




Access full report
Oops! Something went wrong while submitting the form.

🤍

Facilitated by The Modern Data Company in collaboration with the Modern Data 101 Community
Latest reads...

.png)

.jpg)


TABLE OF CONTENT


.avif)

Last week, while riding my bike through the countryside (a good way to clear the head and wrap up loose thoughts), an old problem came back with new clarity. We talk a lot about testing data pipelines, but very little about the quality of the test data we use.
Somewhere in between the winding roads, a new idea took shape: an open-source tool we might call reverse sampling.
Here’s the setup: Testing data pipelines isn’t just about having some data. It’s about having the right data. And more often than we admit, we get this part wrong.
Modern pipelines are layered: joins on joins, filters stacked with aggregations, time-based constraints baked in. When we sample input datasets natively, the pipeline doesn’t throw an error. It just runs clean and outputs almost no realistic bugs. Which is worse, because now we’re staring at a green checkmark and assuming all is well.
What we need is a smarter way to generate test data. One that starts from the end state, a known, production-like output, and works backwards to identify the minimal, valid inputs that would produce it. That’s where the idea of reverse sampling begins.
Most data engineers don’t think twice before sampling. They grab a few thousand rows, run the pipeline, and move on. But that kind of surface-level approach breaks fast when you’re working with real pipelines. Not toy DAGs, but the kind that sprawl across multiple layers of joins, filters, and time-based logic.
Here’s a familiar scenario: you're filtering for events from the last 15 minutes, but your sample was randomly pulled from five years of historical data. The chances of anything making it through that filter are close to zero. The pipeline doesn’t crash. It just gives you... nothing.
Now you're stuck. The test runs clean, no alerts are triggered, but you're blind. You've wasted hours debugging the wrong thing or assumed the pipeline works because it’s silent. Translate this to scale: a batch of pipelines in testing. This is the quiet failure mode of traditional sampling, and it's a productivity trap most teams walk into without realising it.
Most sampling strategies start from the input: take a random subset, maybe apply a few filters, and hope it’s good enough. But what if we flipped the process? What if we started with the output we wanted and worked backwards to figure out what input data could have produced it?
