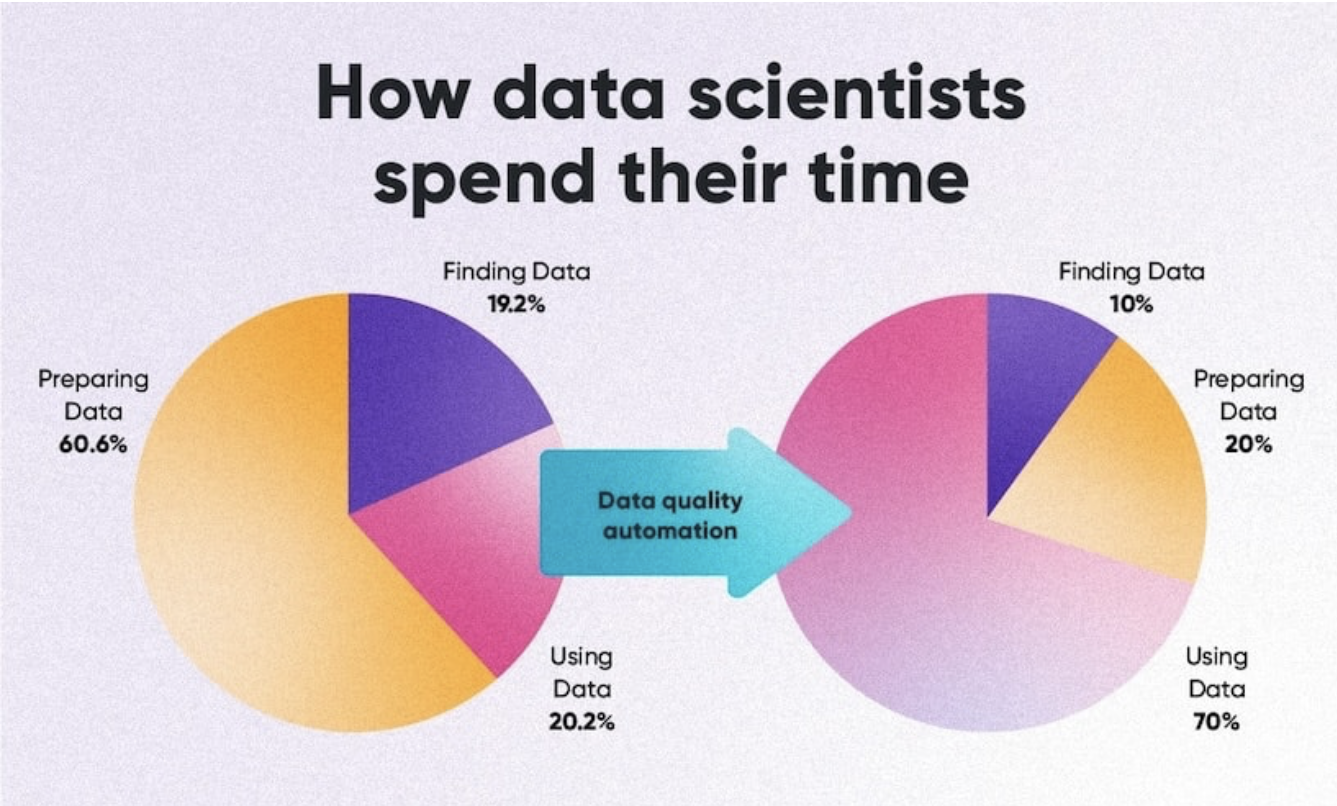
Poor lineage and weak documentation hurt data trust and raise compliance risks, making costly mistakes more likely. Self-service suffers too, as data teams get stuck handling endless requests instead of improving governance. Even basic processes, where teams need to analyse data, become a challenge when analysts spend more time finding the right data, identifying and breaking down siloes, processing data and reconciling fragmented data than actually deriving actionable insights. Self-service suffers too, as data teams get buried under repetitive access requests instead of driving governance and scalability.
For analytics and AI initiatives, things become all the more challenging. The lack of properly governed data accessibility makes explainability difficult, halts experimentation, and also becomes the cause for expensive reworks. This is obvious because when teams can’t understand, discover, and reuse the right data assets, scaling predictive models and AI agents becomes tough.
Given below are seven great strategies to help you in providing better data accessibility in the enterprise setup:
What is metadata? Metadata is the structured context around data, capturing details like origin, usage, lineage, and quality that makes datasets explainable, discoverable, and governed. Without metadata, data is just rows and columns with no trust or meaning.
Incomplete or inconsistent metadata means that data accessibility is compromised right from the start. Without clear freshness indicators, schema details, ownership, or lineage, users lack something solid to rely on. This can cause distrust and misinterpretation. This can be done away with standardising metadata capture right at the source, which means ensuring that each dataset has its own set of quality checks, lineage, schema, usage, and owner notes in check before it enters production.
From a platform point of view, enforcing metadata collection and automation converts raw data into something that acts like a product, where it’s well-governed, documented, and ready for consumption.
Reusability is the highest form of accessibility. Despite that, a lot of teams share SQL snippets or undocumented transformations instead of governed, stable outputs. Instead of this approach, you should package the most valuable datasets, such as curated feature stores, as versioned, immutable products.
A Data Product Approach is useful in this situation. It ensures quality and manages versions. It also provides detailed documentation for each product. The resulting outputs are consistent, on which multiple teams can rely without reinventing too much.