That’s the core idea behind Reverse Sampling. Instead of pushing random inputs through the pipeline and praying for non-empty results, we begin with a known-good output: production-like data that reflects what we expect to see downstream. Then, we trace the lineage of that output through each step of the pipeline. Join by join. Filter by filter.
Case: Say we’re dealing with a pipeline that joins order events to product details, applies business logic, and filters for events in the last 15 minutes.
Traditional sampling might randomly select a few thousand rows from five years of order data and a few hundred from the product table. But if the sampled orders don’t happen to fall in the last 15 minutes, or the product IDs don’t overlap, the join yields nothing. Downstream logic has nothing to work with. The test passes. The data disappears.
Now take the same case, but with reverse sampling. We start with a few real records from the production output. Orders we know passed through the filters and joins. We extract the product IDs, timestamps, customer segments; everything that contributed to those rows.
Then, we walk backwards through the SQL or dataframes to identify the minimal viable inputs: the exact order rows, the matching product entries, the correlated data that preserves the integrity of the pipeline.
By tracing from output to input, reverse sampling ensures that the sample isn’t just
At its core, reverse sampling is about treating the pipeline as a graph, and walking it backwards: from output to source. Reverse sampling is a methodical walk backward through your pipeline to reconstruct the minimal input needed to produce a meaningful test output.
📝 Reading Recommendations
Right-to-Left Data Engineering ↗️
Model-First Data Products ↗️
Here's how it would work, step by step:
This approach guarantees that every test you run has referential integrity, meaningful filter matches, and accurate aggregations, without copying the entire production dataset.
where each output has precise and independent transformation lineage due to right-to-left data engineering (developing pipelines backwards: model-first instead of pipeline-first), implementing reverse sampling becomes easier. Tracing output columns back through the pipeline is not a time-suicide mission, but the norm and time-effective.
Reverse Pipeline Development Sequence (Model-First) = Easier Reverse-Pipeline Testing/Data Sampling Sequence
Here’s a glimpse of reverse development for reference. For a thorough analysis, check out How Data Becomes Product.
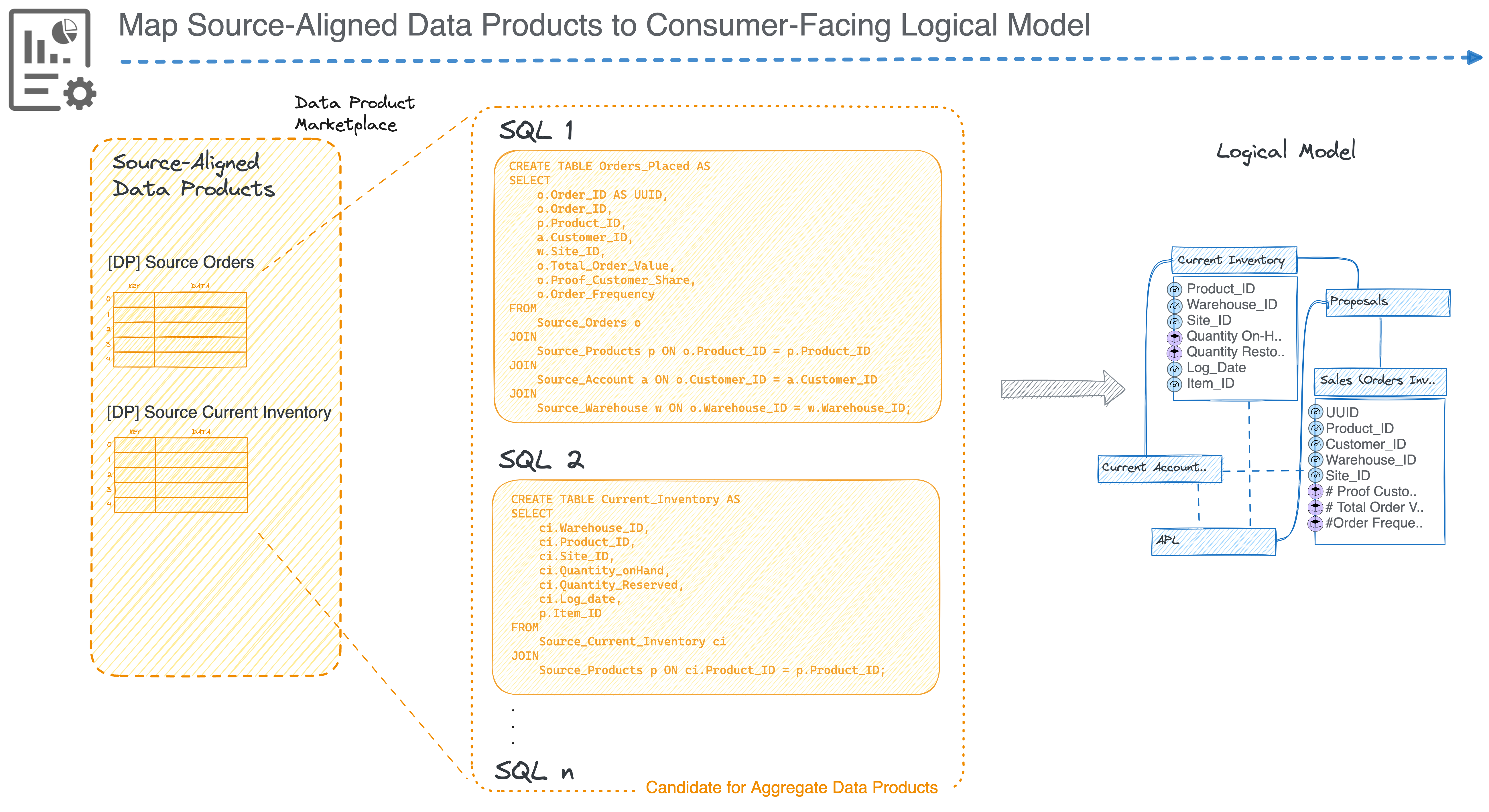
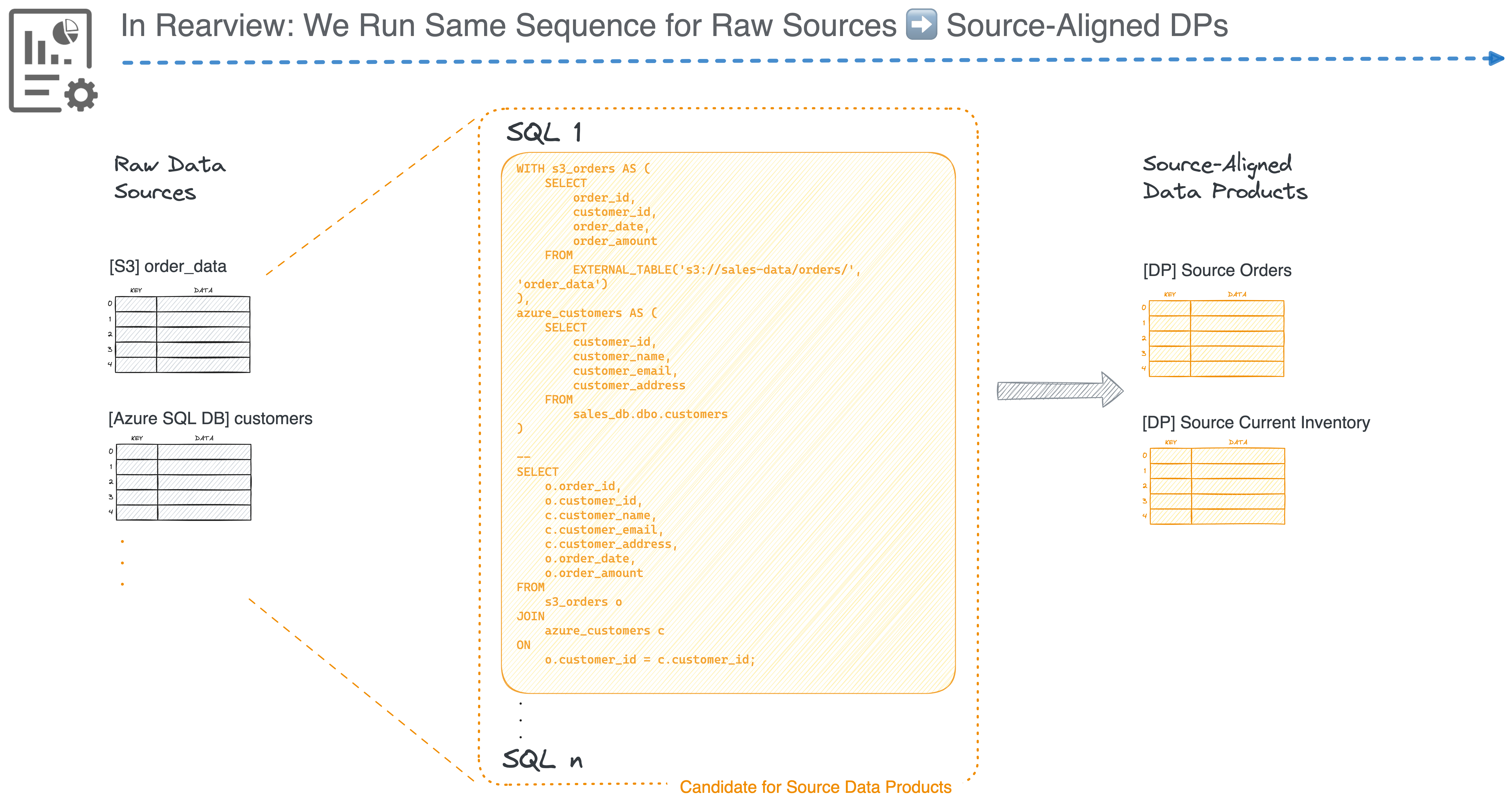
This section is to explore the art of possibility; ideas and open spaces ripe for innovation.
The steps above outline the logic behind reverse sampling, but you shouldn’t have to do them manually. That’s where the idea of Mock Data as a Service (MDaaS) comes in.
Instead of reverse-engineering constraints by hand, a well-designed MDaaS layer can automate the entire trace, from output to input. Given a production-like sample and your pipeline logic (SQL or dataframe-based), the service can:
What you get is a test-ready dataset that flows through your pipeline and behaves exactly as it would in prod, without copying sensitive data, and without long dev cycles spent chasing missing rows.
Reverse sampling becomes not just a clever technique, but a plug-and-play capability. One that scales with every pipeline you build. One that frees data engineers from brittle, guess-based mocks and opens the door to real test confidence.
References:
Prototype valiation using mock data ↗️
Why generating data for testing is surprisingly challenging ↗️
What if this wasn’t just an internal trick or an abstract method, but a tool anyone could use?
Reverse sampling reveals a real gap in the modern data tooling landscape: there’s no standard way to simulate realistic, minimal, test-safe datasets that mirror production behaviour. So, the natural next step is building an open-source tool that makes this a default capability.
This tool would:
Rather than generating fake data from arbitrary schemas, it would simulate valid paths through the actual logic of your pipeline. The focus isn’t on randomness or volume, it’s on fidelity to the real data flow.
By being open source, it could plug into any orchestration stack, CI pipeline, or data platform. It could work alongside dbt, Airflow, or Spark. And over time, it could learn from patterns across pipelines, optimising how sampling constraints are inferred.
This isn’t just a tool for test data. It’s a missing layer in the modern data developer stack, one that treats pipelines as living systems and testing as a first-class citizen.
*Excerpt from AI Augmentation to Scale Data Products (Modern Data 101 Archives)