Data discoverability is key here, where analysts should be able to search and assess datasets right from their BI tool, and data scientists should be able to find the feature notes as and when needed easily.
Context becomes key, where usage metrics, tagging and relevancy scores are integrated right into consumption interfaces. On the platform side, this means using integrations and APIs. These tools make the catalog a live part of daily workflows.
Traditional policies can be tricky. They are linked to infrastructure, which makes things messy and disconnected. With evolving roles, these policies are rewritten, leading to frictions and delays. To avoid this, you can create access rules right at the data product level, separating it from the compute or storage layer.
With policy-as-a-code, rules can be assigned easily. Teams require a platform that handles provisioning in the background. The result is more robust data governance, which is more transparent and predictable to ensure that accessibility is granted consistently without any manual involvement.
Without proper understanding, access can be dangerous. When users get a dataset that they don’t understand fully, they could misuse it, misinterpret it, and even violate compliance in the process. This is where surfacing context automatically along every dataset is a great solution.
When you look at a dataset, you can find important details. These include schema definitions, sample queries, quality scores, owner contact information, and freshness scores. Platforms can easily ensure delivery with inline documentation and structured APIs for metadata, so that the usage is safe from day one.
There has to be a priority in place when it comes to making data accessible. All data can’t be granted equal access as all assets share different priorities. This is where data observability tools come to the fore, helping to track freshness, dataset usage, and error rates to determine where the investment would be appropriate.
By looking at usage decay, access patterns, and quality trends, teams can choose which datasets to promote. They can also decide which ones to archive and where to invest to improve discoverability. This will help ensure accessibility efforts focus on areas where they can deliver the maximum value.
Accessibility is a consistent responsibility. Without clearly defined ownership, teams diminish quality, create bad documentation, and lose trust. For this, you should assign domain-specific product owners accountable for the trust, discovery, and relevance of their databases.
The platform should provide support for usage, track SLAs, and ensure quality. It should also offer the right visibility to maintain product awareness over time. It creates a feedback loop, where owners can see how their products are being used, consistently improve accessibility, and quickly respond to issues.
True accessibility means people can access the data they need without waiting for central teams. However, this does not mean that governance goes away. The right balance is achieved when access policies are automated and enforced at the platform level, so users don’t have to think about permissions, while leaders don’t have to worry about risk.
This creates a seamless self-serve experience where accessibility scales safely and consistently. Instead of creating more data requests, teams embed accessibility into their day-to-day workflows.
These seven strategies mentioned above transform accessibility from being just a good-to-have feature to a capability embedded into the data platform itself. Aimed to improve data accessibility in the organisation, these strategies definitely play an essential role in delivering explainable, governed, and scalable accessibility.
A Data Product Platform transforms accessibility by shifting from scattered datasets to reusable, discoverable, and governed data products. These platforms come with built-in metadata, lineage, and access controls, every dataset becomes easily accessible yet fully compliant with policies and security standards. This ensures that business, AI, and data teams work from a unified access layer, reducing friction and enabling seamless collaboration.
The platform combines data integrations and policy enforcement in one place. This cuts down on extra infrastructure costs. It also makes sure that trusted, high-quality data is used consistently across different areas.
This creates a safe and governed base for AI, analytics, and decision-making. Here, teams find easy access to data, which is ready for business use.
💡 Related Reads:
Metrics-Focused Data Strategy with Model-First Data Products
Data accessibility can be changed into golden paths. These paths make sure data is used with the right context, governance, and safety. In the AI era, the foundation has to be data that is governed, trusted, and explainable.
That’s why accessibility should be treated as a core feature, not a side fix. When it is part of both the platform and the culture, teams can work confidently. They can experiment safely, innovate quickly, and scale AI without losing trust or control.
Data accessibility is more than just opening new paths. It is about allowing safe and governed use of datasets in context. Ensuring proper accessibility ensures that data is not just reachable, but also trusted, explainable, and aligned with all compliance needs.
We live in the age of AI, and here, only governed, trusted, and explainable data is the foundation. This is a big reason why accessibility needs to be treated as a core feature, and not just some secondary UX fix.
With these principles embedded deep into the organisational platform and culture, teams are enabled to experiment safely, innovate quickly, and scale AI with a lot of confidence.
Q1. How does poor data accessibility impact organisational AI initiatives?
Poor data accessibility complicates explainability, slows down experimentation pace, and increases rework. To work reliably, AI models require high-quality, context-rich, and governed data. Accessibility, for this reason, has become a key element in the modern data stack as well.
Q2. How can organisations ensure effective data handling?
By treating data as products with clear ownership, access controls, and usage visibility. A Data Product Platform sets rules, checks quality, and gathers feedback. This keeps data trusted, easy to find, and simple to use for all teams.
Q3. What could be the most crucial step in ensuring data accessibility?
Instead of treating data as a byproduct, it should be treated as a product. It entails standardising metadata, embedding governance, data discovery, and observability into the platform.
Join the Global Community of 10K+ Data Product Leaders, Practitioners, and Customers!
Connect with a global community of data experts to share and learn about data products, data platforms, and all things modern data! Subscribe to moderndata101.com for a host of other resources on Data Product management and more!
.avif)
📒 A Customisable Copy of the Data Product Playbook ↗️
🎬 Tune in to the Weekly Newsletter from Industry Experts ↗️
♼ Quarterly State of Data Products ↗️
🗞️ A Dedicated Feed for All Things Data ↗️
📖 End-to-End Modules with Actionable Insights ↗️
*Managed by the team at Modern
Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