Generating mock data streams for validating data product prototypes can be a cumbersome task due to the complexity and low-level nuances of domain-specific data. But AI attempts to make it a cakewalk today.
Let’s assume you are on the operations team in the moving enterprise and want to build a data product, say, ‘Route Efficiency Optimiser.’ The image depicts the general flow of using NLP to generate synthetic data, followed by powering this flow to generate real-time mock data streams.
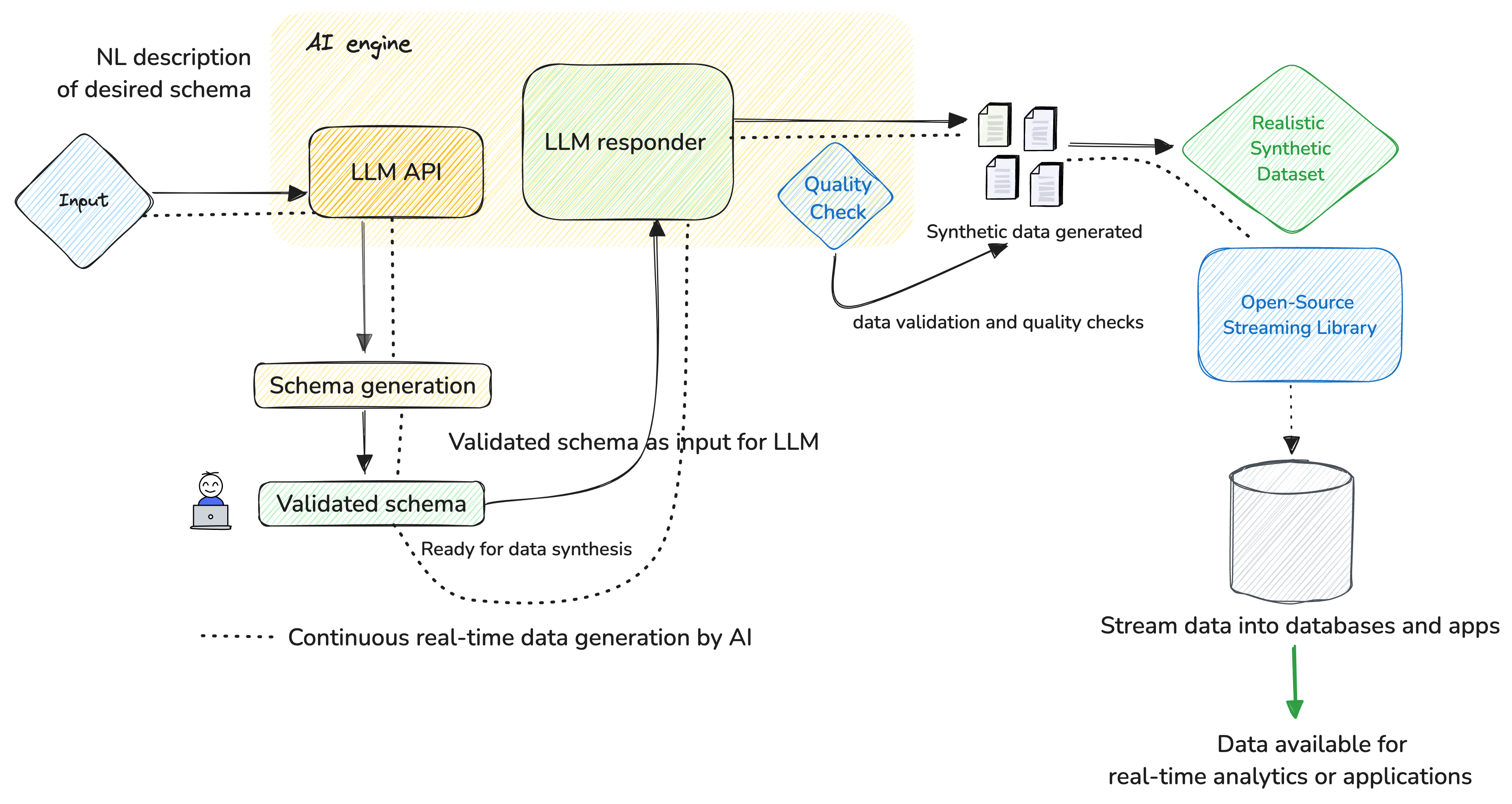
A schema for a logistics dataset might include columns like Route ID, Vehicle ID, Start Location, End Location, Distance, Travel Time, Delivery Volume, Delivery Time Windows, Cost, etc.
AI can interpret this schema and generate the appropriate data types, such as:
AI can then analyse this data to identify patterns, optimise routes, and improve overall route efficiency. AI can handle more complex structures, such as nested JSON objects or arrays, which are common in real-world data scenarios.
An AI engine also enables finding relationships between data assets, such as tables or other entities, that can be joined for a data product. The process of schema generation is equally aided by AI in both stages of creating mock data as well as while dealing with the real data.
Once the schema is defined, AI can generate synthetic data that mimics real-world data patterns. This includes:
Using APIs to send prompts and receive generated schemas. For example, integrating with OpenAI's API allows for seamless schema creation. OpenAI's GPT-4 or similar LLMs. AI can generate real-time mock data streams, which are essential for testing event-driven architectures and real-time analytics platforms. This is particularly useful for applications like real-time personalisation, fraud detection, and dynamic inventory management.
As of today, a lot of data engineers just copy production data in test environments, because they do not know (or have no time/bandwidth for) how to sample input datasets properly. That leads to inefficiencies, both in processing times and costs, for the least. Potentially to security risks too. A "reverse sampling" tool, therefore, would be very beneficial to a lot of people.
This is a tool that understands how data flows through pipelines. One that doesn’t just sample blindly, but does so with context: automatically tracing the transformations, filters, joins, and time windows that shape the final output.
With Data Products in the picture that binds the context of data, metadata, and transform logic, tapping into this context for a reverse sampling platform module is even easier. (Refer: Image below).
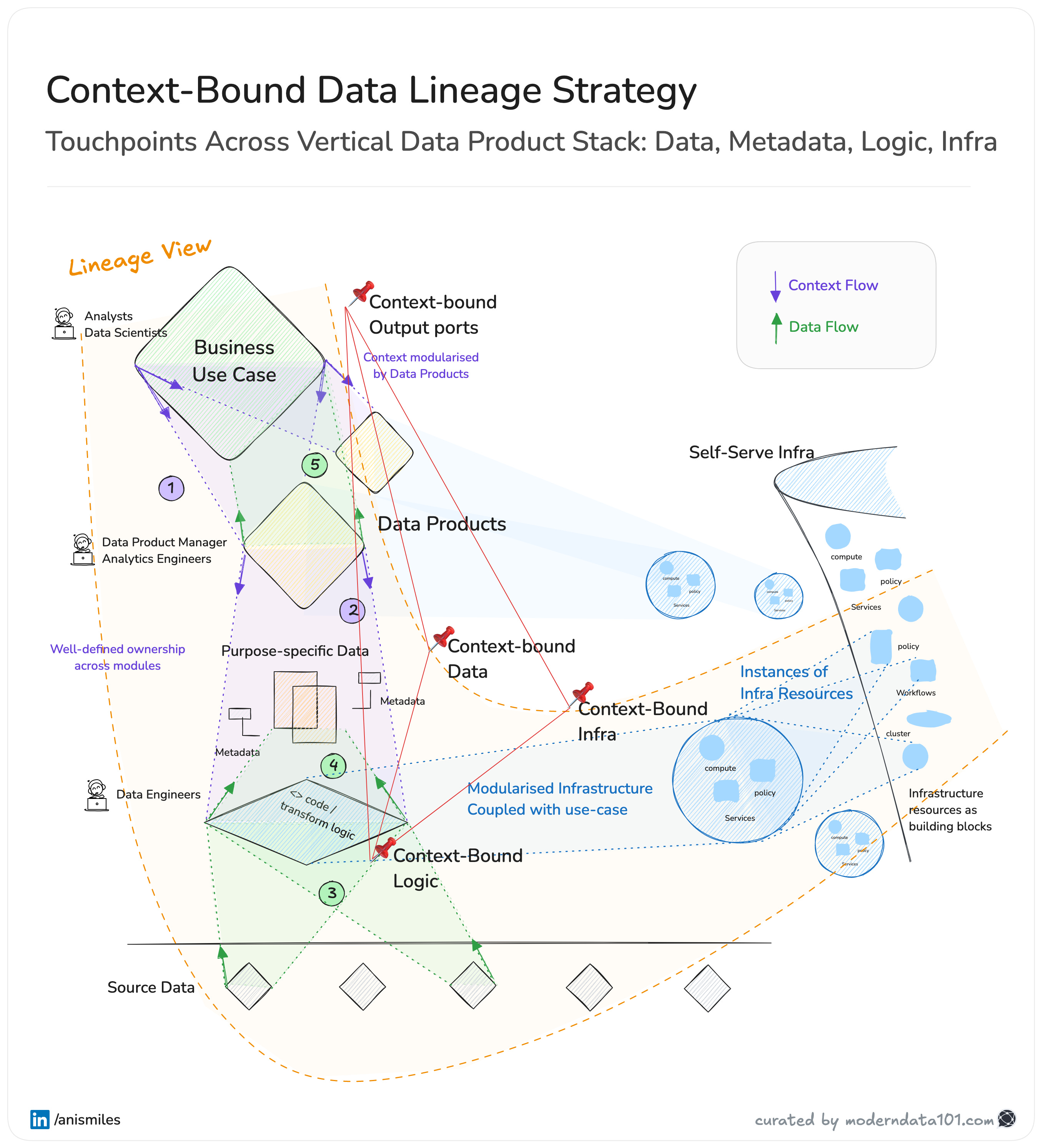
Reverse sampling gives us the methodology. An open-source tool makes it accessible. It would lower the barrier to accurate, lightweight testing. Replace tribal knowledge with repeatable patterns. And let developers move faster without sacrificing confidence.
Thanks for reading Modern Data 101! Subscribe for free to receive new posts and support our work.
If you have any queries about the piece, feel free to connect with the author(s). Or feel free to connect with the MD101 team directly at community@moderndata101.com 🧡

The Modern Data Survey Report is dropping soon; join the waitlist here.

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →

Your Copy of the Modern Data Survey Report
Better decisions start with shared insight.
Pass it along to your team →




Find more community resources
Modern Data 101 is a movement redefining how the world thinks about data. A community built by the same team behind the world’s first data operating system, Modern Data 101 sits at the intersection of data, product thinking, and AI. Spread across 150+ countries, the community brings together a global network of practitioners, architects, and leaders who are actively building the next generation of data systems.
At its core, Modern Data 101 exists to simplify the journey from raw data to tangible and observable impact. It advocates high-potential data systems and next-gen architectures to unify and activate insights and automation across analytics, applications, and operational workflows at the edge.
In a world shifting from data stacks to AI ecosystems, Modern Data 101 helps teams not just navigate the change but lead it.

Find all things data products, be it strategy, implementation, or a directory of top data product experts & their insights to learn from.
Connect with the minds shaping the future of data. Modern Data 101 is your gateway to share ideas and build relationships that drive innovation.
Showcase your expertise and stand out in a community of like-minded professionals. Share your journey, insights, and solutions with peers and industry leaders.


